实验:ignite查询效率探究
前面的文章讲到ignite支持扫描查询和sql查询,其sql查询是ignite产品的一个亮点,那么哪一种的查询更适合我们的产品使用呢,往下看:
先分别贴一下扫描查询和sql查询两种查询方式的代码,供参考:
扫描方式:
IgniteCache<Long, Person> cache = ignite.cache("mycache");
// Find only persons earning more than 1,000.
IgniteBiPredicate<Long, Person> filter = new IgniteBiPredicate<>() {
@Override public boolean apply(Long key, Perons p) {
return p.getSalary() > 1000;
}
};
try (QueryCursor cursor = cache.query(new ScanQuery(filter)) {
for (Person p : cursor)
System.out.println(p.toString());
}
sql方式:
IgniteCache<String, Task> cache = cache();
SqlQuery sql = new SqlQuery(Task.class,"taskStatus = ? ");
List<CacheEntryImpl> list = cache.query(sql.setArgs(status)).getAll();
开始实验:
说明
1.Cache<String,Task>
2.Task是一个复杂pojo,其中设立索引 taskId和taskTemplateId
3.单节点启动,cache容量为50000
案例:
- 查询分四步进行,
a) 根据模板扫描查询任务(截图中日志未说明按模板查询)
b) 根据模板sql查询任务
c) 扫描查询所有任务
d) Sql查询所有任务
结果:
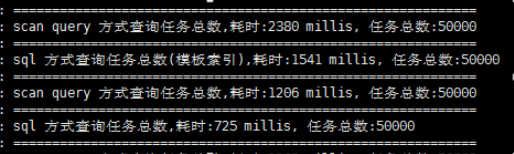
可以看到查询结果为:
B优于 a;
D优于 c;
初步说明用sql查询的方式要优于扫描查询
但是继续运行会发现查询时间越来越短,为了防止ignite自动加载到缓存引起的时间不准确,如图:
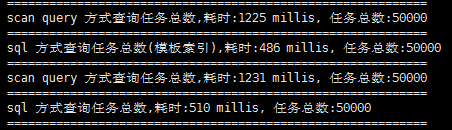
将查询的顺序调换,方案顺序为(d,c,b,a)重新测试:
结果:
重新测试依然发现查询次数越多花的时间越少,得出结论,先执行的查询要花更多的时间,后执行的查询会利用一些本地缓存,但是对比两次的测试结果不妨碍得出结论:
无论是全部扫描还是根据某个属性查询,sql查询的速度都要优于扫描查询的速度
测试二:
在以上环境基础上,验证索引的建立对于查询的意义,保留以上测试的日志留作去掉索引时测试结果的对比
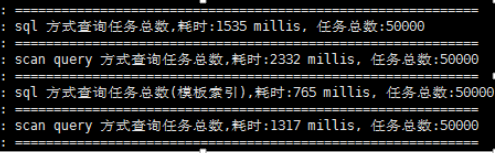
结果:
这个结果比较上一张截图发现,其他查询都没什么变化,但是利用模板索引的查询显然比上面快了不少???这个跟设想完全不同,建立索引反而降低了速度,去掉索引更快.
为了验证是不是哪里出了错误或者看到的结果不够端正,继续查看查询平稳之后的查询速度:
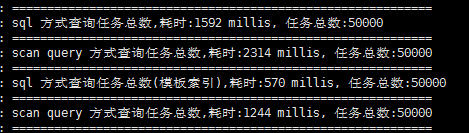
有索引:

无索引:
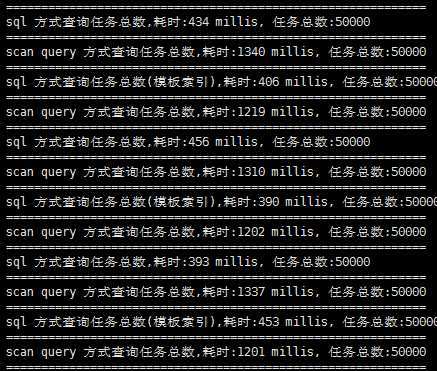
观察得出:有索引的查询在稳定后根据模板索引的查询稳定在了0.3秒附近,而没有索引的查询只能稳定在0.4秒附近,得出建立索引确实会让sql的查询变得更快,另外索引的建立会导致扫描方式的查询变得更慢.至于最开始的查询截图得出的相悖结论只是一时情况,与实际生产情况不符,只遵循稳定后的速度.
初步验证就到这里,还有问题后续验证:
- 由于ignite机制的存在会导致同一个cache越查越快,但是如果中途加入新的数据,sql查询能否维持0.3秒左右的查询速度,还是会恢复到最开始的0.7秒?
- 为什么最开始的时候没有索引的情况下反而速度更快?
- 多节点下,查询是否会变得更快还是更慢?
多节点下的查询效率
初步验证:
在上面实验结果的情况下,直接双开节点,获取结果信息

对比结果发现:
双节点的情况下,扫描查询的速度会变得更慢,但是sql的查询没有因为网络交互速度变慢,反而速度更快,查询基本低于0.3秒,
初步得出ignite使用结论:
多节点下使用sql查询并建立索引是最好的查询.
