[C++]Linux之文件拷贝在系统调用和C库函数下的效率比较
声明:如需引用或者摘抄本博文源码或者其文章的,请在显著处注明,来源于本博文/作者,以示尊重劳动成果,助力开源精神。也欢迎大家一起探讨,交流,以共同进步~ 0.0
题目:
1. 分别利用文件的系统调用read、write和文件的库函数fread、fwrite实现文件复制功能,比较在每次读取一个字节和1024字节时两个程序的执行效率,并分析原因。
分析:
预先准备好一份已经存储数据的普通文件(data.txt)
设置两对照组:
对照组1(系统调用组):在执行系统调用实现文件拷贝功能时,分别对读取一个字节和1024个字节记时,读取的执行时间若分别记为t1和t1024,然后通过比较1024×t1与t1024二者的时间来比较执行效率(时间效率为主)。
对照组2(库函数组):在执行库函数实现文件拷贝功能时,分别对文件的系统调用与文件的库函数的执行时间形成对照,比较二者执行效率。
即 本次实验需要记录4个变量:
1)系统调用的读取1字节的时间:Syst1
2)系统调用的读取1024字节的时间:Syst1024
3)库函数的读取1字节的时间:Lib1
4)库函数的读取1024字节:Lib1024
猜想:
系统调用的性能较库函数高,所以,性能上:Syst > Lib;
读取字节数小的时间效率将高于读取字节数大的时间效率,所以,时间上:T(1) < T(1024)
则,猜想结论: Lib1024 > Syst1024 > Lib1 > Syst1 (耗时)
开始实施实验,验证猜想 Action!
实验
【系统调用组】
gcc main-system.c -o main-system.out
time ./main-system.out
/*
@author:johnny
@description:系统调用
*/ #include<stdio.h>
#include<stdlib.h>//exit(num)
#include<sys/types.h>
#include<sys/stat.h>
#include<string.h>
#include<fcntl.h>
#include<time.h>
#include<unistd.h>//dependency:close/write/open method #define LENGTH_1 1
#define LENGTH_1024 1024 //统计系统调用的读取1字节的时间效率,并实现文件复制功能
double read1Byte(){
double startTime;
double endTime;
double Syst1;//系统调用的读取1字节的时间:Syst1 int len,fread,fwrite;
off_t off;//记录文件游标偏移位置
char readStr[LENGTH_1];
fread = open("data.txt",O_RDWR | O_CREAT,S_IRUSR | S_IWUSR);//打开数据源文件
fwrite = creat("copy-1-data.txt", 0700);//创建拷贝文件
if(fwrite == -1){
perror("\n[read1Byte] Fail to create file 'copy-1-data.txt'.\n\n");
exit(1);
} else {
printf("\n[read1Byte] Create file 'copy-1-data.txt' OK.\n\n");
}
if(fwrite){//write data to file.
off = lseek(fwrite,0,SEEK_SET); //获取并重置游标位置为文件开头处,SEEK_CUR当前读写位置后增加offset[0]个位移量
if(off == -1){
perror("\n[read1Byte] Fail to lseek.\n\n");
exit(1);
}
startTime = clock();//从打开文件后,读取文件数据前开始记录时间
len = read(fread, readStr, LENGTH_1);//从data.txt读取数据
endTime = clock();
while(len){//判断len是否为0,如果为0,则说明读取到了文件尾,则停止
printf("%s", readStr);
write(fwrite, readStr,strlen(readStr)); //一边读取源数据文件,一边写入新文件数据
len = read(fread, readStr, LENGTH_1);
}
} close(fread);
close(fwrite); Syst1 = (double)(endTime - startTime) / 1000; //(单位:毫秒)
printf("\n[read1Byte] 系统调用的读取1字节的时间[Syst1]:%f ms\n\n", Syst1); return Syst1;
} //统计系统调用的读取1024字节的时间效率,并实现文件复制功能
double read1024Bytes(){
double startTime;
double endTime;
double Syst1024;//系统调用的读取1024字节的时间:Syst1024 int len,fread,fwrite;
off_t off;//记录文件游标偏移位置
char readStr[LENGTH_1024];
fread = open("data.txt",O_RDWR | O_CREAT,S_IRUSR | S_IWUSR);//打开数据源文件
fwrite = creat("copy-1024-data.txt", 0700);//创建拷贝文件
if(fwrite == -1){
perror("\n[read1024Byte] Fail to create file 'copy-1024-data.txt'.\n\n");
exit(1);
} else {
printf("\n[read1024Bytes] Create file 'copy-1024-data.txt' OK.\n\n");
}
if(fwrite){//write data to file.
