大数据技术 - MapReduce 作业的运行机制
前几章我们介绍了 Hadoop 的 MapReduce 和 HDFS 两大组件,内容比较基础,看完后可以写简单的 MR 应用程序,也能够用命令行或 Java API 操作 HDFS。但要对 Hadoop 做深入的了解,显然不够用。因此本章就深入了解一下 MapReduce 应用的运行机制,从而学习 Hadoop 各个组件之间如何配合完成 MR 作业。本章是基于 Hadoop YARN 框架介绍,YARN(Yet Another Resource Negotiator)是 Hadoop 的集群资源管理器,也是 Hadoop2 的默认资源管理器。为什么要用 YARN 框架? 简单来说 Hadoop1 的时候没有资源管理器,因此在 Hadoop1 集群只能运行 MR 作业。YARN 出现后统一管理集群的资源,因此 Spark、Storm 等其他分布式计算框架也能运行在 Hadoop 集群。同理,除了 YARN 还有其他的资源管理框架,目前比较火的是 k8s。
运行机制
运行一个 MR 程序主要涉及以下 5 个部分:
- 客户端: 提交 MR 作业,也就是我们运行 hadoop jar xxx 的命令后,启动的 Java 程序
- YARN ResourceManager: YARN 集群主节点,负责协调集群上计算资源的分配
- YARN NodeManager:YARN 集群从节点,负责启动和监视机器上的容器(container)
- MapReduce Application Master:负责协调 MR 作业,当然 Spark 作业也有对应的 application master
运行 MR 任务的工作原理如下图,本图摘自《Hadoop 权威指南(第四版)》:
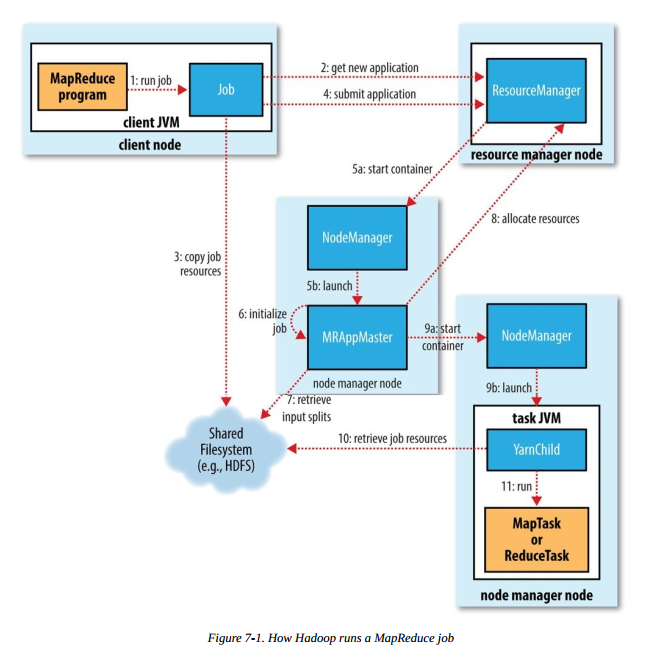
步骤1 是我们在客户端节点(集群中的某台机器)执行 hadoop jar xxx 命令后,启动 MR 作业的流程,后续会涉及以下几个重要流程
- 作业的提交和初始化
- 任务的分配与执行
- 进度和状态的更新
下面会详细介绍每个流程。这里我们将编写的整个 MR 程序叫做作业,MR作业运行后的 map 或 reduce 任务统称为任务。
任务的提交和初始化
作业的提交
- 向 ResourceManager 申请一个新的应用 ID(步骤 2),之前的 MR 例子我们可以看到,应用 ID 的形式为:application_1551593879638_0009
- 计算作业分片检查作业的输入输出,若输入文件不可分割或者输入路径不存在,报错返回;如果没有指定输出路径或者输出路径已存在,报错返回
- 将作业运行所需的资源(jar、配置文件和分片信息等)复制到共享文件系统中(步骤 3),默认为 HDFS 。目录名称以应用 ID 命名
- 调用 ResourceManager 的 submitApplication() 方法提交作业(步骤4)
以上的流程均在客户端节点完成。
作业的初始化
ResourceManager 收到调用它的 submitApplication() 方法后,会在 NodeManager 中分配一个 container (步骤 5a),在 container 中启动 application master(步骤 5b) 。MapReduce application master 的主类是 MRAppMaster。application master 完成初始化后(步骤 6),从共享文件系统(如:HDFS)获取分片信息(步骤 7)。对每个分片创建一个 map 任务和 reduce 任务,并分配任务 ID。如果 application master 判断该任务不是 uber 任务,那么接下来会进行任务分配。
