【译】为什么BERT有3个嵌入层,它们都是如何实现的
本文翻译自Why BERT has 3 Embedding Layers and Their Implementation Details
引言
本文将阐述BERT中嵌入层的实现细节,包括token embeddings、segment embeddings, 和position embeddings.
概览
下面这幅来自原论文的图清晰地展示了BERT中每一个嵌入层的作用:
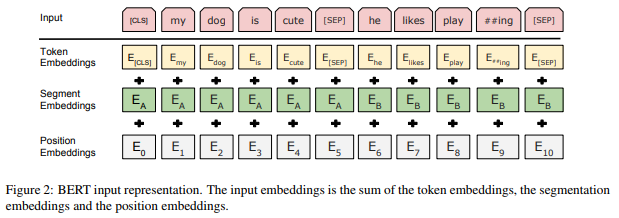
和大多数NLP深度学习模型一样,BERT将输入文本中的每一个词(token)送入token embedding层从而将每一个词转换成向量形式。但不同于其他模型的是,BERT又多了两个嵌入层,即segment embeddings和 position embeddings。在阅读完本文之后,你就会明白为何要多加这两个嵌入层了。
Token Embeddings
作用
正如前面提到的,token embedding 层是要将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示。
实现
假设输入文本是 “I like strawberries”。下面这个图展示了 Token Embeddings 层的实现过程:

输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP]) 。它们视为后面的分类任务和划分句子对服务的。
tokenization使用的方法是WordPiece tokenization. 这是一个数据驱动式的tokenization方法,旨在权衡词典大小和oov词的个数。这种方法把例子中的“strawberries”切分成了“straw” 和“berries”。这种方法的详细内容不在本文的范围内。有兴趣的读者可以参阅 Wu et al. (2016) 和 Schuster & Nakajima (2012)。使用WordPiece tokenization让BERT在处理英文文本的时候仅需要存储30,522 个词,而且很少遇到oov的词。
Token Embeddings 层会将每一个wordpiece token转换成768维的向量。这样,例子中的6个token就被转换成了一个(6, 768) 的矩阵或者是(1, 6, 768)的张量(如果考虑batch_size的话)。
Segment Embeddings
作用
BERT 能够处理对输入句子对的分类任务。这类任务就像判断两个文本是否是语义相似的。句子对中的两个句子被简单的拼接在一起后送入到模型中。那BERT如何去区分一个句子对中的两个句子呢?答案就是segment embeddings.
实现
假设有这样一对句子 (“I like cats”, “I like dogs”)。下面的图成仙了segment embeddings如何帮助BERT区分两个句子:
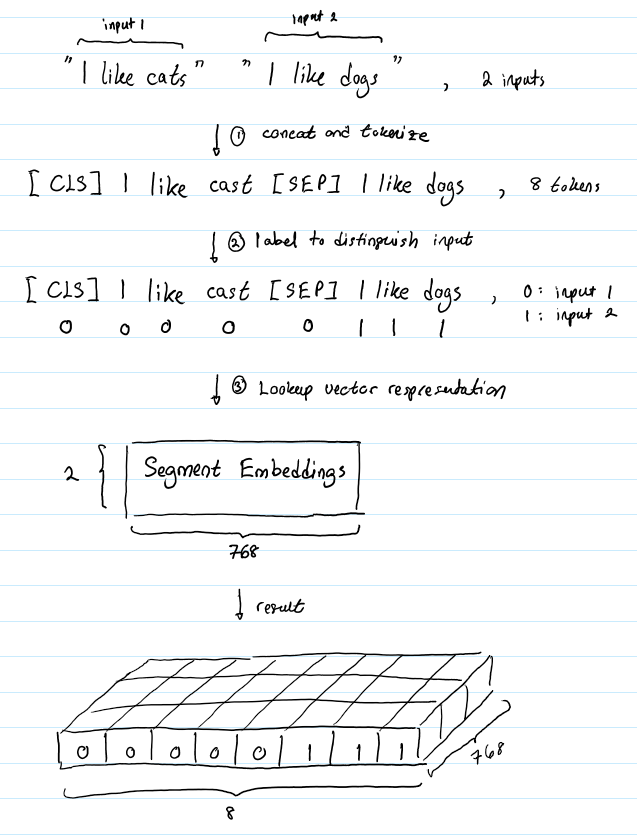
Segment Embeddings 层只有两种向量表示。前一个向量是把0赋给第一个句子中的各个token, 后一个向量是把1赋给第二个句子中的各个token。如果输入仅仅只有一个句子,那么它的segment embedding就是全0。
Position Embeddings
作用
BERT包含这一串Transformers (Vaswani et al. 2017),而且一般认为,Transformers无法编码输入的序列的顺序性。 博客更加详细的解释了这一问题。总的来说,加入position embeddings会让BERT理解下面下面这种情况:
I think, therefore I am
第一个 “I” 和第二个 “I”应该有着不同的向量表示。
实现
BERT能够处理最长512个token的输入序列。论文作者通过让BERT在各个位置上学习一个向量表示来讲序列顺序的信息编码进来。这意味着Position Embeddings layer 实际上就是一个大小为 (512, 768) 的lookup表,表的第一行是代表第一个序列的第一个位置,第二行代表序列的第二个位置,以此类推。因此,如果有这样两个句子“Hello world” 和“Hi there”, “Hello” 和“Hi”会由完全相同的position embeddings,因为他们都是句子的第一个词。同理,“world” 和“there”也会有相同的position embedding。
合成表示
我们已经介绍了长度为n的输入序列将获得的三种不同的向量表示,分别是:
- Token Embeddings, (1, n, 768) ,词的向量表示
- Segment Embeddings, (1, n, 768),辅助BERT区别句子对中的两个句子的向量表示
- Position Embeddings ,(1, n, 768) ,让BERT学习到输入的顺序属性
这些表示会被按元素相加,得到一个大小为(1, n, 768)的合成表示。这一表示就是BERT编码层的输入了。
结论
在本文中,笔者介绍了BERT几个嵌入层的作用以及实现。
参考文献
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding; Devlin et al. 2018.
