【译】为什么BERT有3个嵌入层,它们都是如何实现的
本文翻译自Why BERT has 3 Embedding Layers and Their Implementation Details
引言
本文将阐述BERT中嵌入层的实现细节,包括token embeddings、segment embeddings, 和position embeddings.
概览
下面这幅来自原论文的图清晰地展示了BERT中每一个嵌入层的作用:
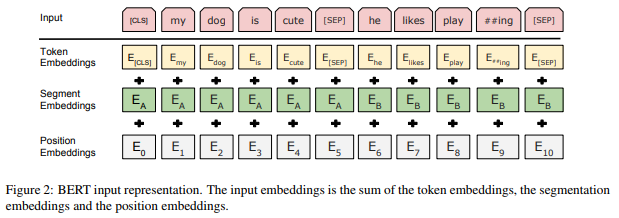
和大多数NLP深度学习模型一样,BERT将输入文本中的每一个词(token)送入token embedding层从而将每一个词转换成向量形式。但不同于其他模型的是,BERT又多了两个嵌入层,即segment embeddings和 position embeddings。在阅读完本文之后,你就会明白为何要多加这两个嵌入层了。
Token Embeddings
作用
正如前面提到的,token embedding 层是要将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示。
实现
假设输入文本是 “I like strawberries”。下面这个图展示了 Token Embeddings 层的实现过程:

输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP]) 。它们视为后面的分类任务和划分句子对服务的。
tokenization使用的方法是WordPiece tokenization. 这是一个数据驱动式的tokenization方法,旨在权衡词典大小和oov词的个数。这种方法把例子中的“strawberries”切分成了“straw” 和“berries”。这种方法的详细内容不在本文的范围内。有兴趣的读者可以参阅 Wu et al. (2016) 和 Schuster & Nakajima (2012)。使用WordPiece tokenization让BERT在处理英文文本的时候仅需要存储30,522 个词,而且很少遇到oov的词。
Token Embeddings 层会将每一个wordpiece token转换成768维的向量。这样,例子中的6个token就被转换成了一个(6, 768) 的矩阵或者是(1, 6, 768)的张量(如果考虑batch_size的话)。
Segment Embeddings
作用
BERT 能够处理对输入句子对的分类任务。这类任务就像判断两个文本是否是语义相似的。句子对中的两个句子被简单的拼接在一起后送入到模型中。那BERT如何去区分一个句子对中的两个句子呢?答案就是segment embeddings.
实现
假设有这样一对句子 (“I like cats”, “I like dogs”)。下面的图成仙了segment embeddings如何帮助BERT区分两个句子:
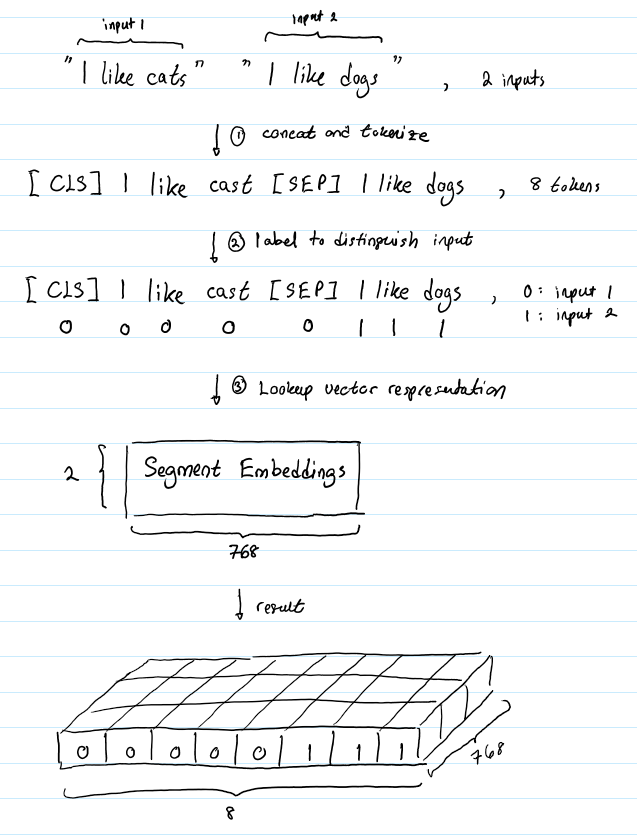
Segment Embeddings 层只有两种向量表示。前一个向量是把0赋给第一个句子中的各个token, 后一个向量是把1赋给第二个句子中的各个token。如果输入仅仅只有一个句子,那么它的segment embedding就是全0。
Position Embeddings
作用
BERT包含这一串Transformers (Vaswani et al. 2017),而且一般认为,Transformers无法编码输入的序列的顺序性。 博客更加详细的解释了这一问题。总的来说,加入position embeddings会让BERT理解下面下面这种情况:
I think, therefore I am
第一个 “I” 和第二个 “I”应该有着不同的向量表示。
实现
BERT能够处理最长512个token的输入序列。论文作者通过让BERT在各个位置上学习一个向量表示来讲序列顺序的信息编码进来。这意味着Position Embeddings layer 实际上就是一个大小为 (512, 768) 的lookup表,表的第一行是代表第一个序列的第一个位置,第二行代表序列的第二个位置,以此类推。因此,如果有这样两个句子“Hello world” 和“Hi there”, “Hello” 和“Hi”会由完全相同的position embeddings,因为他们都是句子的第一个词。同理,“world” 和“there”也会有相同的position embedding。
合成表示
我们已经介绍了长度为n的输入序列将获得的三种不同的向量表示,分别是:
- Token Embeddings, (1, n, 768) ,词的向量表示
- Segment Embeddings, (1, n, 768),辅助BERT区别句子对中的两个句子的向量表示
- Position Embeddings ,(1, n, 768) ,让BERT学习到输入的顺序属性
这些表示会被按元素相加,得到一个大小为(1, n, 768)的合成表示。这一表示就是BERT编码层的输入了。
结论
在本文中,笔者介绍了BERT几个嵌入层的作用以及实现。
参考文献
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding; Devlin et al. 2018.