off = lseek(fwrite,0,SEEK_SET); //获取并重置游标位置为文件开头处,SEEK_CUR当前读写位置后增加offset[0]个位移量
if(off == -1){
perror("\n[read1024Bytes] Fail to lseek.\n");
exit(1);
}
startTime = clock();//从打开文件后,读取文件数据前开始记录时间
len = read(fread, readStr, LENGTH_1024);//从data.txt读取数据
endTime = clock();
while(len){//判断len是否为0,如果为0,则说明读取到了文件尾,则停止
printf("%s", readStr);
write(fwrite, readStr,strlen(readStr)); //一边读取源数据文件,一边写入新文件数据
len = read(fread, readStr, LENGTH_1024);
}
} close(fread);
close(fwrite); Syst1024 = (double)(endTime - startTime) / 1000; //(单位:毫秒)
printf("\n[read1024Bytes] 系统调用的读取1024字节的时间[Syst1024]:%f ms\n\n", Syst1024); return Syst1024;
} int main(){
read1Byte();//统计系统调用的读取1字节的时间效率,并实现文件复制功能
read1024Bytes();//统计系统调用的读取1024字节的时间效率,并实现文件复制功能
return 0;
}
运行效果:
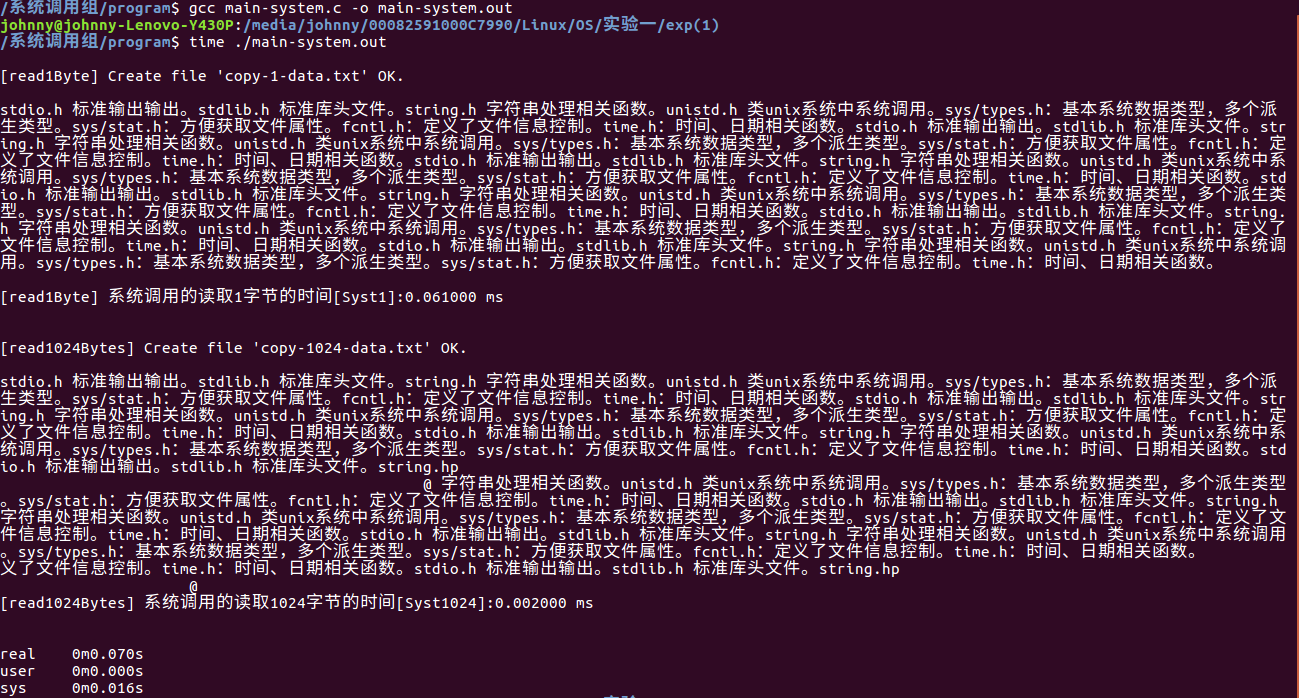
【库函数调用组】
gcc main-lib.c -o main-lib.out
time ./main-lib.out
/* @author:johnny
@description:库函数
*/ #include<stdio.h>
#include<stdlib.h>//exit(num)
#include<sys/types.h>
#include<sys/stat.h>
#include<string.h>
#include<fcntl.h>
#include<time.h>
#include<unistd.h>//dependency:close/write/open method #define LENGTH_1 1
#define LENGTH_1024 1024 //统计库函数的读取1字节的时间效率,并实现文件复制功能
double read1Byte(){
double startTime;
double endTime;
double Lib1;//库函数的读取1字节的时间:Lib1 FILE * readStream;//读取数据源文件data.txt的文件流
FILE * writeStream;//拷贝数据源文件data.txt的文件流
readStream = fopen("data.txt","r+");//只读方式打开可读写的且必须已经存在的文件
writeStream = fopen("copy-1-data.txt","w+");//只写方式打开文件。若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
if(readStream == NULL){
fprintf(stderr,"\n[read1Byte] readStream can not open file 'data.txt'.\n\n");
return 0;
}
if(writeStream == NULL){
fprintf(stderr,"\n[read1Byte] writeStream can not create/open file 'copy-1-data.txt'.\n\n");
