用 Python 监控知乎和微博的热门话题
前言
文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: TED Crossin的编程教室
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
知乎热榜中的内容热度值,是根据该条内容近24小时内的浏览量、互动量、专业加权、创作时间及在榜时间等维度,综合计算得出的。知乎热榜即根据内容热度值制定的排行榜。
微博的热度值是根据该篇微博被转发、点赞数和微博发布时间等各项因素,来算出热度基数,再与热度权重相加,得出最终的热度值。微博热门即话题热度排行榜。

今天我们要做的就是将相关排行榜中的话题内容爬取下来当作数据素材。换句话说,我们要把页面上排好的信息,通过代码读取并保存起来。
1. 爬取网页内容
Python 爬虫通常采用 requests 库来处理网络请求。这里关于 requests 的方法和参数暂不展开。
知乎热榜

微博热门
这里有两点要注意:
1、我们选用的网址链接在未登录状态下也可访问,因此 requests 方法中的参数为空也不影响。但爬虫时更多的情况是需要登陆状态,因此也就要求通过设置不同参数来模拟登陆去进行相关操作。 2、通过 requests 模块获取的网页内容,对应的是在网站上右键单击,选择“显示网页源代码”后展现的页面。它与我们实际看到的网页内容或者 F12 进入开发者模式中看到的网页 elements 是不同的。前者是网络请求后返回结果,后者是浏览器对页面渲染后结果。
2. 解析爬到的内容
第一步爬到的是整个页面内容,接下来要在所有内容中去对目标定位,然后将其读取并保存起来。
这里我采用的是 BeautifulSoup,因为学爬虫最先接触这个,用起来也蛮顺手。通过 BeautifulSoup 提供的方法和参数,可以很便捷定位到目标。
在知乎热榜的网页源代码中,拉到最下方可以看到如下:
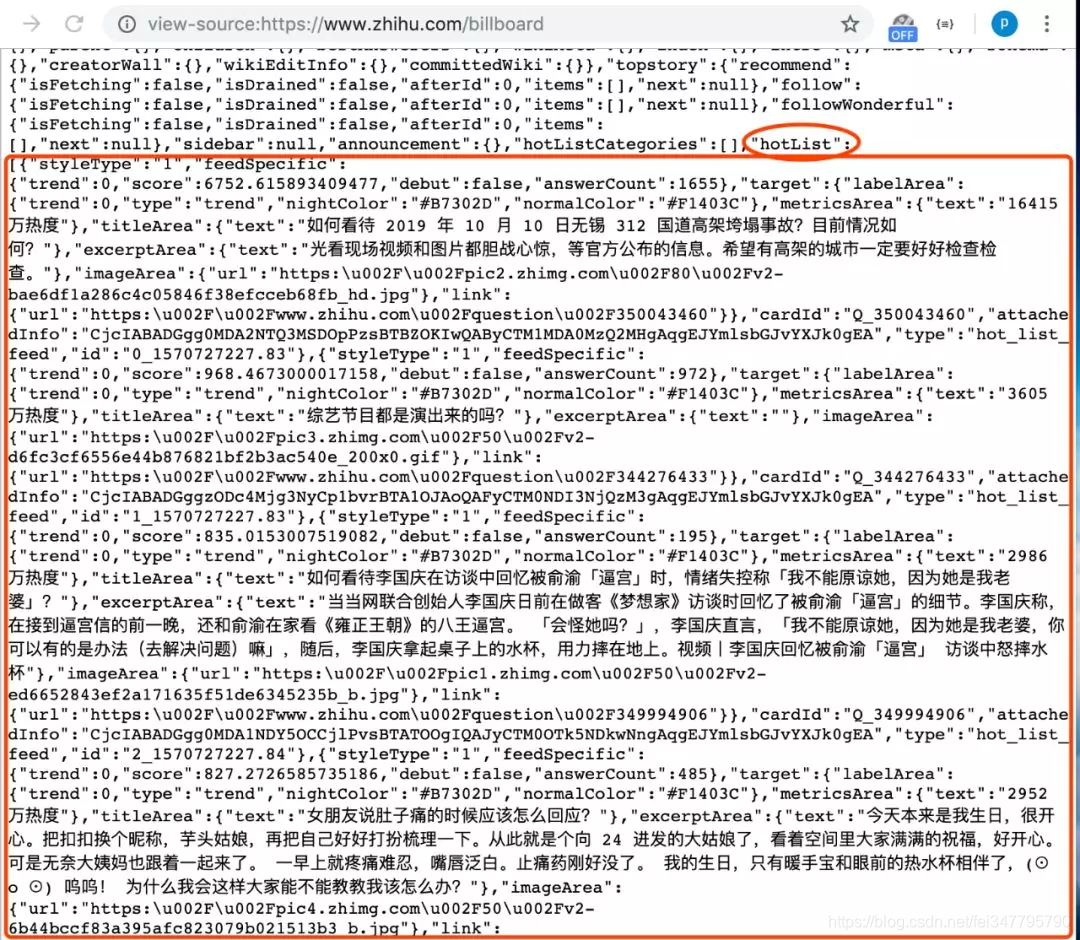
