大话Spark(8)-源码之DAGScheduler
DAGScheduler的主要作用有2个:
一、把job划分成多个Stage(Stage内部并行运行,整个作业按照Stage的顺序依次执行)
二、提交任务
以下分别介绍下DAGScheduler是如何做这2件事情的,然后再跟源码看下DAGScheduler的实现。
一、如何把Job划分成多个Stage
1) 回顾下宽依赖和窄依赖
窄依赖:父RDD的每个分区只被子RDD的一个分区使用。(map,filter,union操作等)
宽依赖:父RDD的分区可能被多个子RDD的分区使用。(reduceByKey,groupByKey等)
如下图所示,左侧的算子为窄依赖, 右侧为宽依赖
 

窄依赖可以支持在同一个集群Executor上,以管道形式顺序执行多条命令,例如在执行了map后,紧接着执行filter。分区内的计算收敛,不需要依赖所有分区的数据,可以并行地在不同节点进行计算。所以它的失败回复也更有效,因为它只需要重新计算丢失的parent partition即可。最重要的是窄依赖没有shuffle过程,而宽依赖由于父RDD的分区可能被多个子RDD的分区使用,所以一定伴随着shuffle操作。
2) DAGScheduler 如何把job划分成多个Stage
DAGScheduler会把job划分成多个Stage,如下图sparkui上的截图所示,job 0 被划分成了3个stage
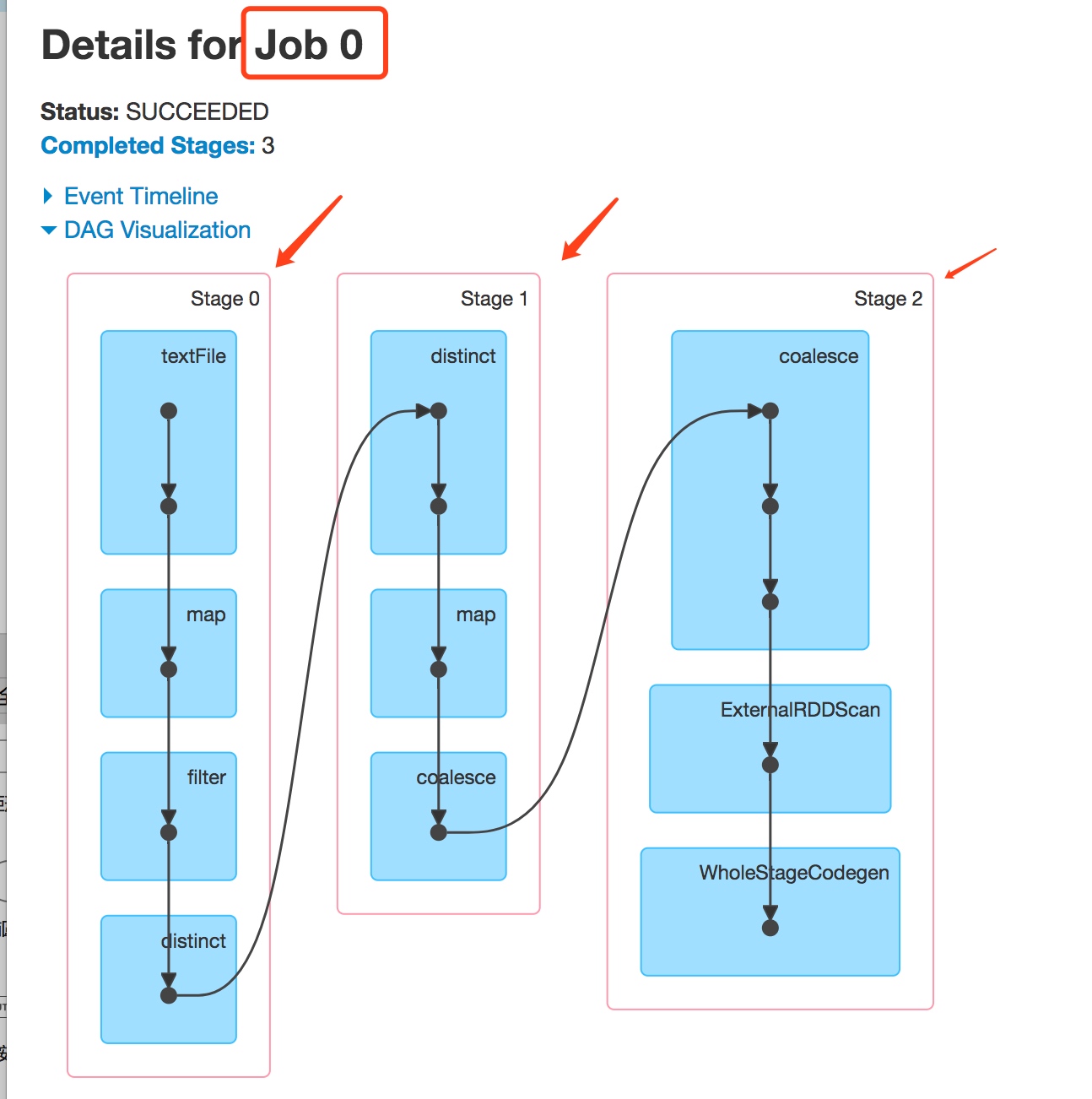 