return 0;
} else {
printf("\n[read1024Bytes] writeStream create/open file 'copy-1-data.txt' OK.\n\n");
} size_t len;//记录每次实际读取到的缓冲数据长度,若为0,则可能是读取错误或者已读到文件尾。
int off;//记录文件游标当前偏移位置 char buffer[LENGTH_1];
//write data to file.
off = fseek(writeStream,0,SEEK_SET);//获取并重置游标位置为文件开头处,SEEK_CUR当前读写位置后增加offset[0]个位移量
if(off == -1){
perror("\n[read1Byte] Fail to fseek.\n\n");
exit(1);
}
startTime = clock();//从打开文件后,读取文件数据前开始记录时间
len = fread(buffer, LENGTH_1, LENGTH_1, readStream);//从data.txt读取数据,len为返回实际写入的nmemb数目
endTime = clock();
while(len){//判断len是否为0,如果为0,则说明读取到了文件尾,则停止
printf("%s", buffer);
fwrite(fwrite, LENGTH_1, len, writeStream); //一边读取源数据文件,一边写入新文件数据
len = fread(buffer, LENGTH_1, LENGTH_1, readStream);
} fclose(readStream);
fclose(writeStream); Lib1 = (double)(endTime - startTime);
printf("\n[read1Byte] 库函数的读取1字节的时间[Lib1]:%f ms\n\n", Lib1); return Lib1;
} //统计库函数的读取1024字节的时间效率,并实现文件复制功能
double read1024Bytes(){
double startTime;
double endTime;
double Lib1024;//库函数的读取1024字节的时间:Lib1024 FILE * readStream;//读取数据源文件data.txt的文件流
FILE * writeStream;//拷贝数据源文件data.txt的文件流
readStream = fopen("data.txt","r+");//只读方式打开可读写的且必须已经存在的文件
writeStream = fopen("copy-1024-data.txt","w+");//只写方式打开文件。若文件存在则文件长度清为零,即该文件内容会消失。若文件不存在则建立该文件。
if(readStream == NULL){
fprintf(stderr,"\n[read1024Bytes] readStream can not open file 'data.txt'.\n\n");
return 0;
}
if(writeStream == NULL){
fprintf(stderr,"\n[read1024Bytes] writeStream can not create/open file 'copy-1024-data.txt'.\n\n");
return 0;
} else {
printf("\n[read1024Bytes] writeStream create/open file 'copy-1024-data.txt' OK.\n\n");
} size_t len;//记录每次实际读取到的缓冲数据长度,若为0,则可能是读取错误或者已读到文件尾。
int off;//记录文件游标当前偏移位置 char buffer[LENGTH_1024];
//write data to file.
