python词频统计及其效能分析
1) 博客开头给出自己的基本信息,格式建议如下:
- 学号2017****7128
- 姓名:肖文秀
- 词频统计及其效能分析仓库:https://gitee.com/aichenxi/word_frequency1
2) 程序分析,对程序中的四个函数做简要说明。要求附上每一段代码及对应的说明。
process_file作用:打开文件,读取文件到缓冲区,关闭文件
# 读文件到缓冲区
def process_file(file_name):
try:
# 打开文件
file_read=open(file_name,"r")
except IOError as s:
print (s)
return None
try:
# 读文件到缓冲区
bvffer=file_read.read()
except:
print ("Read File Error!")
return None
#关闭文件
file_read.close()
return bvffer
process_buffer作用:读取文件存入字典,处理读取文件时的大小写、符号问题。统计单词出现频率
#缓冲区字符串分割成带有词频的字典
def process_buffer(bvffer):
if bvffer:
word_freq = {}
# 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
#将文件大写字母替换为小写 ,解决大小写不同问题
bvffer=bvffer.lower()
#将文件中所有替换为标点符号替换为空格
for i in '.,!?':
bvffer=bvffer.replace(i, " ")
#通过空格切分单词,存储类型为列表
words=bvffer.strip().split()
#遍历列表中所有单词,设字典中value=0,
for word in words:
#判断是否在字典中,若在,value+1,否则,value=0
if word in word_freq:
word_freq[word] += 1
else:
word_freq[word] = 0
return word_freq
output_result作用:输出出现频率前10的单词
#将字典按词频排序并输出排名前十的词频对
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]: # 输出 Top 10 的单词
print(item)
main作用:封装主函数,传入文件名称,调用定义函数,并对其传入参数
if __name__ == "__main__":由于使用原本的代码报错,现将原代码改为如下代码
def main():
#指定文件
file_name = "Gone_with_the_wind.txt"
#调用定义函数、传参数
bvffer = process_file(file_name)
word_freq = process_buffer(bvffer)
output_result(word_freq)
if __name__ == "__main__":
#导入分析Python程序性能监视模块
import cProfile
#导入用来分析cProfile输出的文件内容
import pstats
# 直接把分析结果打印到控制台
cProfile.run("main()", "result")
# 创建Stats对象
p = pstats.Stats("result")
# 按照调用的次数排序
p.strip_dirs().sort_stats("call").print_stats()
# 按照运行时间和函数名进行排序
#p.strip_dirs().sort_stats("cumulative", "name").print_stats(0.5)
3) 性能分析结果及改进。
共执行21831次,用时0.657秒
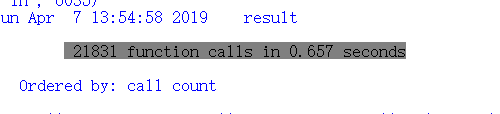
其中执行次数最多的代码:

执行时间最长的代码:
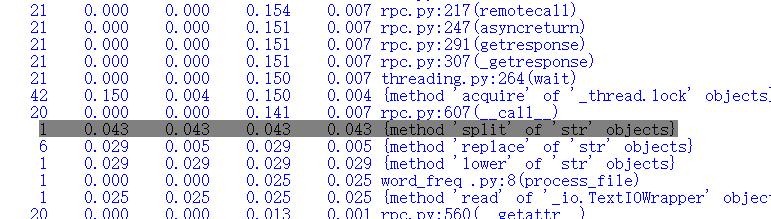
- 给出改进优化方法,根据方法的正确性以及语言描述质量给分,最高2分
问题:输出结果中包含标点符号:”

- 给出改进代码
#将文件中非字母替换为空格
for i in [chr(x) for x in range(ord('a'), ord('z') + 1)]:
if i:
continue
else:
bvffer=bvffer.replace(i, " ")
运行结果:

