HBase篇(1)-特性与应用场景
【每日五分钟搞定大数据】系列,HBase第一篇
结束了Zookeeper篇, 接下来我们来说下Google三驾马车之一BigTable的开源实现:HBase,要讲的内容暂定如下:

这是第一篇我们先不聊技术实现,只讨论特性和场景
hbase的特点
- 千万级高并发
- PB级存储
- 非结构化存储
- 动态列,稀疏列
- 支持二级索引
- 强一致性,可靠性,扩展性(CP系统,可用性做了一点让步)
场景
1. 写密集型应用,每天写入量巨大,而相对读数量较小的应用
2. 不需要复杂查询条件来查询数据的应用
使用rowkey,单条记录或者小范围的查询性能不错,大范围的查询由于分布式的原因,可能在性能上有点影响。
使用HBase的过滤器的话性能比较差。
3. 不需要关联的场景,HBase为NoSQL无法支持join
4. 可靠性要求高
master支持主备热切。
regionServer宕机,region会分配给在线的机器。
数据持久化在HDFS,默认3份,HDFS保证数据可靠性。
内存的数据若丢失可以通过Wal预写日志恢复。
5. 数据量较大,而且增长量无法预估的应用
HBase支持在线扩展,即使在一段时间内数据量呈井喷式增长,也可以通过HBase横向扩展来满足功能。
应用
- 对象存储系统
HBase MOB(Medium Object Storage),中等对象存储是hbase-2.0.0版本引入的新特性,用于解决hbase存储中等文件(0.1m~10m)性能差的问题。这个特性适合将图片、文档、PDF、小视频存储到Hbase中。
- OLAP的存储
Kylin的底层用的是HBase的存储,看中的是它的高并发和海量存储能力。kylin构建cube的过程会产生大量的预聚合中间数据,数据膨胀率高,对数据库的存储能力有很高要求。
Phoenix是构建在HBase上的一个SQL引擎,通过phoenix可以直接调用JDBC接口操作Hbase,虽然有upsert操作,但是更多的是用在OLAP场景,缺点是非常不灵活。
- 时序型数据
openTsDB应用,记录以及展示指标在各个时间点的数值,一般用于监控的场景,是HBase上层的一个应用。
- 用户画像系统
动态列,稀疏列的特性。用于描述用户特征的维度数是不定的且可能会动态增长的(比如爱好,性别,住址等);不是每个特征维度都会有数据
- 消息/订单系统
强一致性,良好的读性能,至于hbase如何保证强一致性的后面的文章会详细说明。
- feed流系统存储
见下面的一波分析。
feed流系统
前几天据说支持八个一线明星并发出轨的微博挂了....蹭个热度,上面的系统我就不一一说了,大家应该知道微博是典型的feed流系统,那我们来详细说下feed流系统。
什么是feed流系统
feed流系统有三个概念,如图(来自云栖社区)
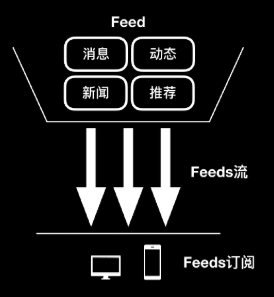
feed:
一个终端发布的一些内容
- 可以是用户发布的动态消息
- 可以是广告系统推荐的广告
- 也可以是系统本身推荐的一些公告
比如你在微博发了条动态,那这条动态就是feed
feeds流;
feeds流就是系统实时推送的根据了一定规则排序的信息流
比如你刷了下微博,在你的首页出现了按时间排好序的一堆新消息,那这就是feed流
feeds订阅;
这个比较简单,就是你通过应用,微博,朋友圈这些,关注了某个人,那就是订阅了Ta的feeds
Feed流系统的存储
Feed流系统中需要存储的内容大致可以分为两部分,
- 账号关系数据(比如关注列表)
- Feed消息内容
其实有很多方案实现,但是这篇说的是HBase,那我们就说说如何用HBase实现。
关注列表
关注列表就不重点讨论了,数据特点是:列数量不定,量大,关系简单,有序,性能要求高,可靠性要求高。互相关注,单向关注这种场景用二级索引很好实现。
Feed消息
数据的特点:
1.读多写少,举个栗子,看我文章的人里面有多少人是暗中观察的,不评论不点赞自己也不发文章的,这样“暗中观察”的同学占总用户的比例是很大的。
2.数据模型简单,消息时间,消息体,发布人,订阅人,很少会有需要关联的场景
3.高并发,波峰波谷式访问,Feed流系统属于社交类系统,热点来得快去得也快。
4.持久化可靠性存储
每个人发布的内容都是需要永久存储且不能丢失的,存储量会随着时间的推移会越来越大。需要系统有很强的扩展性和可靠性。
5.消息排序,HBase的rowKey按字典序排序正好适用于这个场景。比如rowkey可以设计成这样
<userId><timestamp><feedId>这样获取某个用户发布的消息时就可以指定时间范围来scan,性能不错的同时还能保证时间线正确。
总结
从上面feed数据的特性可以看出,HBase是适合做feed流系统的,实际生产中也确实有feed流应用是用HBase来做的存储,
我这里只是一个初步的讨论,实际上还是有很多细节要考虑的,光靠HBase来实现肯定是远远不够的,它也有很多不适用的地方,要靠开发者自己去判断,
没有最好的只有最合适的,希望对大家有帮助。

HBase篇(1)-特性与应用场景的更多相关文章
- 《HBase在滴滴出行的应用场景和最佳实践》
HBase在滴滴出行的应用场景和最佳实践 背景 对接业务类型 HBase是建立在Hadoop生态之上的Database,源生对离线任务支持友好,又因为LSM树是一个优秀的高吞吐数据库结构,所以同时 ...