off = fseek(writeStream, 0, SEEK_SET);//获取并重置游标位置为文件开头处,SEEK_CUR当前读写位置后增加offset[0]个位移量
if(off == -1){
perror("\n[read1024Bytes] Fail to fseek.\n\n");
exit(1);
}
startTime = clock();//从打开文件后,读取文件数据前开始记录时间
len = fread(buffer, LENGTH_1, LENGTH_1024, readStream);//从data.txt读取数据,len为返回实际写入的nmemb数目
endTime = clock();
while(len){//判断len是否为0,如果为0,则说明读取到了文件尾,则停止
printf("%s", buffer);
fwrite(fwrite, LENGTH_1, len, writeStream); //一边读取源数据文件,一边写入新文件数据
len = fread(buffer, LENGTH_1, LENGTH_1024, readStream);
} fclose(readStream);
fclose(writeStream); Lib1024 = (double)(endTime - startTime);
printf("\n[read1024Bytes] 库函数的读取1字节的时间[Lib1024]:%f ms\n\n", Lib1024); return Lib1024;
} int main(){
read1Byte();//统计库函数的读取1字节的时间效率,并实现文件复制功能
read1024Bytes();//统计库函数的读取1024字节的时间效率,并实现文件复制功能
return 0;
}
运行效果:
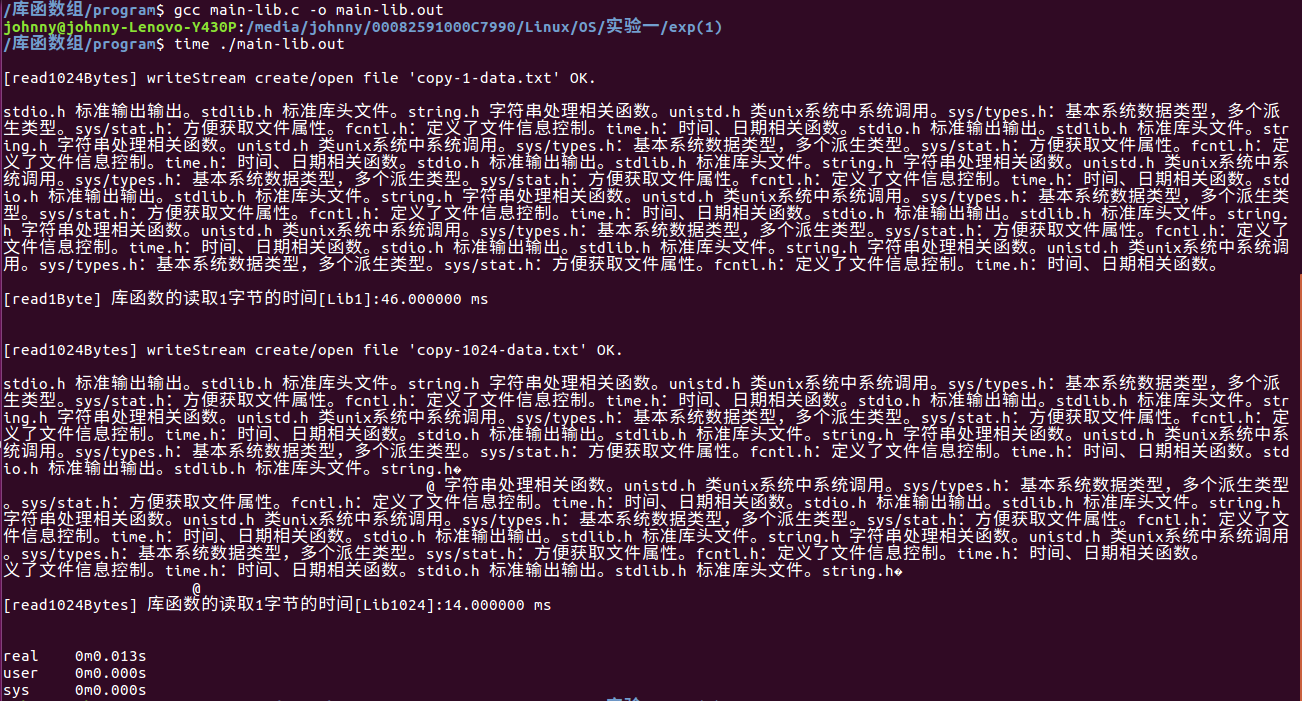
结果:
| 变量 | 读取字节数(byte) | API | 消耗时间(ms) |
|
Syst1 |
1 |
系统调用 | 0.061 |
| Syst1024 | 1024 | 系统调用 | 0.002 |
| Lib1 | 1 | 库函数 | 46 |
| Lib024 | 1024 | 库函数 | 14 |
结论:
实验后,回顾最初的猜想:
系统调用的性能较库函数高,所以,性能上:Syst > Lib;
读取字节数小的时间效率将高于读取字节数大的时间效率,所以,时间上: T(1) < T(1024)
那么,猜想结论:
Lib1024 > Syst1024 > Lib1 > Syst1 (耗时)
然而,实际实验结论是:
Lib1 > Lib1024 >> Syst1 > Syst1024(耗时)