DAGScheduler划分Stage的过程如下:
DAGScheduler会从触发action操作的那个RDD开始往前倒推,首先会为最后一个RDD创建一个stage,然后往前倒推的时候,如果发现对某个RDD是宽依赖(产生Shuffle),那么就会将宽依赖的那个RDD创建一个新的stage,那个RDD就是新的stage的最后一个RDD。然后依次类推,继续往前倒推,根据窄依赖或者宽依赖进行stage的划分,直到所有的RDD全部遍历完成为止。
3) wordcount的Stage划分
在前面大话spark(3)-一图深入理解WordCount程序在Spark中的执行过程中,我画过一张wordcount作业的Stage的划分的图,如下:
 

可以看出上图中,第一个stage的3个task并行执行,遇到reduceByKey这个产生shuffle的操作开始划分出新的Stage。但是其实这张图是不准确的。
其实对于每一种有shuffle的操作,比如groupByKey、reduceByKey、countByKey的底层都对应了三个RDD:MapPartitionsRDD、ShuffleRdd、MapPartitionsRDD
(宽依赖shuffle生成的rdd为ShuffleRdd)
其中Shuffle发生在第一个RDD和第二个RDD之间,前面说过如果发现对某个RDD是宽依赖(产生Shuffle),那么就会将宽依赖的那个RDD创建一个新的stage
所以说上图中 reduceByKey操作其实对应了3个RDD,其中第一个RDD会被划分到Stage1中!
4) DAGScheduler划分Stage源码
RDD类中所有的action算子触发计算都会调用sc.runjob方法, 而sc.runjob方法底层都会调用到SparkContext中的dagscheduler对象的runJob方法。
例如count这个action操作
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
一直追着runJob方法往底层看最终调用dagScheduler.runJob,传入调用这个方法的rdd
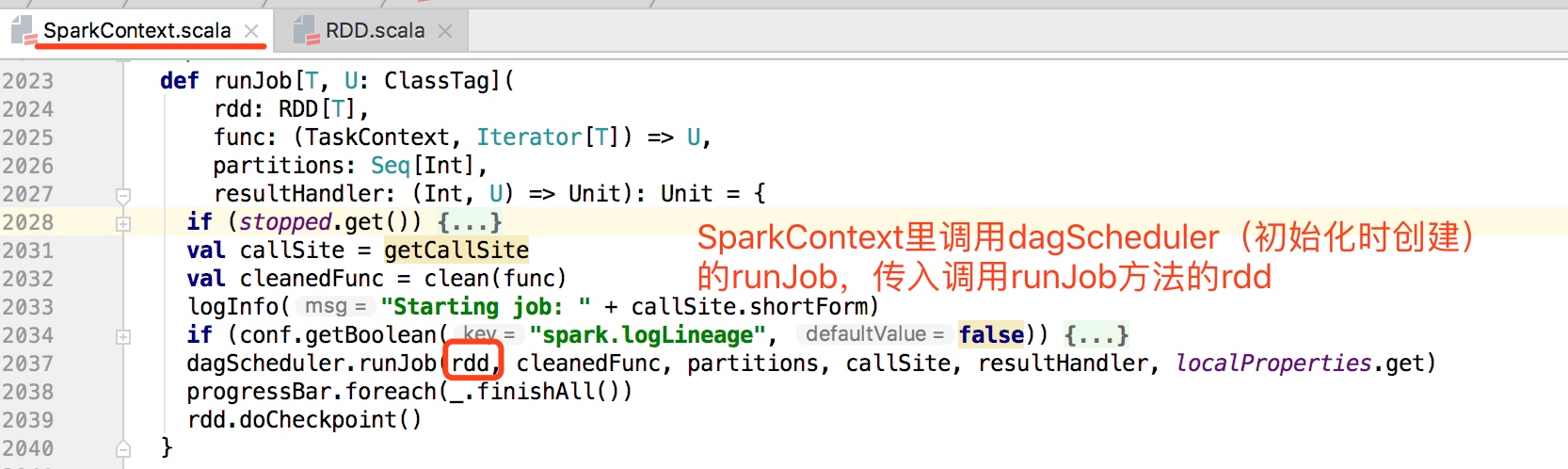 

