虚拟机下 solr7.1 cloud 集群搭建 (手动解压和官方脚本两种方式)
准备工作:
vmware workstation 12,OS使用的是ubuntu16.04,三台虚拟机搭建一个solr集群,zookeeper共用这三台虚拟机组成zookeeper集群。
zookeeper的版本为3.4.10,solr版本为7.1,不使用tomcat,使用solr自带的jetty。jdk版本为1.8.0_151。
第一步:虚拟机的建立
选择默认配置即可,内存我配置的2G一台,1CPU,网络采用NAT,DHCP自动分配。建好一台虚拟机后,我们可以去配置一些基本环境,如Jdk等,然后使用克隆的方式,减少一些不必要的操作。
基本配置也就是安装openssh-server,jdk等常用环境即可。
安装完成的结果如下。

图1 安装完成后xshell下远程连接的界面
第二步:zookeeper集群环境搭建
下载zookeeper3.4.10,我把zookeeper解压到了登录用户(我的用户是solr)的根目录下(我的是/home/solr/zookeeper-3.4.10),实际可根据需求自行放置在相应的目录下即可。
随后我们进入zookeeper下conf目录,复制一份cfg文件,并进行配置。
cd /zookeeper-3.4./conf # 进入zookeeper config目录
cp zoo_sample.cfg zoo.cfg # 复制一份配置文件,并修改内容
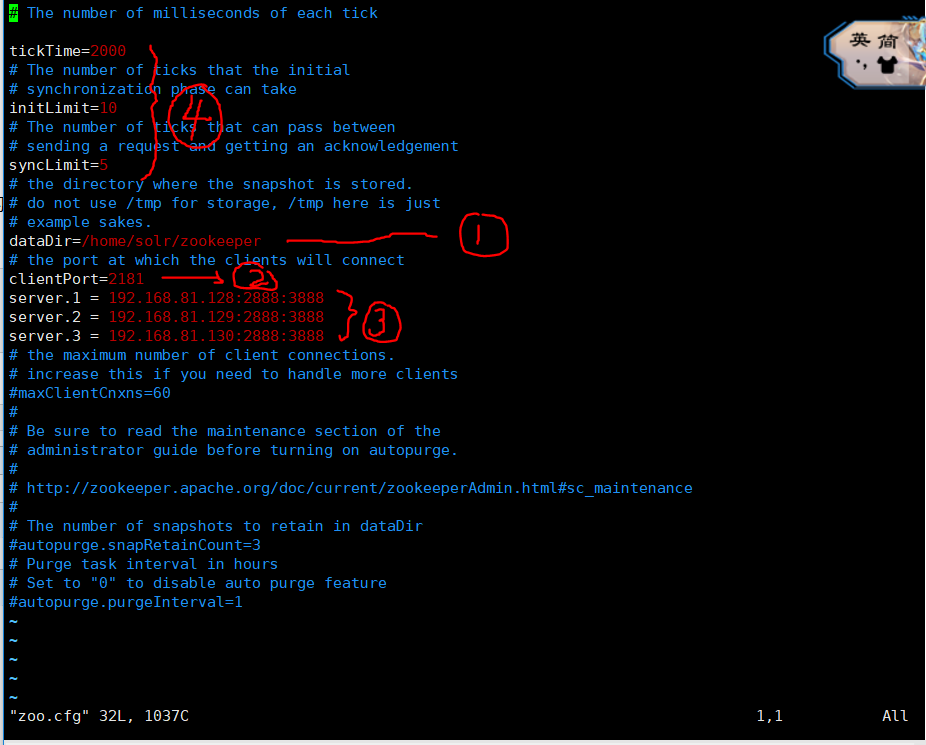 图2 zoo.cfg配置文件
图2 zoo.cfg配置文件
对上述1.2.3.4进行说明:
- zookeeper的数据存放的地方(我的理解),我这里为了方便配置在Home目录下,实际可根据需求进行配置
- zookeeper的端口
- zookeeper集群的设置,2888和3888分别是监听和投票选举端口,server.1 server.2 server.3后续进行说明
- 是一些配置参数,比如触发事件什么,请自行百度了解相关意思。
server.1 server.2 server.3 说明的是集群中其他zookeeper的"代号",server.后的数字的范围为1~255
这个数字在刚才配置文件目录(如上述的/home/solr/zookeeper)下新建一个myid文件,里面填写这些数字来标识身份即可,比如server.1所在的服务器的zookeeper目录下就应该有一个myid文件,内容为1。
./zkServer.sh start # 启动zookeeper