任务分配与运行
任务分配
application master 会为 map 任务和 reduce 任务向 ResourceManager 申请分配资源。map 任务的优先级高于 reduce 任务,且直到 5% 的 map 任务完成时,reduce 任务请求才能发出。reduce 任务可以在集群的任意机器执行,但 map 任务有数据本地化的限制,理想情况下数据分片和 map 任务在同一节点运行,即数据本地化(data local),这样 map 任务直接读取本地的数据,不需要网络 IO。如果达不到理想情况,可以在数据节点同一机架上启动 map 任务,即机架本地化(rack local),这样 map 任务从同机架上其他节点将数据拷贝到自己的节点。最差的情况是分片和 map 任务不在同一机架,需要跨机架拷贝数据。application master 申请的资源包括内存和 CPU 核心数,申请的大小可以通过 4 个属性指定:
- mapreduce.map.memory.mb:map 任务内存, 单位:MB,默认:1024
- mapreduce.map.cpu.vcores:map 任务 CPU 核心数,默认:1
- mapreduce.reduce.memory.mb:reduce 任务内存,单位:MB,默认:1024
- mapreduce.reduce.cpu.vcores:reduce 任务 CPU 核心数,默认:1
任务执行
ResourceManager 为任务在某个 NodeManager 上分配容器后(步骤 9a),application master 会与该 NodeManager 通信来启动容器(步骤 9b)。该任务的主类为 YarnChild,该任务运行前会先将共享文件系统(如:HDFS)上的文件本地化(步骤 10),文件包括:配置文件、JAR包和分布式缓存文件。最后,运行 map 或 reduce 任务(步骤 11)。
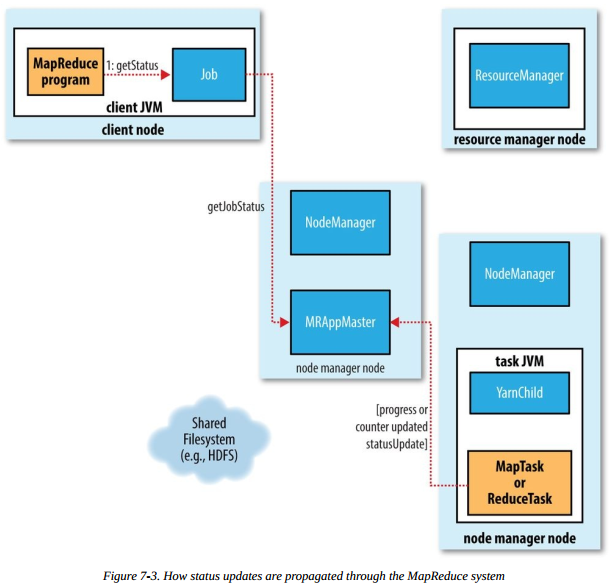
进度和状态更新
当用户成功提交并且作业成功运行后,用户希望能够看到作业的运行状态。一个作业和它的每个任务都有一个状态,包括:作业或任务的状态(比如,运行中、成功或失败),map 或 reduce 任务的进度以及计数器值等。
- 当 map 或 reduce 任务运行时,通过接口向自己的 application master 上报进度和状态
- 作业的运行期间,客户端请求 application master 以获得最新的状态
流程图如下:
作业的完成
application master 接到最后一个任务成功完成的通知后,便把作业置位成功得状态。可以端查询到任务成功完成后,从 waitCompletion() 方法返回。作业的统计信息和计数器值输出在控制台。最后,application master 会做一些清理工作,作业信息由 JobHistoryServer 存档,以便用户以后查询。
小结
本章主要介绍 MR 作业的运行机制,并且了解了 YARN 集群主从节点职责及其相互之间的配合。通过这篇文章的介绍希望读者对 MR 作业的运行机制有大致的了解。我们可以简单总结下本章介绍的相关组件的作用。本文主要参考《Hadoop 权威指南(第四版)》和 Hadoop 官方文档,有兴趣的读者可以深入研究,一起探讨。
大数据技术 - MapReduce 作业的运行机制的更多相关文章
- 大数据技术 - MapReduce的Combiner介绍
本章来简单介绍下 Hadoop MapReduce 中的 Combiner.Combiner 是为了聚合数据而出现的,那为什么要聚合数据呢?因为我们知道 Shuffle 过程是消耗网络IO 和 磁盘I ...