dagScheduler.runJob内部调用submitJob提交当前的action到scheduler
submitJob内部调用DAGSchedulerEventProcessLoop发送JobSubmitted的信息,
在JobSubmitted内部最终调用dagScheduler的handleJobSubmitted(dagScheduler的核心入口)。
handleJobSubmitted方法如下:
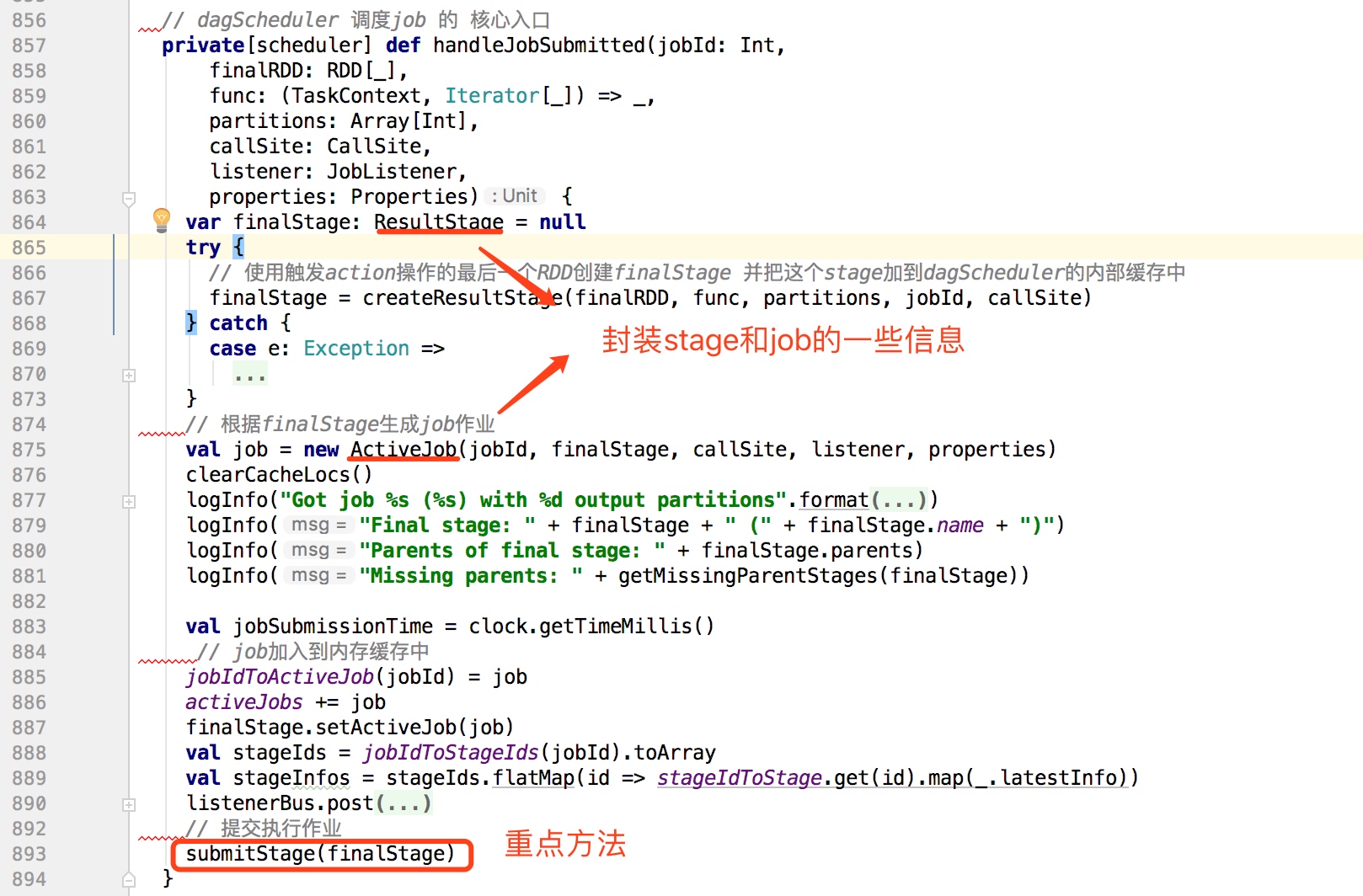 