启动zookeeper查看状态可以看到如下内容,说明zookeeper集群搭建成功。

图3 zookeeper follwer 状态

图4 zookeeper leader 状态
第三步 solr集群的搭建(按照官方按照脚本来进行配置)
在这里,我们先用官方的文档中的脚本来进行安装,将solr安装为系统中的一个服务。
tar xzf solr-7.1..tgz solr-7.1./bin/install_solr_service.sh --strip-components= # 将脚本文件从包中解压出来 sudo bash ./install_solr_service.sh solr-7.1..tgz # 进行安装solr
在这种情况下,solr会默认安装在/opt/solr-7.1.0/下,同时会自动建立一个/opt/solr 去链接/opt/solr-7.1.0,这是为了方便后续更新solr版本是,只要更换/opt/solr-7.1.0文件即可。
同时,默认情况下,会将一些配置文件放置在/var/solr中,后续我们会用到该文件夹。
同时,如果不存在用户solr,会自动新建一个solr用户,最后,该脚本会自动启动solr。
上述的命令采用的是默认安装的情况,实际条件我们可以进行一些自己的配置。
- -d solr的一些参数和可写的文件存放的位置,默认为/var/solr
- -i solr的解压位置,默认为/opt/下
- -p solr绑定的端口,默认为8983
- -s service的名称
- -u 对应的用户的名称,默认为solr
- -n 这个参数说明执行完成后不启动solr
在执行完脚本后,我们就可以用 sudo service solr [start|restart|stop|status] 等命令来控制solr。
但是在上述情况下,我们并没有配置solr和zookeeper之间的关系,所以启动后不会是cloud模式,随后,我们来配置solr。
首先,进入/var/solr/data 目录,修改solr.xml文件。
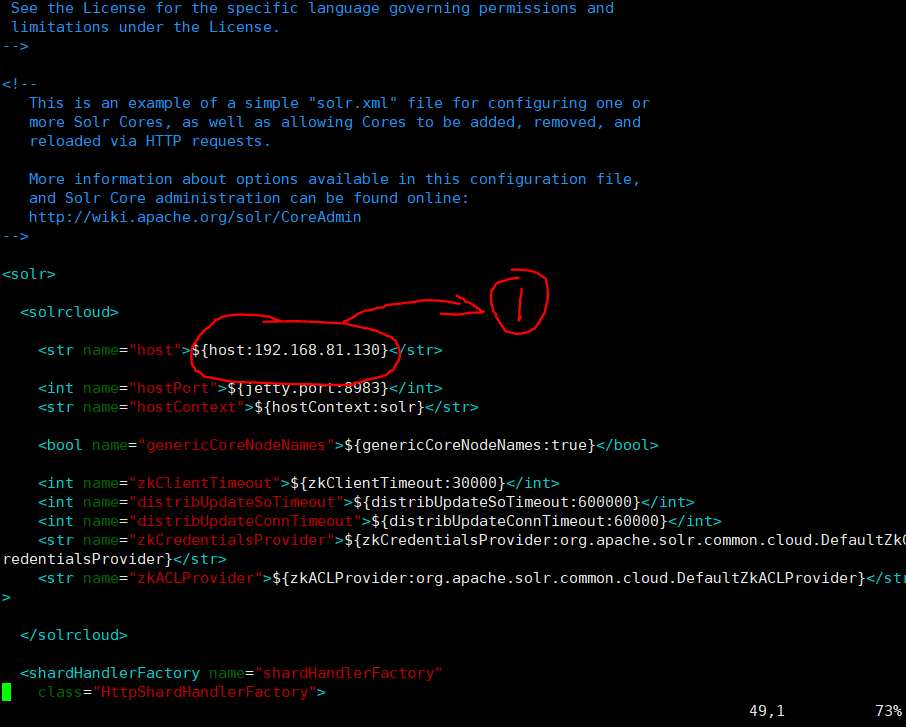
图5 solr.xml 配置文件
在这里,我们主要配置host这个参数,将host:后面填入虚拟机对应的IP,否则搭建集群的时候,cloud会显示localhost,会引发错误。
随后,安装脚本在默认情况下,会在/etc/default/下生成一个solr.in.sh文件,我们要修改这个文件,配置zk_Host参数(也就是zookeeper的参数)。
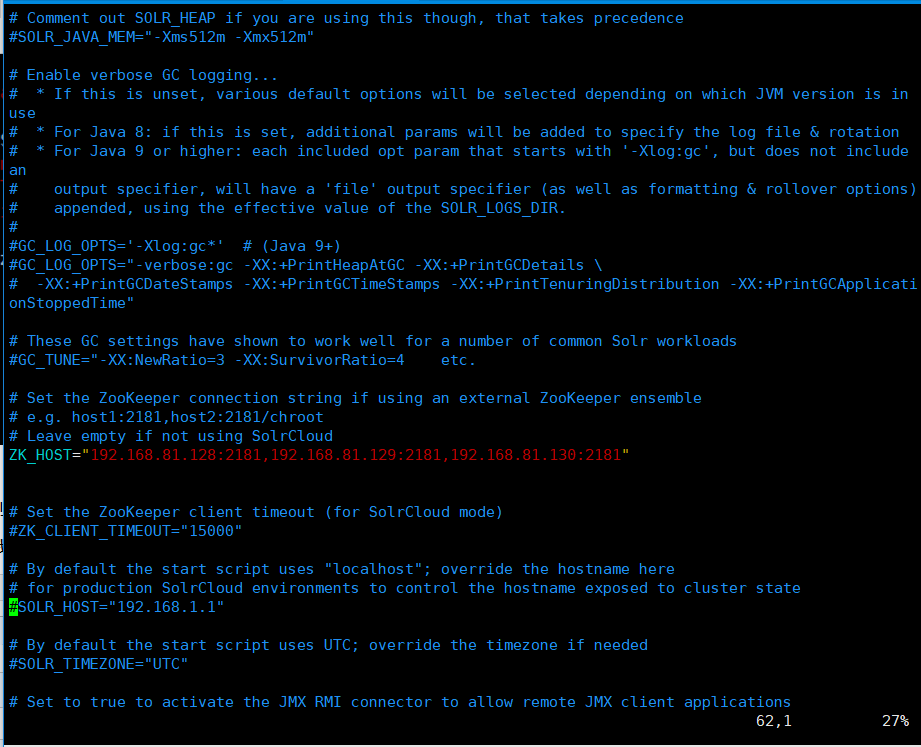