在源代码中网页的 script 部分,有现成的整理好的热榜数据。所以我们为了减少工作量,直接通过 BeautifulSoup 取出 script 中内容,再用正则表达式匹配热榜数据列表处的内容。
import requests
import re
from bs4 import BeautifulSoup
headers={"User-Agent":"","Cookie":""}
zh_url = "https://www.zhihu.com/billboard"
zh_response = requests.get(zh_url,headers=headers)
webcontent = zh_response.text
soup = BeautifulSoup(webcontent,"html.parser")
script_text = soup.find("script",id="js-initialData").get_text()
rule = r'"hotList":(.*?),"guestFeeds"'
result = re.findall(rule,script_text)
temp = result[0].replace("false","False").replace("true","True")
hot_list = eval(temp)
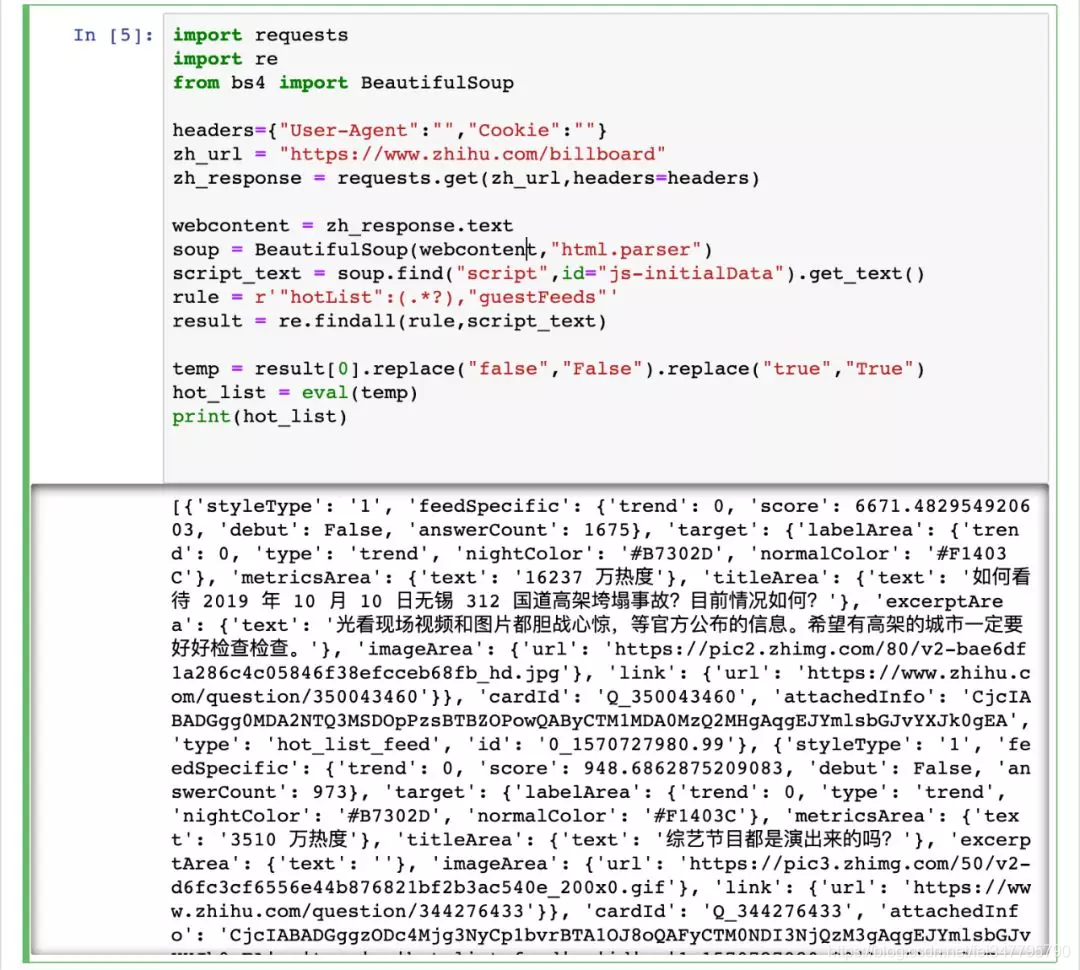
print(hot_list)
这里我利用了 script 中热榜数据的列表结构,在定位取出相关字符串后,先将 js 中的 true 和 false 转化为 Python 中的 True 和 False,最后直接通过 eval() 来将字符串转化为直接可用的数据列表。
运行代码结果如图:
至于对微博热门的解析,就是中规中矩地利用 BeautifulSoup 来对网页元素进行定位获取:
import requests
from bs4 import BeautifulSoup
url = "https://s.weibo.com/top/summary"
headers={"User-Agent":"","Cookie":""}
