SparkSql初级编程实践
1.Spark SQL 基本操作
将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json。
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
为 employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
(1) 查询所有数据;
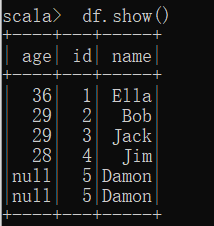
(2) 查询所有数据,并去除重复的数据;
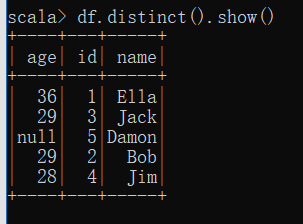
(3) 查询所有数据,打印时去除 id 字段;
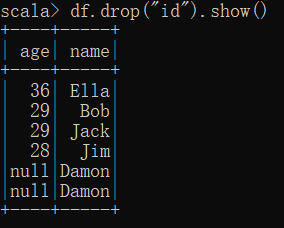
(4) 筛选出 age>30 的记录;
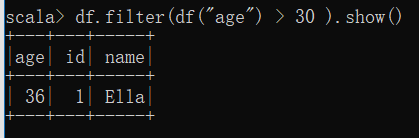
(5) 将数据按 age 分组;
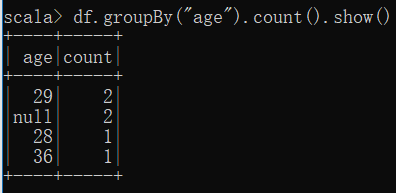
(6) 将数据按 name 升序排列;
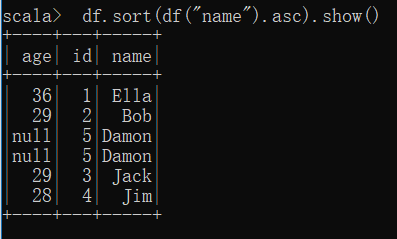
(7) 取出前 3 行数据;

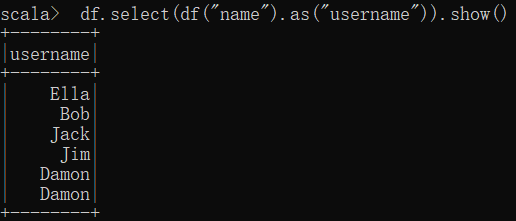
(8) 查询所有记录的 name 列,并为其取别名为 username;
(9) 查询年龄 age 的平均值;

(10) 查询年龄 age 的最小值。

2.编程实现将 RDD 转换为 DataFrame
源文件内容如下(包含 id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到
DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代
码。
package cn.spark.study.sy5
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
object Testsql {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("Testsql")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//hdfs://192.168.6.134:9000/nlc/1.txt
//H:\文件\数据集
val studentRDD = sc.textFile("D:\\myDevelopTools\\Intellij IDEA\\workplace\\spark-study-scala\\src\\main\\java\\cn\\spark\\study\\sy5\\employee.txt", 1)
.map { line => Row(line.split(",")(0), line.split(",")(1), line.split(",")(2)) }
// 第二步,编程方式动态构造元数据
val structType = StructType(Array(
StructField("id", StringType, true),
StructField("name", StringType, true),
StructField("age", StringType, true)))
// 第三步,进行RDD到DataFrame的转换
val studentDF = sqlContext.createDataFrame(studentRDD, structType)
// 继续正常使用
studentDF.registerTempTable("employee")
// val teenagerDF = sqlContext.sql("select usrid,count(usrid) from students group by usrid order by usrid")
val teenagerDF = sqlContext.sql("select id,name,age from employee")
val teenagerRDD = teenagerDF.rdd.collect().foreach { row => println("id:"+row(0)+",name:"+row(1)+",age:"+row(2)) }
}
}