图6 solr.in.sh 配置文件
这个配置文件还有其他很多的参数,读者可以自行去查看是如何意思,我在这里只配置了zk_host,其他都采用默认设置
zk_host 说明了zookeeper集群的位置,可以看出来,这就是我们第一步配置的zookeeper的集群中所以节点的地址。
配置完成后,我们就可以启动solr。
第四步,基础操作
首先我们应该用zookeeper上传一份我们自己的配置文件,放置在我们的zookeeper集群中。
root@ubuntu:/opt/solr-7.1./bin# ./solr zk upconfig -d [要上传的配置文件目录] -n [zookeeper上保存的配置文件名称] -z [zookeeper的集群地址]
很多教程中用的是cloud_scripts/下的zkcli.sh。实际上都是一样的,看自己的喜好,这个文件在zookeeper下也有,可以用help来看看参数说明。
上传之后,我们在新建一个集合,用我们刚才上传的配置文件,如果不指定,就会使用默认的配置文件
root@ubuntu:/opt/solr-7.1./bin# ./solr create-collection -c [新建集合的名字] -n [zookeeper上配置文件的名称,上一步设置的那个n] -shards [分两块] -replicationFactor [replic数量]
我们进入solr-cloud,就可以看到我们新建的集合,也可以看到我们solr-cloud集群已经搭载成功。

图7 solr-cloud
第五步 直接解压solr的配置说明
其他配置和官方脚本安装都一样,核心问题就是配置文件的位置不一样,需要特别说明。
solr.xml在解压后根目录下server/solr 下
solr.in.sh 在根目录下的bin/下
启动命令要使用 -cloud -z 参数,具体请参考官方文档。
虚拟机下 solr7.1 cloud 集群搭建 (手动解压和官方脚本两种方式)的更多相关文章
- Linux下MySQL/MariaDB Galera集群搭建过程【转】
MariaDB介绍 MariaDB是开源社区维护的一个MySQL分支,由MySQL的创始人Michael Widenius主导开发,采用GPL授权许可证. MariaDB的目的是完全兼容MySQL,包 ...
- MySQL集群搭建详解
概述 MySQL Cluster 是MySQL 适合于分布式计算环境的高实用.可拓展.高性能.高冗余版本,其研发设计的初衷就是要满足许多行业里的最严酷应用要求,这些应用中经常要求数据库运行的可靠性要达 ...