- 大数据技术 - MapReduce的Shuffle及调优
本章内容我们学习一下 MapReduce 中的 Shuffle 过程,Shuffle 发生在 map 输出到 reduce 输入的过程,它的中文解释是 “洗牌”,顾名思义该过程涉及数据的重新分配,主要 ...
- 大数据技术 —— MapReduce 简介
本文为senlie原创,转载请保留此地址:http://www.cnblogs.com/senlie/ 1.概要很多计算在概念上很直观,但由于输入数据很大,为了能在合理的时间内完成,这些计算必须分布在 ...
- 大数据技术 - MapReduce 应用的配置和单元测试
上一章的 MapReduce 应用中,我们使用了自定义配置,并用 GenericOptionsParser 处理命令行输入的配置,这种方式简单粗暴.但不是 MapReduce 应用常见的写法,本章第一 ...
- 除Hadoop大数据技术外,还需了解的九大技术
除Hadoop外的9个大数据技术: 1.Apache Flink 2.Apache Samza 3.Google Cloud Data Flow 4.StreamSets 5.Tensor Flow ...
- 从大数据技术变迁猜一猜AI人工智能的发展
目前大数据已经成为了各家互联网公司的核心资产和竞争力了,其实不仅是互联网公司,包括传统企业也拥有大量的数据,也想把这些数据发挥出作用.在这种环境下,大数据技术的重要性和火爆程度相信没有人去怀疑. 而A ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
- 大数据技术之HBase
第1章 HBase简介 1.1 什么是HBase HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储. 官方 ...
- 大数据技术之Hadoop入门
第1章 大数据概论 1.1 大数据概念 大数据概念如图2-1 所示. 图2-1 大数据概念 1.2 大数据特点(4V) 大数据特点如图2-2,2-3,2-4,2-5所示 图2-2 大数据特点之大量 ...
随机推荐
- Confluence 6 缓存性能优化
Confluence 的运行状态与缓存状态有这密切的关系.针对 Confluence 的管理员来说,尤其是大型站点的 Confluence 管理员,设置好缓存尤其显得关键. 希望修改缓存的大小: 进入 ...
- Confluence 6 从一个备份中获得文件附件
页面中的文件附件可以从备份中获得而不需要将备份文件导入到 Confluence 中.这个在用户删掉了附件,但是你还是想恢复这个附件的时候就变得非常有用了. 自动备份和手动备份都允许你进行这个操作,但是 ...
- mouseover、mouseout与mouseenter、mouseleave
待定 附加链接: http://www.aijquery.cn/Html/jqueryrumen/129.html
- nginx实践(五)之代理服务(正向代理与反向代理介绍)
正向代理 正向代理代理是为客户端服务,代理负责DNS解析域名到对应ip,并进行访问服务端,返回响应给客户端 反向代理 客户端自己负责请求DNS解析域名到对应ip,服务端通过代理分发流量,进行负载均衡 ...
- servlet 遇到的奇怪问题
一. servlet URl 连接多了 %09 原因value里面多了个空格 value=" value'; 改成 value="value'; 二.servlet get方法可以 ...
- Ubuntu shutdown now 关机后 开机黑屏
一重装gdm3 失败 sudo apt-get remove --purge nvidia-* # 卸载nvidia相关组件 sudo apt purge gdm gdm3 # 卸载gdm和 ...
- LabView(控件部分)
1.虚拟仪器的概述: 虚拟仪器是基于计算机的的仪器,计算机和仪器的密切结合是目前仪器的一个发展方向,大概有两种结合方式,一种是将计算机装入仪器中,实例就是只能化的仪器,流行的嵌入式系统的仪器,另一种就 ...
- WinHex数据恢复笔记(一)
WinHex数据恢复功能强大,可以从硬件簇上扇区进行数据扫描恢复.首先对winhex的各个功能介绍.之后对实例记录一个Word文档删除后进行恢复. 1.WinHex数据恢复软件的编辑区输入与其他普通文 ...
- less 写关键帧动画
@keyframes 关键帧动画写在less里的时候,务必要写在所有的{}之外,不能被{}包裹 甚至务必写在代码的最后 不然报错 Compilation resulted in incorrect C ...
- K/3 Cloud Web API接口说明文
K/3 Cloud Web API接口说明文 目的 三方集成,提供第三方系统与Cloud集成调用接口. 技术实现 HTTP + Json 提供标准接口 编号 名称 说明 1 Kingdee.BOS.W ...