wb_response = requests.get(url,headers=headers)
webcontent = wb_response.text
soup = BeautifulSoup(webcontent,"html.parser")
index_list = soup.find_all("td",class_="td-01")
title_list = soup.find_all("td",class_="td-02")
level_list = soup.find_all("td",class_="td-03")
topic_list = []
for i in range(len(index_list)):
item_index = index_list[i].get_text(strip = True)
if item_index=="":
item_index = ""
item_title = title_list[i].a.get_text(strip = True)
if title_list[i].span:
item_mark = title_list[i].span.get_text(strip = True)
else:
item_mark = "置顶"
item_level = level_list[i].get_text(strip = True)
topic_list.append({"index":item_index,"title":item_title,"mark":item_mark,"level":item_level,"link":f"https://s.weibo.com/weibo?q=%23{item_title}%23&Refer=top"})
print(topic_list)
通过解析,将微博热门数据逐条存入列表中:
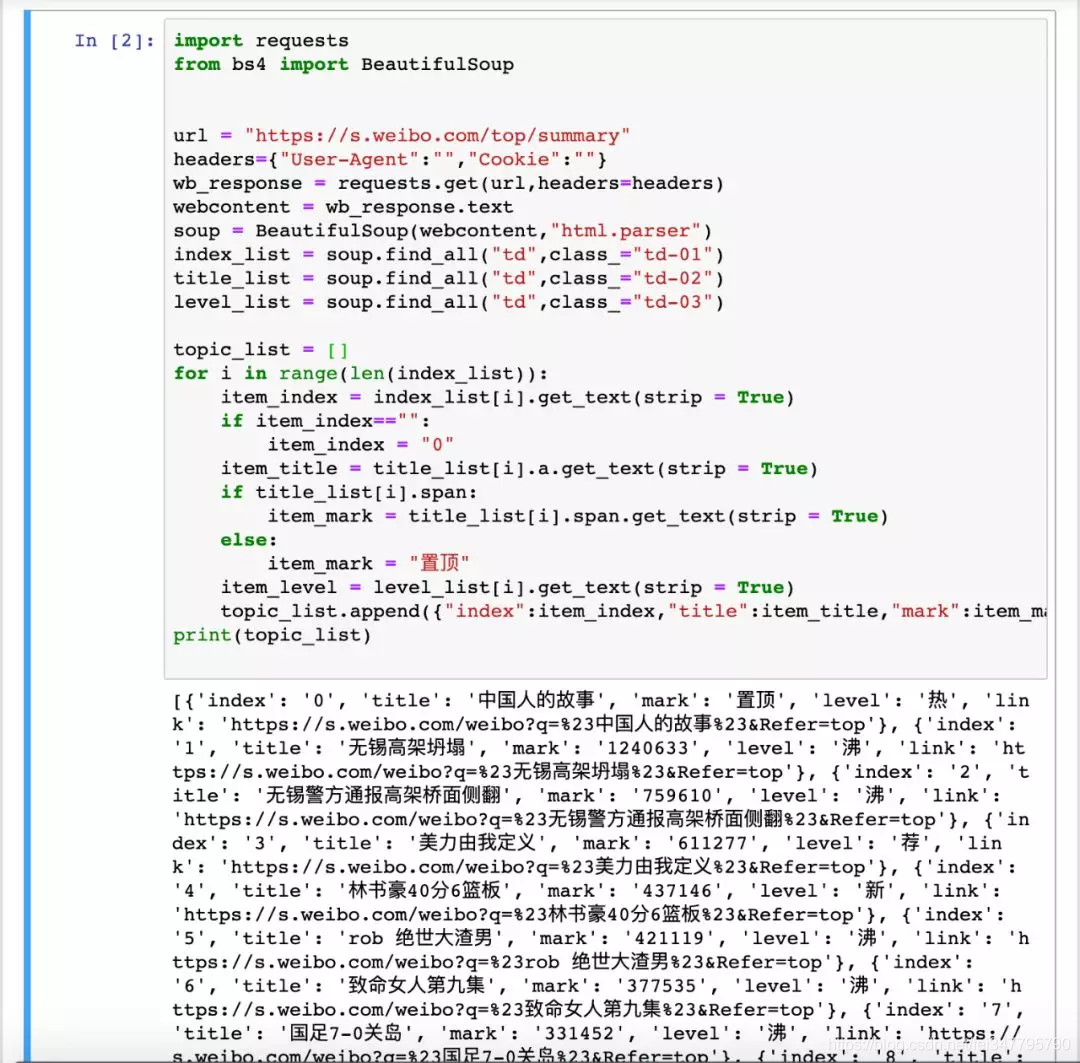
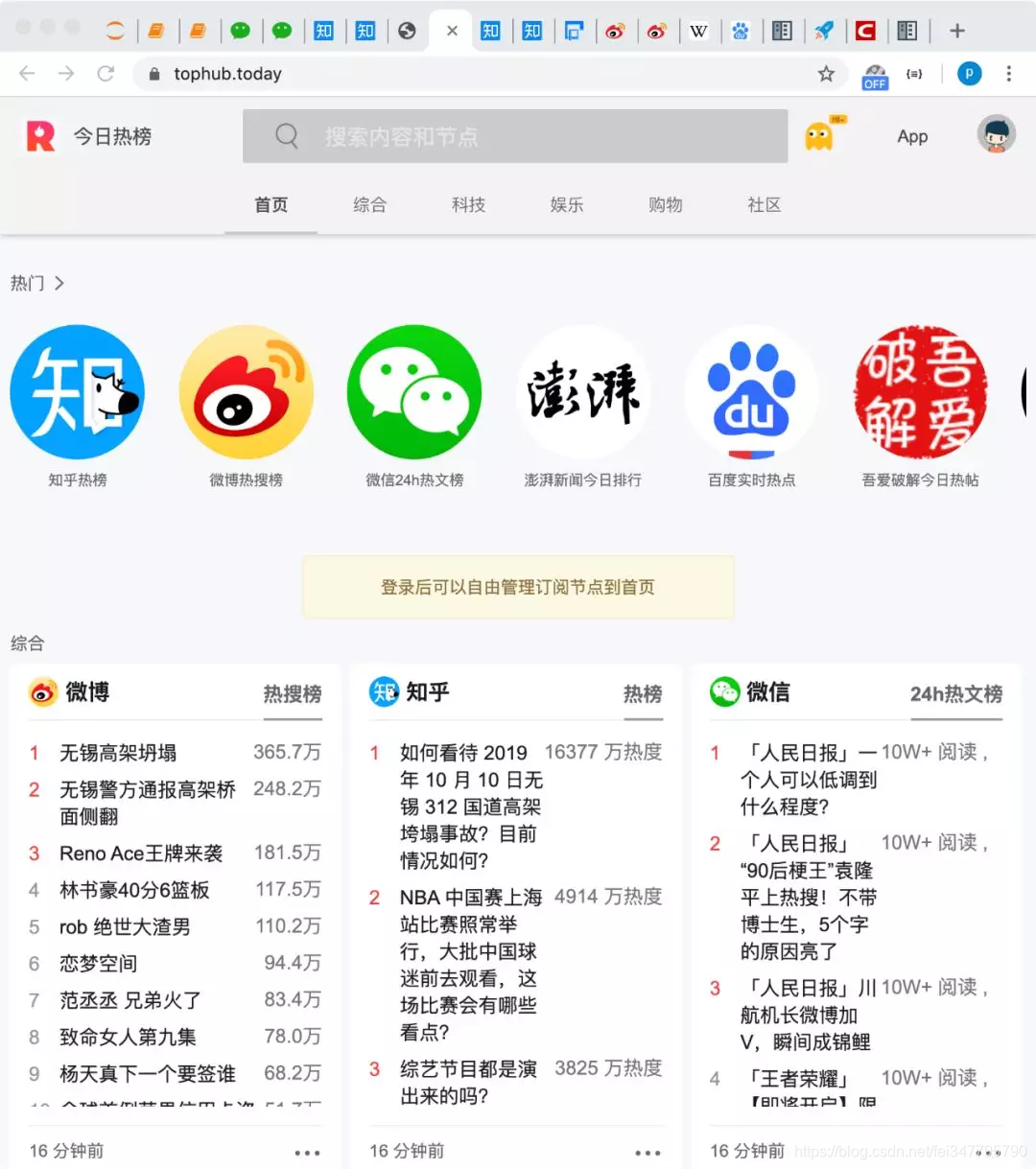