- centos下hadoop2.6.0集群搭建详细过程
一 .centos集群环境配置 1.创建一个namenode节点,5个datanode节点 主机名 IP namenodezsw 192.168.129.158 datanode1zsw 192.16 ...
- (2)虚拟机下hadoop1.1.2集群环境搭建
hadoop集群环境的搭建和单机版的搭建差点儿相同,就是多了一些文件的配置操作. 一.3台主机的hostname改动和IP地址绑定 注意:以下的操作我都是使用root权限进行! (1)3太主机的基本网 ...
- vmware10上三台虚拟机的Hadoop2.5.1集群搭建
由于官方版本的Hadoop是32位,若在64位Linux上安装,则必须先重新在64位环境下编译Hadoop源代码.本环境采用编译后的hadoop2.5.1 . 安装参考博客: 1 http://www ...
- Linux下MySQL/MariaDB Galera集群搭建过程
MariaDB介绍 MariaDB是开源社区维护的一个MySQL分支,由MySQL的创始人Michael Widenius主导开发,采用GPL授权许可证. MariaDB的目的是完全兼容MySQL,包 ...
- Ubuntu 12.04下spark1.0.0 集群搭建(原创)
spark1.0.0新版本的于2014-05-30正式发布啦,新的spark版本带来了很多新的特性,提供了更好的API支持,spark1.0.0增加了Spark SQL组件,增强了标准库(ML.str ...
- Debian下Hadoop 3.12 集群搭建
Debian系统配置 我这里在Vmware里面虚拟4个Debian系统,一个master,三个solver.hostname分别是master.solver1.solver2.solver3.对了,下 ...
- Flume NG高可用集群搭建详解
.Flume NG简述 Flume NG是一个分布式,高可用,可靠的系统,它能将不同的海量数据收集,移动并存储到一个数据存储系统中.轻量,配置简单,适用于各种日志收集,并支持 Failover和负载均 ...
随机推荐
- H5前端上传文件的几个解决方案
目前,几个项目中用到了不同的方法,总结一下分享出来. 第一种,通过FormData来实现. 首先,添加input控件file. <input type="file" name ...
- JAVA提高九:集合体系
在经过了前面的JDK6.0新特性的学习后,将进一步深入学习JDK,因为集合的重要性,因此从集合开始入手分析: 一.集合概况 Java是一种面向对象语言,如果我们要针对多个对象进行操作,那么首先必要将多 ...
- BigDecimal与Long之间的转换
新建了一个class类 取名叫Firut import java.math.BigDecimal; public class Firut { private String id; private Bi ...
- 链表倒数第n个节点
找到单链表倒数第n个节点,保证链表中节点的最少数量为n. 样例 给出链表 3->2->1->5->null和n = 2,返回倒数第二个节点的值1. /** * Definiti ...
- scanf和cin性能的比较
我的实验机器配置是: 处理器:Intel(R) Core(TM) i3-7100U CPU @ 2.40GHz 2.40GHz 随机访问存储器:4.00GB 操作系统:Windows10 集成开发环境 ...
- 虚拟软件vmware安装
什么是虚拟软件: 虚拟原件是一个可以使你在一台机器上同时运行二个或更多Windows.LINUX等系统.它可以模拟一个标准PC环境.这个环境和真实的计算机一样,都有芯片组.CPU.内存.显卡.声卡.网 ...
- ldap数据库--ODSEE--ACI
查看跟DN下的aci ldapsearch -h hostname -p port -D "cn=Directory Manager" -w - -b "BASE_DN& ...
- C# Ioc容器Unity,简单实用
开头先吐槽一下博客园超级不好用,添加图片后就写不动字了,难道是bug 好进入正题,先来说下依赖注入,简单来说就是定义好接口,上层代码调用接口,具体实现通过配置文件方式去指定具体实现类. 首先我们需要通 ...
- jQuery学习笔记之Ajax用法详解
这篇文章主要介绍了jQuery学习笔记之Ajax用法,结合实例形式较为详细的分析总结了jQuery中ajax的相关使用技巧,包括ajax请求.载入.处理.传递等,需要的朋友可以参考下 本文实例讲述了j ...
- JDBC之代码优化
上一次我们是先实现了JDBC对数据库的增删查改操作,然后在增加新信息过程中发现了新的问题,即当某一操作失败,为了维护数据库的一致性,我们需要回滚事务.在其中我们了解了事务的工作原理及相关代码的使用. ...