3. 编程实现利用 DataFrame 读写 MySQL 的数据
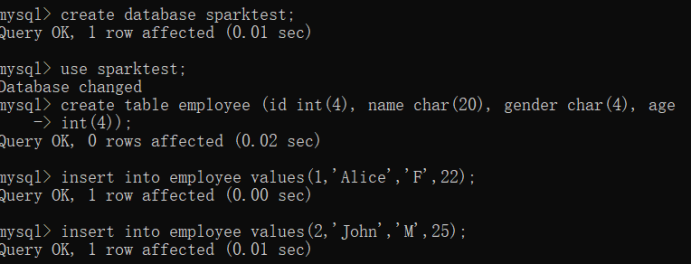
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee,包含如表 6-2 所示的
两行数据。
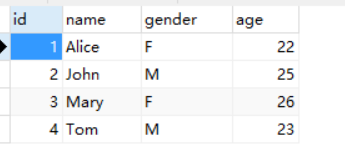
表 6-2 employee 表原有数据
id name gender Age
1 Alice F 22
2 John M 25
(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入如表 6-3 所
示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。
表 6-3 employee 表新增数据
id name gender age
3 Mary F 26
4 Tom M 23
package cn.spark.study.sy5
import java.util.Properties import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SQLContext}
/**
* Created by Lenovo on 2019/3/27.
*/
object TestMySQL {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setMaster("local")
.setAppName("Testsql")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc) val employeeRDD = sqlContext.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" "))
val schema = StructType(List(StructField("id", IntegerType,
true),StructField("name", StringType, true),StructField("gender", StringType,
true),StructField("age", IntegerType, true)))
val rowRDD = employeeRDD.map(p => Row(p(0).toInt,p(1),
p(2),p(3).toInt))
val employeeDF = sqlContext.createDataFrame(rowRDD, schema)
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "123123")
prop.put("driver","com.mysql.jdbc.Driver")
employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest", "sparktest.employee", prop)
val jdbcDF = sqlContext.read.format("jdbc").option("url",
"jdbc:mysql://localhost:3306/sparktest").option("driver","com.mysql.jdbc.Driver").option("dbtable","employee").option("user","root").option("password", "123123").load()
jdbcDF.agg("age" -> "max", "age" -> "sum")
} }
SparkSql初级编程实践的更多相关文章
- C语言初级编程实践:2048小游戏
大部分同学学习C语言编程以后不知道能通过什么样的项目才可以锻炼自己的思维功力,2048相信大家都应该熟悉,不管是手机上还是网页版的相信大家都玩过,这个简单的控制台版本的游戏是我曾经在伟易达上班时一个嵌 ...
- Spark编程基础_RDD初级编程
摘要:Spark编程基础_RDD初级编程 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素 ...
- 高性能javascript学习笔记系列(5) -快速响应的用户界面和编程实践
参考高性能javascript 理解浏览器UI线程 用于执行javascript和更新用户界面的进程通常被称为浏览器UI线程 UI线程的工作机制可以理解为一个简单的队列系统,队列中的任务按顺序执行 ...
- 高性能JavaScript 编程实践
前言 最近在翻<高性能JavaScript>这本书(2010年版 丁琛译),感觉可能是因为浏览器引擎的改进或是其他原因,书中有些原本能提高性能的代码在最新的浏览器中已经失效.但是有些章节的 ...
- Method Swizzling和AOP(面向切面编程)实践
Method Swizzling和AOP(面向切面编程)实践 参考: http://www.cocoachina.com/ios/20150120/10959.html 上一篇介绍了 Objectiv ...
- 编程实践中C语言的一些常见细节
对于C语言,不同的编译器采用了不同的实现,并且在不同平台上表现也不同.脱离具体环境探讨C的细节行为是没有意义的,以下是我所使用的环境,大部分内容都经过测试,且所有测试结果基于这个环境获得,为简化起见, ...
- 第二章 C语言编程实践
上章回顾 宏定义特点和注意细节 条件编译特点和主要用处 文件包含的路径查询规则 C语言扩展宏定义的用法 第二章 第二章 C语言编程实践 C语言编程实践 预习检查 异或的运算符是什么 宏定义最主要的特点 ...
- 试读《JavaScript语言精髓与编程实践》
有幸看到iteye的活动,有幸读到<JavaScript语言精髓与编程实践_第2版>的试读版本,希望更有幸能完整的读到此书. 说来读这本书的冲动,来得很诡异,写一篇读后感,赢一本书,其实奖 ...
- Python GUI编程实践
看完了<python编程实践>对Python的基本语法有了一定的了解,加上认识到python在图形用户界面和数据库支持方面快捷,遂决定动手实践一番. 因为是刚接触Python,对于基本的数 ...
随机推荐
- nyoj92-图像有用区域【BFS】
"ACKing"同学以前做一个图像处理的项目时,遇到了一个问题,他需要摘取出图片中某个黑色线圏成的区域以内的图片,现在请你来帮助他完成第一步,把黑色线圏外的区域全部变为黑色. ...
- 微信公众号开发之获取微信用户的openID
(注:openID同一用户同一应用唯一,UnionID同一用户不同应用唯一.不同应用指微信开放平台下的不同用户.) 1. 申请测试号(获得appID.appsecret) 2. 填写服务器配置并验 ...
- 【codeforces 807B】T-Shirt Hunt
[题目链接]:http://codeforces.com/contest/807/problem/B [题意] 你在另外一场已经结束的比赛中有一个排名p; 然后你现在在进行另外一场比赛 然后你当前有一 ...
- Java基础学习总结(62)——Java中的流和Socket
按行读入方式: BufferedReader(); 1.以行为读取单位,读取比较方便. 按行读一般都是字符读. BufferedReader和PrintWriter的内存分析图: 数据流: 输入 输出 ...
- CF449 C. Jzzhu and Apples
/* http://codeforces.com/problemset/problem/449/C cf 449 C. Jzzhu and Apples 数论+素数+贪心 */ #include &l ...
- asp.net mvc--identity知识点
asp.net identity 特性 one asp.net identity 持久化控制和易于管理 单元测试 自定义角色 基于声明的身份验证 OWIN集成 NuGet包 identity的类图 简 ...
- 【LeetCode-面试算法经典-Java实现】【033-Search in Rotated Sorted Array(在旋转数组中搜索)】
[033-Search in Rotated Sorted Array(在旋转数组中搜索)] [LeetCode-面试算法经典-Java实现][全部题目文件夹索引] 原题 Suppose a sort ...
- Android框架简要介绍
1. Android架构直观图 下图展示了Android系统的主要组成部分: 总体上而言,Android系统结构由5个部分组成.从上到下,别人是Applications (Android应用 ...
- android:QQ多种側滑菜单的实现
在这篇文章中写了 自己定义HorizontalScrollView实现qq側滑菜单 然而这个菜单效果仅仅是普通的側拉效果 我们还能够实现抽屉式側滑菜单 就像这样 第一种效果 另外一种效果 第三种效果 ...
- JS的 验证组织机构的合法性
以下直接上代码 //验证组织机构合法性方法 function orgcodevalidate(value){ if(value!=""){ var values=value.spl ...