Google’s Neural Machine Translation System: Briding the Gap between Human and Machine Translation; Wu et al. 2016
Japanese and Korean Voice Search; Schuster and Nakajima. 2012.
Attention Is All You Need; Vaswani et al. 2017.
【译】为什么BERT有3个嵌入层,它们都是如何实现的的更多相关文章
- 【译】BERT表示的可解释性分析
目录 从词袋模型到BERT 分析BERT表示 不考虑上下文的方法 考虑语境的方法 结论 本文翻译自Are BERT Features InterBERTible? 从词袋模型到BERT Mikol ...
- 请问JAVA三层架构,持久层,业务层,表现层,都该怎么理解?和MVC三层模型有什么区别
持久层用来固化数据,如常说的DAO层,操作数据库将数据入库业务层用来实现整体的业务逻辑 如 前台获得了数据,逻辑层去解析这些数据,效验这些数据等操作表现层很好解释 你现在看到的网页 一些界面 都属于 ...
- [源码解析] 模型并行分布式训练Megatron (5) --Pipedream Flush
[源码解析] 模型并行分布式训练Megatron (5) --Pipedream Flush 目录 [源码解析] 模型并行分布式训练Megatron (5) --Pipedream Flush 0x0 ...
- 嵌入(embedding)层的理解
首先,我们有一个one-hot编码的概念. 假设,我们中文,一共只有10个字...只是假设啊,那么我们用0-9就可以表示完 比如,这十个字就是“我从哪里来,要到何处去” 其分别对应“0-9”,如下: ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
- 【转载】最强NLP预训练模型!谷歌BERT横扫11项NLP任务记录
本文介绍了一种新的语言表征模型 BERT--来自 Transformer 的双向编码器表征.与最近的语言表征模型不同,BERT 旨在基于所有层的左.右语境来预训练深度双向表征.BERT 是首个在大批句 ...
- 想研究BERT模型?先看看这篇文章吧!
最近,笔者想研究BERT模型,然而发现想弄懂BERT模型,还得先了解Transformer. 本文尽量贴合Transformer的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进 ...
- BERT论文解读
本文尽量贴合BERT的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进行翻译,其中有一些论文没有解释清楚或者笔者未能深入理解的地方,都有放出原文,如有不当之处,请各位多多包含,并 ...
- 【转载】BERT:用于语义理解的深度双向预训练转换器(Transformer)
BERT:用于语义理解的深度双向预训练转换器(Transformer) 鉴于最近BERT在人工智能领域特别火,但相关中文资料却很少,因此将BERT论文理论部分(1-3节)翻译成中文以方便大家后续研 ...
随机推荐
- Anaconda下安装OpenCV
安装命令:conda install -c https://conda.binstar.org/menpo opencvwin10+Anaconda3+python3.5.2,最终cv版本为3.3.1 ...
- 单例模式实例&多线程应用
单例模式是指:对于一个类在内存中只能存在唯一一个对象,这种设计模式叫做单例设计模式. 单例设计模式的写法: 1. 设置私有(private)的构造方法. 2. 实例化一个该类的对象作为成员变量,并设置 ...
- 【linux】之日志查看
搜索日志 -n 显示行号 grep 1570xxxx -n callback.tomcat-catalina-out 显示从第多少行~多少行 sed -n '464913,465020p' callb ...
- Presto 性能优化点
1.指定需要返回的字段 [GOOD]: SELECT time,user,host FROM tbl[BAD]: SELECT * FROM tbl 2.合理设置分区字段 当过滤条件作用在分区字段上面 ...
- 窗口置顶 - 仿TopWind
前置学习:低级鼠标hook,获得鼠标状态. 这个在原来获得鼠标状态的基础上,加上一个事件处理即可. TopWind就是一个可以置顶窗口的文件,避免复制粘贴的时候的来回切换(大窗口与小窗口),算是一个实 ...
- MySQL Group Replication-MGR集群
简介 MySQL Group Replication(简称MGR)字面意思是mysql组复制的意思,但其实他是一个高可用的集群架构,暂时只支持mysql5.7和mysql8.0版本. 是MySQL官方 ...
- springboot连mysql报一个奇怪的错误
错误提示:Cause: org.springframework.jdbc.CannotGetJdbcConnectionException: Could not get JDBC Connection ...
- dotnet core调试docker下生成的dump文件
最近公司预生产环境.net core应用的docker容器经常出现内存暴涨现象,有时会突然吃掉几个G,触发监控预警,造成容器重启. 分析了各种可能原因,修复了可能发生的内存泄露,经测试本地正常,但是发 ...
- JUnit报告美化——ExtentReports
美化后效果 美化后的报告,页面清晰简洁.重要信息都可以体现出来,用例通过率,失败的用例和失败原因 主要技术点 ExtentReports JUnit的@Rule 重写TestWatcher的succe ...
- CSS3之动画模块实现轮播图
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...