使用Autoencoder进行降维
#coding=utf-8
import tensorflow as tf
import matplotlib.pyplot as plt from tensorflow.examples.tutorials.mnist import input_data
#需要自己从网上下载Mnist数据集
mnist = input_data.read_data_sets("D:/MNIST", one_hot=False) learning_rate = 0.01
training_epochs = 10
batch_size = 256
display_step = 1
n_input = 784
X = tf.placeholder("float", [None, n_input]) n_hidden_1 = 128
n_hidden_2 = 64
n_hidden_3 = 10
n_hidden_4 = 2
weights = {
'encoder_h1': tf.Variable(tf.truncated_normal([n_input, n_hidden_1], )),
'encoder_h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2], )),
'encoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3], )),
'encoder_h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4], )),
'decoder_h1': tf.Variable(tf.truncated_normal([n_hidden_4, n_hidden_3], )),
'decoder_h2': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_2], )),
'decoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_1], )),
'decoder_h4': tf.Variable(tf.truncated_normal([n_hidden_1, n_input], )),
}
biases = {
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),
} def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
# 为了便于编码层的输出,编码层随后一层不使用激活函数
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4 def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4 encoder_op = encoder(X)
decoder_op = decoder(encoder_op) y_pred = decoder_op
y_true = X
#使用平均误差最小化损失函数
cost = tf.reduce_mean(tf.pow(y_true - y_pred, 2))
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost) with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
total_batch = int(mnist.train.num_examples / batch_size)
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, c = sess.run([optimizer, cost], feed_dict={X: batch_xs})
if epoch % display_step == 0:
print("Epoch:", '%04d' % (epoch + 1), "cost=", "{:.9f}".format(c))
print("Optimization Finished!")
encoder_result = sess.run(encoder_op, feed_dict={X: mnist.test.images})
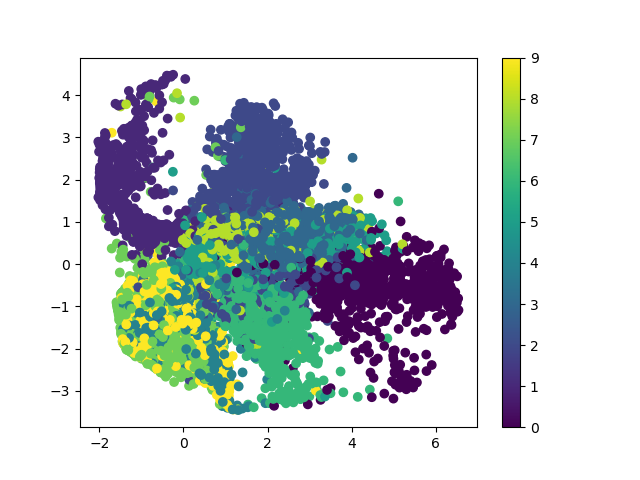
plt.scatter(encoder_result[:, 0], encoder_result[:, 1], c=mnist.test.labels)
plt.colorbar()
plt.show()
结果:每一种颜色代表一种数字,这里是为了可视化才降到2维的,但是实际降维的时候,肯定不会把维度降到这么低的水平。
使用Autoencoder进行降维的更多相关文章
- CNN autoencoder 先降维再使用kmeans进行图像聚类 是不是也可以降维以后进行iforest处理?
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers ...
- 论文阅读 dyngraph2vec: Capturing Network Dynamics using Dynamic Graph Representation Learning
6 dyngraph2vec: Capturing Network Dynamics using Dynamic Graph Representation Learning207 link:https ...
- keras使用AutoEncoder对mnist数据降维
import keras import matplotlib.pyplot as plt from keras.datasets import mnist (x_train, _), (x_test, ...
- PRML读书会第十二章 Continuous Latent Variables(PCA,Principal Component Analysis,PPCA,核PCA,Autoencoder,非线性流形)
主讲人 戴玮 (新浪微博: @戴玮_CASIA) Wilbur_中博(1954123) 20:00:49 我今天讲PRML的第十二章,连续隐变量.既然有连续隐变量,一定也有离散隐变量,那么离散隐变量是 ...
- 降噪自动编码器(Denoising Autoencoder)
起源:PCA.特征提取.... 随着一些奇怪的高维数据出现,比如图像.语音,传统的统计学-机器学习方法遇到了前所未有的挑战. 数据维度过高,数据单调,噪声分布广,传统方法的“数值游戏”很难奏效.数据挖 ...
- Deep Learning 16:用自编码器对数据进行降维_读论文“Reducing the Dimensionality of Data with Neural Networks”的笔记
前言 论文“Reducing the Dimensionality of Data with Neural Networks”是深度学习鼻祖hinton于2006年发表于<SCIENCE > ...
- Autoencoder
AutoencoderFrom Wikipedia An autoencoder, autoassociator or Diabolo network[1]:19 is an artificial n ...
- Deep learning:三十四(用NN实现数据的降维)
数据降维的重要性就不必说了,而用NN(神经网络)来对数据进行大量的降维是从2006开始的,这起源于2006年science上的一篇文章:reducing the dimensionality of d ...
- 一周总结:AutoEncoder、Inception 、模型搭建及下周计划
一周总结:AutoEncoder.Inception .模型搭建及下周计划 1.AutoEncoder: AutoEncoder: 自动编码器就是一种尽可能复现输入信号的神经网络:自动编码器必须捕 ...
随机推荐
- 04bootstrap_表单
03bootstrap_表单 表单的基本实例 1.默认表单:form 表单域 fieldset legend label 提示span class="help-block" 2.基 ...
- PTA1
1-1 数组定义中,数组名后是用方括号括起来的常量表达式,不能用圆括号. (1分) [T ] F 1-2 在C语言中能逐个地使用下标变量,也能一次引用整个数组. (1分) T [F]因为它有首地址 1 ...
- dispatherServlet拦截所有请求,但是不拦截JSP和其他配置的servelt
不是顺序问题,是就不拦截Servlet 不是load-on-startup启动先后顺序问题,是就是不拦截Servlet. SpringMVC默认用的是第二个 //<url-pattern> ...
- mysql根据某个字符串拆分表中的字段,然后赋值给另外一个字段
sql语句示例: UPDATE user_info SET area_code = SUBSTRING_INDEX(telphone,'-',1) SUBSTRING_INDEX函数说明: subs ...
- Firebird Embedded 部署的一个坑
今天把旧程序升级了,把DBX组件换成了FireDac组件,在虚拟机里测试的时候,一直报上图中的错误,但是在主机上运行无问题,之前用户使用也一直没报过这个错. 折腾了又折腾,还是搞不定,感觉脑袋有点大了 ...
- angular2 ngfor循环
angular2 在组件模板中可以循环数组集合等对象,语法非常简单,如: <ng-container *ngFor="let item of model.list"> ...
- Robot Framework脚本在jenkins执行完之后无法查看日志
首先确保Robot Framework Plugin已经安装好,构建结束后test result和log.html等日志文件已显示,只是无法打开查看: 修改tomcat配置:vi tomcat/con ...
- js赋值后,不影响源变量的方法。
以前都没发现这个问题,特记录一下. var productListData={pages:001}; var data=productListData;//这样就会有问题. data=$.extend ...
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- LINUX系统软件安装和卸载的常见方法
linux系统分很多种简单介绍几种常用的: 1.centos/redhat: 安装: rpm安装,如果有依赖,很闹心,如果使用--nodeps不检查依赖,会有问题. #rpm -ivh <XXX ...