上面代码中submitStage提交作业,其内代码如下:
 

submitStage方法中调用getMissingParentStages方法获取finalStage的父stage,
如果不存在,则使用submitMissingTasks方法提交执行;
如果存在,则把该stage放到waitingStages中,同时递归调用submitStage。通过该算法把存在父stage的stage放入waitingStages中,不存在的作为作业运行的入口。
其中最重要的getMissingParentStages中是stage划分的核心代码,如下:
 

这里就是前面说到的stage划分的方式,查看最后一个rdd的依赖,如果是窄依赖,则不创建新的stage,如果是宽依赖,则用getOrCreateShuffledMapStage方法创建新的rdd,依次往前推。
所以Stage的划分算法最核心的两个方法为submitStage何getMissingParentStage
二、提交任务
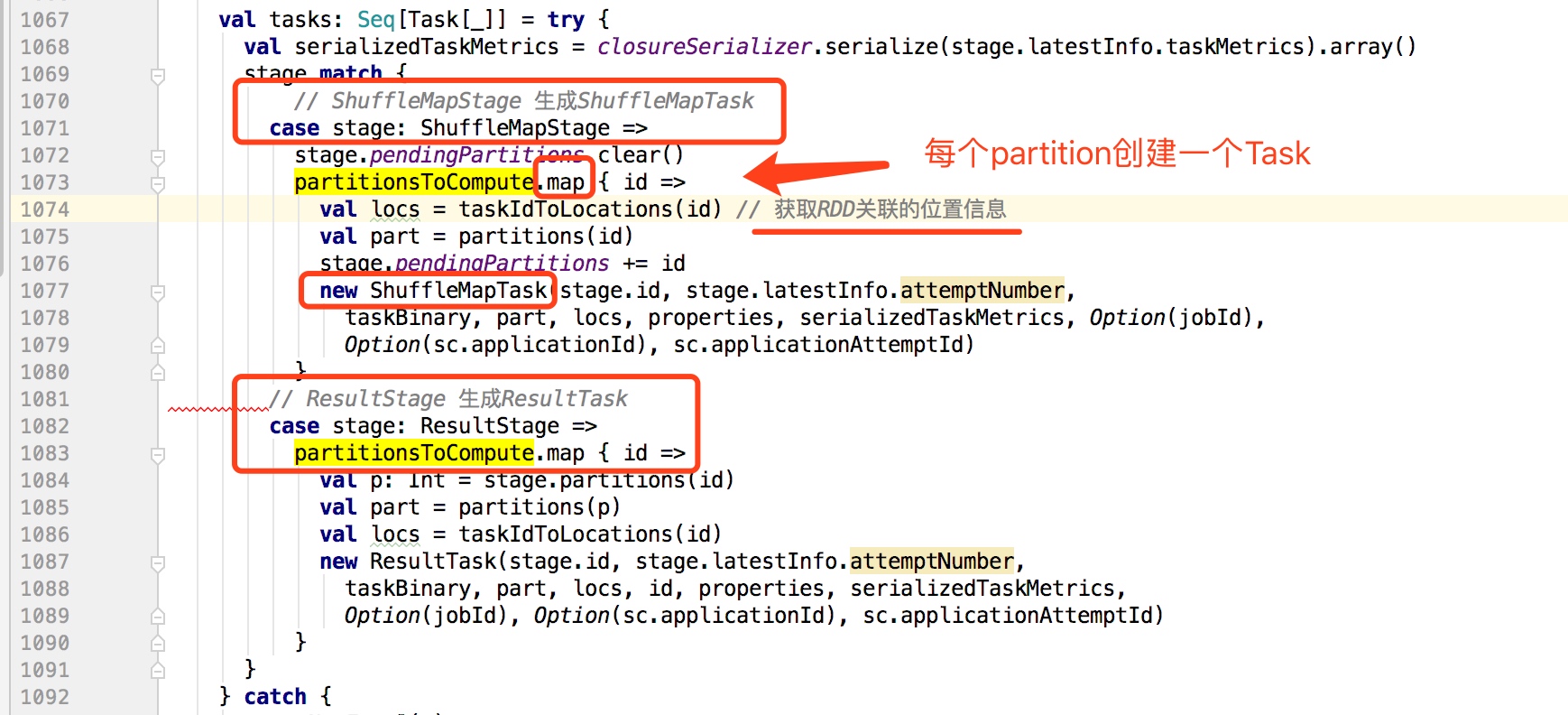
当Stage提交运行后,在DAGScheduler的submitMissingTasks方法中,会根据Stage的Partition个数拆分对应个数任务,这些任务组成一个TaskSet提交到TaskScheduler进行处理。
对于ResultStage(最后一个Stage)生成ResultTask,对于ShuffleMapStage生成ShuffleMapTask。
每一个TaskSet包含对应Stage的所有task,这些Task的处理逻辑完全一样,不同的是对应处理的数据,而这些数据是对应其数据分片的(Partition)。
submitMissingTasks如下:
 