4) 程序运行命令、运行结果截图以及改进后的程序运行命令及结果截图 。
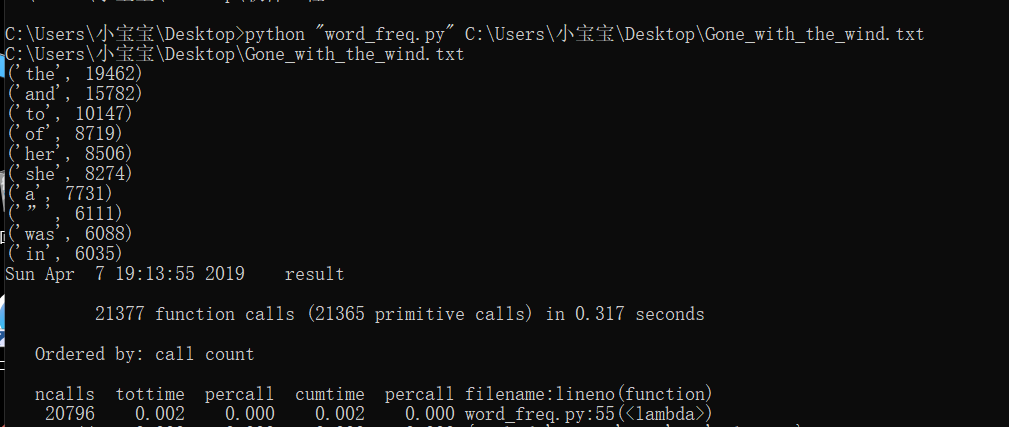
改进前,运行结果
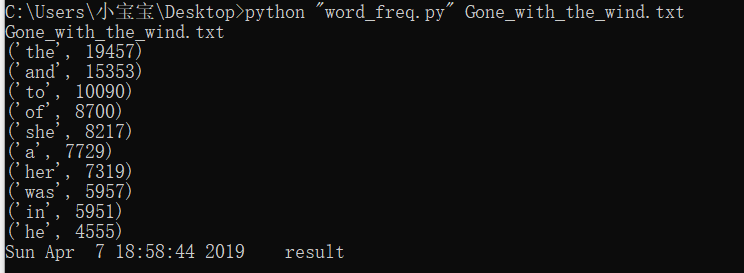
改进后,运行结果
5) 给出你对此次任务的总结与反思。
反思:在此次任务的中,认识到对字符串的处理有很多遗忘的地方,对字典、列表、数组的使用能力有待加强。
总结:在完成任务的同时,也捧起书,复习了基本数据类型相关的知识,重温了python的文件式启动与运行方法
python词频统计及其效能分析的更多相关文章
- Python 词频统计
利用Python做一个词频统计 GitHub地址:FightingBob [Give me a star , thanks.] 词频统计 对纯英语的文本文件[Eg: 瓦尔登湖(英文版).txt]的英文 ...
- python实现四则运算和效能分析
代码github地址:https://github.com/yiduobaozhi/-1 PSP表格: 预测时间(分钟) planning 计划 15 Estimate 估计这个任务需要多少时间 10 ...
- 大数据python词频统计之本地分发-file
统计某几个词在文章出现的次数 -file参数分发,是从客户端分发到各个执行mapreduce端的机器上 1.找一篇文章The_Man_of_Property.txt如下: He was proud o ...
- 大数据python词频统计之hdfs分发-cacheArchive
-cacheArchive也是从hdfs上进分发,但是分发文件是一个压缩包,压缩包内可能会包含多层目录多个文件 1.The_Man_of_Property.txt文件如下(将其上传至hdfs上) ha ...
- 大数据python词频统计之hdfs分发-cacheFile
-cacheFile 分发,文件事先上传至Hdfs上,分发的是一个文件 1.找一篇文章The_Man_of_Property.txt: He was proud of him! He could no ...
- python词频统计
1.jieba 库 -中文分词库 words = jieba.lcut(str) --->列表,词语 count = {} for word in words: if len(word)==1 ...
- C#词频统计 效能分析
在邹老师的效能分析的建议下对上次写过的词频统计的程序进行分析改进. 效能分析:个人很浅显的认为就是程序的运行效率,代码的执行效率 1.VS 提供了自带的分析工具:performance tool (性 ...
- 效能分析——词频统计的java实现方法的第一次改进
java效能分析可以使用JProfiler 词频统计处理的文件为WarAndPeace,大小3282KB约3.3MB,输出结果到文件 在程序本身内开始和结束分别加入时间戳,差值平均为480-490ms ...
- 《构建之法》教学笔记——Python中的效能分析与几个问题
<构建之法:现代软件工程>中第2章对效能分析进行了介绍,基于的工具是VSTS.由于我教授的学生中只有部分同学选修了C#,若采用书中例子讲解,学生可能理解起来比较困难.不过所有这些学生都学习 ...
随机推荐
- [WebService].net中WebService的使用实例
.net中WebService的使用实例 一.创建一个Webwebservice 1.新建一个项目WebserverDemo 2.在项目处添加新建项,添加一个web服务 3.编辑TestServer. ...
- let const区别!
这次做项目在申明变量的时候用到let const 总结下这两个区别 : 首先 let与const都是只在声明所在的块级作用域内有效. let声明的变量可以改变,值和类型都可以改变,没有限制.const ...
- css修改整个项目的滚动条样式
在项目中,滚动条不可避免的药出现.设置统一规范的滚动条也是必然.用一个独立的css文件即可修改整个项目中的滚动条样式 . scrollBar.css: /* 滚动条有滑块的轨道部分 */ ::-web ...
- PHP大神必须养成的十大优良习惯
1.多阅读手册和源代码 没什么比阅读手册更值得强调的事了–仅仅通过阅读手册你就可以学习到很多东西,特别是很多有关于字符串和数组的函数.就在这些函数里面包括许多有用 的功能,如果你仔细阅读手册,你会经常 ...
- PHP语言入门的学习方法十要素
对于PHP程序设计语言来说.每个人的学习方式不同,写这篇文章的目的是分享一下自己的学习过程,仅供参考,不要一味的用别人的学习方法,找对自己有用的学习方式.经常在某些论坛和QQ群里看到一些朋友会问“怎样 ...
- Anatomy of a Database System学习笔记 - 存储管理
使用裸设备,还是使用文件系统? 描述 pros cons 裸设备 顺序读磁盘快比随机要快10-100倍,DB比OS更懂磁盘负载,因此很多DB是直接管理数据块如何存放的. DB对裸设备的管理,比文件 ...
- Django自定义模板标签和过滤器
1.创建模板库 在某个APP所在目录下新建包templatetags,然后在其中创建存储标签或者过滤器的的模块,名称随意,例如myfilters.py. 在这个模块中编写相关代码. 注意:templa ...
- 如何用jquery获取form表单的值
$(function(){ $('.btn').click(function(){ alert($('#form').serialize()); }) }) 这样就获取到了 #form的值.
- c#_生成图片式验证码
废话不多说直接上代码. class Check_Code { /// <summary> /// 生成随机验证码数字+字母 /// </summary> /// <par ...
- java并发编程概念
并发:当有多个线程在操作时,如果系统只有一个CPU,则它根本不可能真正同时进行一个以上的线程,它只能把CPU运行时间划分成若干个时间段,再将时间 段分配给各个线程执行,在一个时间段的线程代码运行时,其 ...