实验:ignite查询效率探究的更多相关文章
- PostgreSQL LIKE 查询效率提升实验<转>
一.未做索引的查询效率 作为对比,先对未索引的查询做测试 EXPLAIN ANALYZE select * from gallery_map where author = '曹志耘'; QUERY P ...
- mysql limit查询(分页查询)探究
MySQL的Limit子句 LIMIT offset,length Limit子句可以被用于强制 SELECT 语句返回指定的记录数.Limit接受一个或两个数字参数.参数必须是一个整数常量.如果给定 ...
- 【MySQL】过滤后的结果集较大,用LIMIT查询分页记录,查询效率不理想
> 参考的优秀文章 优化LIMIT分页--<高性能MySQL>(电子工业出版社) > 场景描述 遇到一个场景:查询排序后的结果集较大,我们采用分页显示,每页显示20条记录,但是 ...
- mysql数据库查询过程探究和优化建议
查询过程探究 我们先看一下向mysql发送一个查询请求时,mysql做了什么? 如上图所示,查询执行的过程大概可分为6个步骤: 客户端向MySQL服务器发送一条查询请求 服务器首先检查查询缓存,如果命 ...
- SQL 提高查询效率
1.关于SQL查询效率,100w数据,查询只要1秒,与您分享: 机器情况p4: 2.4内存: 1 Gos: windows 2003数据库: ms sql server 2000目的: 查询性能测试, ...
- 疑难杂症——EF+Automapper引发的查询效率问题解析
前言:前面总结了一些WebApi里面常见问题的解决方案,本来打算来分享下oData+WebApi的使用方式的,奈何被工作所困,只能将此往后推了.今天先来看看EF和AutoMapper联合使用的一个问题 ...
- 【转载】Arcengine效率探究之二——属性的更新
文转载自hymyjl2010<Arcengine效率探究之二——属性的更新> 修改一批要素的属性有多种方法,当数据量较大时,若选择不当可能会大大影响速度. 一.IRowBuffer 方 ...
- mysql 实战 or、in与union all 的查询效率
OR.in和union all 查询效率到底哪个快. 网上很多的声音都是说union all 快于 or.in,因为or.in会导致全表扫描,他们给出了很多的实例. 但真的union all真的快于o ...
- 提高SQL查询效率(SQL优化)
要提高SQL查询效率where语句条件的先后次序应如何写 http://blog.csdn.net/sforiz/article/details/5345359 我们要做到不但会写SQL,还要做到 ...
随机推荐
- 彻底区分html的attribute与dom的property
当初在学html时始终没有弄清楚的关于attribute与property的区别,竟然在看angular文档时弄明白了. angular官方文档的数据绑定一节提到html attribute与dom ...
- C++点滴20130724
warning c4627:"#include stdafx.h":在查找预编译头使用时跳过 原因: 1.没有添加 #include "stdafx.h" 2. ...
- SPARK 创建新任务
1.应用程序创建 SparkContext 的实例 sc 2.利用 SparkContext 的实例来创建生成 RDD 3.经过一连串的 transformation 操作,原始的 RDD 转换成为其 ...
- yii2之GridView小部件
GridView小部件用于展示多条数据的列表.GridView小部件的使用需要数据提供器即yii\data\ActiveDataProvider的实例作为参数,所以 第一步就是要在控制器方法中创建这个 ...
- Linux系列教程(七)——Linux帮助和用户管理命令
上篇博客我们介绍了Linux文件搜索命令,其中find是用的最多的也是功能最强大的文件或目录搜索命令,和另一个搜索命令locate的区别是,find命令是全盘搜索,刚创建的文件也能搜索的到,而loca ...
- Python学习笔记_02:使用Tkinter连接MySQL数据库实现登陆注册功能
1 环境搭建 1.1 Python安装 1.2 MySQL环境搭建 1.3安装MySQLdb 2 具体实现 2.1 登陆界面 2.2 注册界面 2.3 具体实现部分代码 1 环境搭建 1.1 P ...
- .5-Vue源码之AST(1)
讲完了数据劫持原理和一堆初始化 现在是DOM相关的代码了 上一节是从这个函数开始的: // Line-3924 Vue.prototype._init = function(options) { // ...
- mongo+mongoose+express
直接上指令: //*代表自定义名字 //使用数据库 use * //检查当前数据库 db //查询数据库列表 show dbs //查询当前数据库集合 show collections //插入文档自 ...
- 什么是Echarts?Echarts如何使用?
什么是Echarts? Echarts--商业级数据图表 商业级数据图表,它是一个纯JavaScript的图标库,兼容绝大部分的浏览器,底层依赖轻量级的canvas类库ZRender,提供直观, ...
- 套接字(linux相关)
前言:略 一.前因 一切从tcp.udp开始. 众所周知,网络模型一般有两种模型,一种为OSI概念模型(七层),另一种为tcp/ip网络模型(四层). tcp/ip应用层对应OSI的应用层.显示层.会 ...