 

大话Spark(8)-源码之DAGScheduler的更多相关文章
- 大话Spark(6)-源码之SparkContext原理剖析
SparkContext是整个spark程序通往集群的唯一通道,他是程序的起点,也是程序的终点. 我们的每一个spark个程序都需要先创建SparkContext,接着调用SparkContext的方 ...
- 大话Spark(7)-源码之Master主备切换
Master作为Spark Standalone模式中的核心,如果Master出现异常,则整个集群的运行情况和资源都无法进行管理,整个集群将处于无法工作的状态. Spark在设计的时候考虑到了这种情况 ...
- 大话Spark(9)-源码之TaskScheduler
上篇文章讲到DAGScheduler会把job划分为多个Stage,每个Stage中都会创建一批Task,然后把Task封装为TaskSet提交到TaskScheduler. 这里我们来一起看下Tas ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
- Spark Streaming源码解读之JobScheduler内幕实现和深度思考
本期内容 : JobScheduler内幕实现 JobScheduler深度思考 JobScheduler 是整个Spark Streaming调度的核心,需要设置多线程,一条用于接收数据不断的循环, ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- 第十一篇:Spark SQL 源码分析之 External DataSource外部数据源
上周Spark1.2刚发布,周末在家没事,把这个特性给了解一下,顺便分析下源码,看一看这个特性是如何设计及实现的. /** Spark SQL源码分析系列文章*/ (Ps: External Data ...
- 第十篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 query
/** Spark SQL源码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache在 ...
随机推荐
- AFNetworking 取消请求
取消单个操作: AFHTTPRequestOperation *operation = [[AFHTTPRequestOperation alloc] initWithRequest:request] ...
- jquery14 on() trigger() : 事件操作的相关方法
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content ...
- js---10作用域链
<html> <head> <title>scope basic</title> </head> <body> <scri ...
- js02---字符串
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content ...
- JDK版本切换批处理脚本
我们经常在开发是遇到jdk版本切换的问题 1.手动去修改JAVA_HOME环境变量,将变量的值指向对应的JDK版本的安装目录即可. 2.通过编写批处理脚本来根据选择的JDK版本动态修改JAVA_HOM ...
- newgrp---将当前登录用户临时加入到已有的组中
Linux中的newgrp命令主要是将当前登录用户临时加入到已有的组中,用法如下: [linuxidc@localhost etc]$ newgrp grptest 上面命令的含义是将用户linuxi ...
- BZOJ 1108 POI2007 天然气管道Gaz
题目大意:给定平面上的n个黑点和n个白点.一个黑点仅仅能和右下方的白点匹配.代价为曼哈顿距离,求最小权值完备匹配 STO OTZ STO OTZ STO OTZ ans=Σ(y黑-y白+x白-x黑) ...
- win8用久了变得非常慢, 磁盘占用100%
完美解决方式: 直接重装win7 完美解决这个问题 在网上查了非常久也没找到有效方法, 求教
- c++运算符重载笔记
运算符重载的概念:给原有的运算符赋予新的功能: 比如:+ 不仅可以做算术运算也可以连接俩个字符串 一元运算符:只与一个操作数进行运算 比如 正负号 运算符重载的本质是:函数重载. <<与& ...
- SQL2012的新分页方法
SELECT BusinessEntityID , FirstName , LastName FROM Person.Person ORDER BY BusinessEntityID OFFSET ( ...