Google’s Neural Machine Translation System: Briding the Gap between Human and Machine Translation; Wu et al. 2016
Japanese and Korean Voice Search; Schuster and Nakajima. 2012.
Attention Is All You Need; Vaswani et al. 2017.
【译】为什么BERT有3个嵌入层,它们都是如何实现的的更多相关文章
- 【译】BERT表示的可解释性分析
目录 从词袋模型到BERT 分析BERT表示 不考虑上下文的方法 考虑语境的方法 结论 本文翻译自Are BERT Features InterBERTible? 从词袋模型到BERT Mikol ...
- 请问JAVA三层架构,持久层,业务层,表现层,都该怎么理解?和MVC三层模型有什么区别
持久层用来固化数据,如常说的DAO层,操作数据库将数据入库业务层用来实现整体的业务逻辑 如 前台获得了数据,逻辑层去解析这些数据,效验这些数据等操作表现层很好解释 你现在看到的网页 一些界面 都属于 ...
- [源码解析] 模型并行分布式训练Megatron (5) --Pipedream Flush
[源码解析] 模型并行分布式训练Megatron (5) --Pipedream Flush 目录 [源码解析] 模型并行分布式训练Megatron (5) --Pipedream Flush 0x0 ...
- 嵌入(embedding)层的理解
首先,我们有一个one-hot编码的概念. 假设,我们中文,一共只有10个字...只是假设啊,那么我们用0-9就可以表示完 比如,这十个字就是“我从哪里来,要到何处去” 其分别对应“0-9”,如下: ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 【转载】最强NLP预训练模型!谷歌BERT横扫11项NLP任务记录
本文介绍了一种新的语言表征模型 BERT--来自 Transformer 的双向编码器表征.与最近的语言表征模型不同,BERT 旨在基于所有层的左.右语境来预训练深度双向表征.BERT 是首个在大批句 ...
- 想研究BERT模型?先看看这篇文章吧!
最近,笔者想研究BERT模型,然而发现想弄懂BERT模型,还得先了解Transformer. 本文尽量贴合Transformer的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进 ...
- BERT论文解读
本文尽量贴合BERT的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进行翻译,其中有一些论文没有解释清楚或者笔者未能深入理解的地方,都有放出原文,如有不当之处,请各位多多包含,并 ...
- 【转载】BERT:用于语义理解的深度双向预训练转换器(Transformer)
BERT:用于语义理解的深度双向预训练转换器(Transformer) 鉴于最近BERT在人工智能领域特别火,但相关中文资料却很少,因此将BERT论文理论部分(1-3节)翻译成中文以方便大家后续研 ...
随机推荐
- jdk1.8api帮助文档,转载
链接:https://pan.baidu.com/s/1jkDC68t6ha3PrSbx2BMevQ 密码:o425 转自https://blog.csdn.net/weixin_37012881/a ...
- netty拆包粘包
客户端 tcp udp socket网络编程接口 http/webservice mqtt/xmpp 自定义RPC (dubbo) 应用层 服务端 ServerSocket ss = new serv ...
- android studio 升级到3.3.1后,提示程序包不存在
android studio 升级到3.3.1后,提示程序包不存在 原因 主Module--A 引用了其他Moduel--B里的jar库, 只需要把B的dependencies改成如下(implent ...
- docker systemctl无法使用
Dockerfile for systemd base image FROM centos:7 ENV container docker RUN (cd /lib/systemd/system/sys ...
- 【C++】const & 指针
https://blog.csdn.net/qq_21808961/article/details/78401950
- OpenCV中feature2D——BFMatcher和FlannBasedMatcher
作者:holybin 原文:https://blog.csdn.net/holybin/article/details/40926315 Brute Force匹配和FLANN匹配是opencv二维特 ...
- MVC Action 返回类型
https://www.cnblogs.com/xielong/p/5940535.html https://blog.csdn.net/WuLex/article/details/79008515 ...
- redis的pub/sub命令
Redis 发布订阅 Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息. Redis 客户端可以订阅任意数量的频道. 下图展示了频道 cha ...
- 在思科模拟器上配置AAA认证
1.实验拓扑 2.检测用户之间连通性 PC2 ping PC-A PC-C ping PC-A 3.路由及服务器配置 R1:在路由器R1上配置一个本地用户账号并且利用本地AAA通过console ...
- [UE4]接口
一个椅子可以被抓起和放下,一扇门可以打开和关上.一个抽屉可以拉开和关上. 椅子.门.抽屉都可以用手拉,然后放下,但是它们的打开和关上的行为是不一样的,它们之间没有继承关系,没法共用“打开”和“关闭”的 ...