发现,猜想仅仅正确一半。
字节数小的时间效率反而远远高于读取字节数大的时间效率,且系统调用的效率远远高于之前对系统调用与库函数调用的想象。
实验数据显示,分别比较读取1字节和读取1024字节在系统调用组,库函数组的时间效率:
Lib1 ~= 754.098 * Syst1 (时间效率比较:754.098倍)
Lib1024 = 7000 * Syst1024 (时间效率比较:7000倍)
对于系统调用与库函数之间的效率差距,在查阅相关文献后,得知大致原因如下:
要实现文件拷贝,必须嵌入内核,从磁盘读取文件内容,然后存储到另一个文件。
实现文件拷贝最通常的做法是:
读取文件用系统调用read()函数,读取到一定长度的连续的用户层缓冲区,然后使用write()函数将缓冲区内容写入文件。也可以用标准库函数fread()和fwrite(),但这两个函数最终还是通过系统调用read()和write()实现拷贝的,因此可以归为一类(不过效率肯定没有直接进行系统调用的高)。一个更高级的做法是使用虚拟存储映射技术进行,这种方法将源文件以共享方式映射到虚拟存储器中,目的文件也以共享方式映射到虚拟地址空间中,然后使用memcpy高效地将源文件内容复制到目的文件中。
实验数据显示,分别比较系统调用组,库函数组在读取1字节和读取1024字节的时间效率:
Syst1 = 30.5 * Syst1024 (时间效率比较:30.5倍)
Lib1 ~= 3.286 * Lib1024 (时间效率比较:约3.3倍)
对于单(低)字节与多(更多)字节之间的时间效率差距,查阅相关资料无效后,个人揣测原因如下:(仍存在疑问)
本来系统读取数据的缓存区是较大的,可以读取多个字节数据,这样能够解释为何多(更多)字节数据的读取高的原因。又由于读取单(低)字节,需要系统额外地设置和读取缓存区,导致比读取更多字节更高的时间开销,所以单(低)字节的效率便低于多字节的时间效率了。
参考文献:
[原创]
[C++]Linux之文件拷贝在系统调用和C库函数下的效率比较的更多相关文章
- Linux C 文件操作,系统调用 -- open()、read() 和 标准I/O库 -- fopen()、fread()
函数汇总: open().write().read().close() fopen().fwrite().fread().fclose() 一.什么是文件 在讲述文件操作之前,我们首先要知道什么是文件 ...
- 【Linux】文件操作函数(系统调用函数)
重点在于学习--思路与方法 举一反三 一.文件描述符 系统分配给文件的数字编号 二.函数学习 P.S.Man命令使用方法 manual 前三个章节 命令:系统调用函数:库函数 man read //r ...
