Pandas库的使用--Series
一。概念
Series相当于一维数组。
1.调用Series的原生方法创建
import pandas as pd s1 = pd.Series(data=[1,2,4,6,7],index=['a','b','c','d','e'])# index表示索引
print(s1['a'])
print(s1[0])
print(s1[:3])# 在Series中切片是一个闭合区间表示Series中0-3的元素
print(s1['a':'d']) # 范围是一个闭合
print(s1[['a','d']]) #用逗号隔开,表示分别取这两个元素 注意 这里用两个中括号括起来


2.使用字典生成Series
sdata = {'beijing':45000, 'shanghai':71000, 'guangzhou':16000, 'shengzheng':5000}
obj3 = Series(sdata)
print(obj3)
print("-"*40)

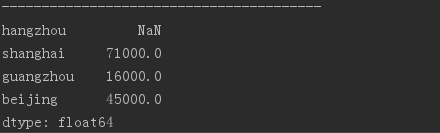
states = ['hangzhou', 'shanghai', 'guangzhou','beijing']
obj4 = Series(sdata, index = states) # 索引重置 使用字典生成Series,并额外指定index,不匹配部分为NaN。
print(obj4)
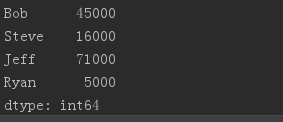
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan']
print(obj)
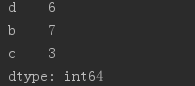
#Series相加,相同索引部分相加。不相同的索引部分为NaN
print(obj3 + obj4)
二。Series的相关特性及函数
from pandas import Series #用数组生成Series ,默认情况下使用数字索引
obj = Series([4, 7, -5, 3])
print(obj)

print(obj.values)
print(obj.index)
print(obj.shape,obj.ndim) # 这里 shape表示每一个维度的数量, ndim表示的是维度
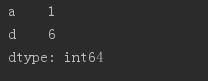
obj2 = Series([4, 7, -5, 3], index = ['d', 'b', 'a', 'c']) print(obj2.index)
print(obj2['a'])
obj2['d']=6 #替换Series中的元素
print(obj2)
# print(obj2[:3]) # 数字的下标还存在,也可以分片
# print(obj2[['c', 'a', 'd']]) #获取索引a,c,d的值
# print(obj2[obj2 > 0]) # 找出大于0的元素

# print('b' in obj2) # 判断索引是否存在
# print('e' in obj2)
# print("-"*40)
# # #指定Series及其索引的名字obj4.name = '我定义的名字'obj4.index.name = 'index'print(obj4)
持续更新中。。。。,欢迎大家关注我的公众号LHWorld.

Pandas库的使用--Series的更多相关文章
- pandas库学习笔记(二)DataFrame入门学习
Pandas基本介绍——DataFrame入门学习 前篇文章中,小生初步介绍pandas库中的Series结构的创建与运算,今天小生继续“死磕自己”为大家介绍pandas库的另一种最为常见的数据结构D ...
- 第三周 数据分析之概要 Pandas库入门
Pandas库介绍: Pandas库引用:Pandas是Python第三方库,提供高性能易用数据类型和分析工具 import pandas as pd Pandas基于NumPy实现,常与NumPy和 ...
- Python的Pandas库简述
pandas 是 python 的数据分析处理库import pandas as pd 1.读取CSV.TXT文件 foodinfo = pd.read_csv("pandas_study. ...
- pandas库的数据类型运算
pandas库的数据类型运算 算数运算法则 根据行列索引,补齐运算(不同索引不运算,行列索引相同才运算),默认产生浮点数 补齐时默认填充NaN空值 二维和一维,一维和0维之间采用广播运算(低维元素与每 ...
- 数据分析与展示---Pandas库入门
简介 一:Pandas库的介绍 二:Pandas库的Series类型 (一)索引 (1)自动索引 (2)自定义索引 (二)Series类型创建 (1)列表创建 (2)标量值创建 (3)字典类型创建(将 ...
- 使用第三方库连接MySql数据库:PyMysql库和Pandas库
使用PyMysql库和Pandas库链接Mysql 1 系统环境 系统版本:Win10 64位 Mysql版本: 8.0.15 MySQL Community Server - GPL pymysql ...
- Pandas库入门
pandas库的series类型
- Python的工具包[1] -> pandas数据预处理 -> pandas 库及使用总结
pandas数据预处理 / pandas data pre-processing 目录 关于 pandas pandas 库 pandas 基本操作 pandas 计算 pandas 的 Series ...
- Python之Pandas库常用函数大全(含注释)
前言:本博文摘抄自中国慕课大学上的课程<Python数据分析与展示>,推荐刚入门的同学去学习,这是非常好的入门视频. 继续一个新的库,Pandas库.Pandas库围绕Series类型和D ...
随机推荐
- Linux基础学习笔记以及常用命令
1.windows自带命令进入mysql所在磁盘 2.进入mysql安装目录的bin文件 D:\>cd D:\Program Files (x86)\mysql-5.5.25-winx64\ ...
- oralce11g导出dmp然后导入Oracle10g
一次Oracle11g数据库导入 Oracle10g数据库操作笔记 11g备份导入10g的时候会抛错直接阻止导入. 但是有时候还必须得把11g的数据库导入到10g我今天就遇到了这种情况. 一开始 ...
- 【Hdu3652】B-number(数位DP)
Description 题目大意:求小于n是13的倍数且含有'13'的数的个数. (1 <= n <= 1000000000) Solution 数位DP,题目需要包含13,且被13整除, ...
- Android View动画效果—透明效果,旋转效果(二)
一:动画效果 方法一:动画效果用AlphaAnimation类.直接加入 AlphaAnimation aa = new AlphaAnimation(0,1); //设置透明度 aa.setDura ...
- Android DVM
1.DVM(Dalvik Virtual Machine)概述 是Google公司自己设计用于Android平台的Java虚拟机 支持已经转化为.dex(及Dalvik Excutable)格式的Ja ...
- linux下使用自带mail发送邮件(超简单)
linux 发邮件最简单的办法 ,也可以使用公司邮箱,需要安装mailx工具,mailx是一个小型的邮件发送程序. 具体步骤如下: 1.安装 [root@001 ~]# yum install mai ...
- 转:java单例设计模式
本文转自:http://www.cnblogs.com/yinxiaoqiexuxing/p/5605338.html 单例设计模式 Singleton是一种创建型模式,指某个类采用Singleton ...
- 自学Zabbix3.5.3-监控项item-key
1. 温习 Zabbix server是Zabbix软件的中心进程. Server执行polling和trapping来采集数据,评估是否触发触发器,发送报警给用户.它是Zabbix agent和pr ...
- 自学Zabbix3.5.1-监控项item-key详解
自学Zabbix3.5.1-监控项item-key详解个人觉得艰难理解,故附上原文档:https://www.zabbix.com/documentation/3.0/manual/config/it ...
- NanUI 0.4.4发布
NanUI是一个基于ChromiumFX开源项目的.Net Winform界面库,ChromiumFX是Chromium Embedded Framework的.Net实现.众所周知,Chromium ...