后续对拿到的数据加以处理展示,即可得到很多有趣的应用或实现某些功能。例如集成诸多平台排行榜的 “今日热榜”:
因为并未展开爬虫细节,今天的总结也比较简单:
1、首先在选取要爬的网址时要给自己降低难度,例如同样是知乎热榜,zhihu.com/hot 需要登陆,而 zhihu.com/billboard 无需登录便可访问 2、解析爬取到的内容时,要结合具体页面内容选择最便捷的方式。当需要批量爬取相似页面时,也要尽量整理通用的解析策略。
完整代码
weibo_top.py
import requests
from bs4 import BeautifulSoup
url = "https://s.weibo.com/top/summary"
headers = {"User-Agent": "", "Cookie": ""}
wb_response = requests.get(url, headers=headers)
webcontent = wb_response.text
soup = BeautifulSoup(webcontent, "html.parser")
index_list = soup.find_all("td", class_="td-01")
title_list = soup.find_all("td", class_="td-02")
level_list = soup.find_all("td", class_="td-03")
topic_list = []
for i in range(len(index_list)):
item_index = index_list[i].get_text(strip=True)
if item_index == "":
item_index = ""
item_title = title_list[i].a.get_text(strip=True)
if title_list[i].span:
item_mark = title_list[i].span.get_text(strip=True)
else:
item_mark = "置顶"
item_level = level_list[i].get_text(strip=True)
topic_list.append({"index": item_index, "title": item_title, "mark": item_mark, "level": item_level,
"link": f"https://s.weibo.com/weibo?q=%23{item_title}%23&Refer=top"})
print(topic_list)
zhihu_billboard.py
import requests
import re
from bs4 import BeautifulSoup
headers={"User-Agent":"","Cookie":""}
zh_url = "https://www.zhihu.com/billboard"
zh_response = requests.get(zh_url,headers=headers)
webcontent = zh_response.text
soup = BeautifulSoup(webcontent,"html.parser")
script_text = soup.find("script",id="js-initialData").get_text()
rule = r'"hotList":(.*?),"guestFeeds"'
result = re.findall(rule,script_text)
temp = result[0].replace("false","False").replace("true","True")
hot_list = eval(temp)
print(hot_list)
用 Python 监控知乎和微博的热门话题的更多相关文章
- Python监控网站接口值
Python监控网站接口值: #!/usr/bin/env python # -*- coding: utf-8 -*- __author__ = 'liudong' import urllib,sy ...