- 二、RabbitMQ 进阶特性及使用场景 [.NET]
前言 经过上一篇的介绍,相信大家对RabbitMQ 的各种概念有了一定的了解,及如何使用RabbitMQ.Client 去发送和消费消息. 特性及使用场景 1. TTL 过期时间 TTL可以用来指定q ...
- 解剖SQLSERVER 第七篇 OrcaMDF 特性概述(译)
解剖SQLSERVER 第七篇 OrcaMDF 特性概述(译) http://improve.dk/orcamdf-feature-recap/ 时间过得真快,这已经过了大概四个月了自从我最初介绍我 ...
- HBase指定大量列集合的场景下并发拉取数据时卡住的问题排查
最近遇到一例,HBase 指定大量列集合的场景下,并发拉取数据,应用卡住不响应的情形.记录一下. 问题背景 退款导出中,为了获取商品规格编码,需要从 HBase 表 T 里拉取对应的数据. T 对商品 ...
- Redis高级特性及应用场景
Redis高级特性及应用场景 redis中键的生存时间(expire) redis中可以使用expire命令设置一个键的生存时间,到时间后redis会自动删除它. 过期时间可以设置为秒或者毫秒精度. ...
- HBase篇(5)- BloomFilter
[每日五分钟搞定大数据]系列,HBase第五篇.上一篇我们落下了Bloom Filter,这次我们来聊聊这个东西. Bloom Filter 是什么? 先简单的介绍下Bloom Filter(布隆过滤 ...
- HBase篇(3)-架构详解
[每日五分钟搞定大数据]系列,HBase第三篇 聊完场景和数据模型我们来说下HBase的架构,在网上找了张比较清晰的图,我觉得这张图能说明很多问题,那这一篇我们就重点来解析下这张图 角色与职责 先介绍 ...
- HBase在滴滴出行的应用场景和最佳实践
摘要: 主要介绍了HBase和Phoenix在滴滴内部的一些典型案例.文章已在CSDN极客头条和<程序员>杂志发表,应朋友邀请,分享到云栖社区,希望给大家带来启发和帮助. 背景 对接业务类 ...
- 一条数据的HBase之旅,简明HBase入门教程3:适用场景
[摘要] 这篇文章继HBase数据模型之后,介绍HBase的适用场景,以及与一些关键场景有关的周边技术生态,最后给出了本文的示例数据 华为云上的NoSQL数据库服务CloudTable,基于Apach ...
随机推荐
- 关于最新笔记本机型预装win8如何更换为win7的解决办法
关于最新笔记本机型预装win8如何更换为win7的解决办法 目前新出的很多机型出厂自带的都是win8系统,可能有些人用不习惯,想更换为win7系统,但是由于这些机型主板都采用UEFI这种接口(硬盘分区 ...
- 第一次使用VS Code时你应该知道的一切配置
前言 本文最新内容将在GitHub上实时更新. VS Code 本来是前端人员专用,但由于它实在是太好用了,于是,各种开发方向的码农也正在用 VS Code 作为他们的主力编程工具.甚至是一些写作的同 ...
- 商品描述里包含了英文双引号,ERP无法同步菜品信息
1. 2.因菜品描述里包含英文双引号,破坏了json格式,导致json格式错乱,ERP无法解析,所以无法同步数据.
- linux文件统计命令和目录统计命令
1.统计本目录下除`./apps/myapp/migrations`的所有py文件 wc -l `find -path . -o -name '*py' ! -path "./apps/my ...
- [20190312]关于增量检查点的疑问(补充).txt
[20190312]关于增量检查点的疑问(补充).txt --//有人问我以前写一个帖子的问题,关于增量检查点的问题,链接如下:http://blog.itpub.net/267265/viewspa ...
- MySQL Host is blocked because of many connection errors 解决方法
应用日志提示错误:create connection error, url: jdbc:mysql://10.45.236.235:3306/db_wang?useUnicode=true&c ...
- 转:EditPuls 5.0 注册码
EditPlus5.0注册码 注册名 Vovan 注册码 3AG46-JJ48E-CEACC-8E6EW-ECUAW EditPlus3.x注册码 EditPlus注册码生成器链接 http://ww ...
- python 实现网页 自动登录
完整代码: 1 from apscheduler.schedulers.blocking import BlockingScheduler 2 from selenium import webdriv ...
- 常用判断重复记录的SQL语句
1.查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断select * from people where peopleId in (select peopleId fro ...
- 磁盘性能评价指标—IOPS和吞吐量
转:http://blog.csdn.net/hanchengxi/article/details/19089589 一.磁盘 I/O 的概念 I/O 的概念,从字义来理解就是输入输出.操作系统从上层 ...