- 【Linux】文件拷贝-Linux当前目录所有文件移动到上一级目录(转)
Linux当前目录所有文件移动到上一级目录 mv * ../
- Linux 删除文件未释放空间问题处理,下清空或删除大文件
linux里的文件被删除后,空间没有被释放是因为在Linux系统中,通过rm或者文件管理器删除文件将会从文件系统的目录结构上解除链接(unlink).然而如果文件是被打开的(有一个进程正在使用),那么 ...
- Linux打开文件设置
在某些情况下会要求增加Linux的文件打开数,以增加服务器到处理效率,在Linux下查看最多能打开的文件数量为: cat /proc/sys/fs/file-max 然后设置ulimit -n 文件数 ...
- linux复制文件并修改文件名
#!/bin/bash #复制/casnw/backup/db203oradata/目录下的所有后缀名为dmp的文件拷贝到/casnw/backup/dbmonthbak 目录下cp -f /casn ...
- Linux C高级编程——文件操作之系统调用
Linux C高级编程文件操作之系统调用 宗旨:技术的学习是有限的,分享的精神是无限的. 库函数是一些完毕特定功能的函数.一般由某个标准组织制作公布,并形成一定的标准.使用库函数编 ...
- Linux系统下远程文件拷贝scp命令
在Linux系统下,不同机器上实现文件拷贝 一.将本地文件拷贝到远程机器: scp /home/administrator/news.txt root@192.168.6.129:/etc/squid ...
- Linux下不同机器之间的文件拷贝
通过 scp 命令实现不同机器之间的文件拷贝. (1)本机考到目标机器:scp 本机文件 目的地: 如:scp /home/odp-web.war root@192.168.6.137:/usr/ ...
随机推荐
- 在 Docker 中使用 mysql 的一些技巧
启动到后台: docker-compose start docker-composer 执行命令: entrypoint: pwd app: build: ./app working_dir: /a ...
- 洛谷P2150 寿司晚宴
解:发现每个质数只能属于一个人,于是想到每个质数有三种情况:属于a,属于b,都不属于. 然后考虑状压每个人的质数集合,可以得到30分. 转移就是外层枚举每个数,内层枚举每个人的状态,然后看能否转移.能 ...
- 代码合并工具Beyond Compare的使用技巧
使用技巧 文件合并 过滤 https://edi.wang/post/2013/2/17/using-beyond-compare 文件夹比较 http://www.beyondcompare.cc/ ...
- bzoj1791[IOI2008]Island岛屿(基环树+DP)
题目链接:https://www.lydsy.com/JudgeOnline/problem.php?id=1791 题目大意:给你一棵n条边的基环树森林,要你求出所有基环树/树的直径之和.n< ...
- prototype 与 proto的关系是什么:
__proto__是什么? 我们在这里简单地说下.每个对象都会在其内部初始化一个属性,就是__proto__,当我们访问一个对象的属性 时,如果这个对象内部不存在这个属性,那么他就会去__proto_ ...
- java参数可变方法
java中允许一个方法中存在多个参数 public class Parmvarexmple { //参数可变的方法 public int sum(int...n) { int tempSum=0; f ...
- 数据库日志redo和undo
数据库的ACID属性 Atomicity:原子性,以事物transact为最小单位,事物中的所有操作,要么都执行完,要么都不执行,不存在一部分操作执行,另一部分操作不执行的情况. Consistenc ...
- Redis的主从复制的原理介绍
redis主从复制 和Mysql主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况.为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或 ...
- node.js小案例_留言板
一.前言 通过这个案例复习: 1.node.js中模板引擎的使用 2.node.js中的页面跳转和重定向 二.主要内容 1.案列演示: 2.案列源码:https://github.com/45612 ...
- Linux设备树(二 节点)
二 节点(node)的表示 首先说节点的表示方法,除了根节点只用一个斜杠“/”表示外,其他节点的表示形式如“node-name@unit-address”.@前边是节点名字,后边是节点地址.节点名字的 ...