- Python 监控nginx服务是否正常
Python 监控nginx服务是否正常 #!/usr/bin/env python import os, sys, time from time import strftime while True ...
- python爬虫知乎问答
python爬虫知乎问答 import cookielibimport base64import reimport hashlibimport jsonimport rsaimport binasci ...
- python监控端口脚本[jkport2.0.py]
#!/usr/bin/env python #!coding=utf-8 import os import time import sys import smtplib from email.mime ...
- Python监控文件变化:watchdog
Python监控文件变化有两种库:pyinotify和watchdog.pyinotify依赖于Linux平台的inotify,后者则对不同平台的的事件都进行了封装.也就是说,watchdog跨平台. ...
- python os.startfile python实现双击运行程序 python监控windows程序 监控进程不在时重新启动
用python监控您的window服务 原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://world77.blog.51cto.co ...
- python监控tomcat日记文件
最近写了一个用python监控tomcat日记文件的功能 实现的功能: 监控日记文件中实时过来的记录,统计每分钟各个接口调用次数,统计结果插入oracle #!/usr/bin/python # -* ...
- Python 监控脚本
Python 监控脚本 整体通过psutil模块动态获取资源信息.下为示例图: #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time: 2019- ...
- Python 3.6 抓取微博m站数据
Python 3.6 抓取微博m站数据 2019.05.01 更新内容 containerid 可以通过 "107603" + user_id 组装得到,无需请求个人信息获取: 优 ...
随机推荐
- 关于Oracle数据库的rownum应用
它是Oracle系统顺序分配为从查询返回的行的编号,返回的第一行分配的是1,第二行是2,以此类推,这个伪字段可以用于限制查询返回的总行数,而且rownum不能以任何表的名称作为前缀. 如以下语句将无法 ...
- Windows10+texlive2018+texstudio
texlive2018+texstudio下载链接 链接: https://pan.baidu.com/s/1KjPJnw1kwMBCu3qGT9rIUg 提取码: g8ha 安装texlive 解压 ...
- Add an Action that Displays a Pop-up Window 添加显示弹出窗口按钮
In this lesson, you will learn how to create an Action that shows a pop-up window. This type of Acti ...
- jquery实现get的异步请求
<%@ page contentType="text/html;charset=UTF-8" language="java" %><html& ...
- PHP对URL进行字符串编码
urlencode($url1) urldecode($url) //对URL进行字符串编码和解码 $url1 = 'https://www.baidu.com/uploade/img/123.png ...
- 微信小程序的bindtap事件
在微信小程序中,要想获取元素的属性值,需要用到 bindtap事件,如果想要正确获取到属性值,对属性的命名还有一定要求 如下是正确的方式data-money-Num="9.93": ...
- 添加数据库数据后(SVN的更新和启动)、SVN启动
一.添加数据库数据: 1.修改Excel表格,添加字段 2.修改数据库,添加字段 3.修改程序 4.使用Excel生成Tabletotable文件,并修改生成文件的内容. (1)删除cpp文件所有的H ...
- CodeForces - 763A(并查集/思维)
题意 https://vjudge.net/problem/CodeForces-763A 一棵无根树中各个节点被染上了一种颜色c[i] 现在让你选择一个点作为根节点,使得这个根节点的所有儿子满足以该 ...
- vmware workstations 虚拟机安装CentOS
1.下载vmware ,我的版本是从上学时保存网盘的,版本比较低,链接如下: 链接:https://pan.baidu.com/s/19QP0q8xmPWIPn-rziPTvKg 提取码:lvh9 2 ...
- Java Web 学习(2) —— JSP
JSP 一. 什么是 JSP JSP 和 Servlet Servlet 有两个缺点是无法克服的:首先,写在 Servlet 中的所有 HTML 标签必须包含 Java 字符串,这使得处理HTTP响应 ...