前期准备
操作系统
hadoop目前对linux操作系统支持是最好的,可以部署2000个节点的服务器集群;在hadoop2.2以后,开始支持windows操作系统,但是兼容性没有linux好。因此,建议在MAC OS或者linux(CentOS或者Unbuntu)操作系统上安装。
安装java
hadoop2.6以前的版本,需要jdk1.6以上的版本;从hadoop2.7开始,则需要jdk1.7以上的版本。
对于linux操作系统用户
tar zxvf jdk-8u161-linux-x64.tar.gz -C /opt
接着就需要配置环境变量
编辑环境变量文件,添加如下代码
$ vim /etc/profile
export JAVA_HOME=/opt/jdk1.8.0_161
export PATH=$PATH:$JAVA_HOME/bin
对于MacOS操作系统用户
接着就需要配置环境变量
编辑环境变量文件,添加如下代码
$ vim /etc/profile
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_161.jdk/Contents/Home
export PATH=$PATH:$JAVA_HOME/bin
检查java是否安装成功
$ java -version
输入上面的命令后,会输出java的基本信息
安装Hadoop
hadoop的安装方式有三种,本地模式、伪分布模式和完全分布模式。三种模式安装步骤有少许区别,本文介绍伪分布模式,也是开发环境最常用的方式。
通过
官方网站下载hadoop版本,建议安装2.6版本,此版本相对更稳定,也是使用最为广泛的版本。
$ tar zxvf hadoop-2.6.0.tar.gz -C /opt
配置环境变量
$vim /etc/profile
export HADOOP_HOME=/opt/hadoop-2.6.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
hadoop配置文件
/opt/hadoop-2.6.0/hadoop-env.sh:
export JAVA_HOME=使用你上面配置的java_home路径
export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
/opt/hadoop-2.6.0/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.0/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
<!--垃圾保存一天-->
</property>
/opt/hadoop-2.6.0/hdfs-site.xml:
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
/opt/hadoop-2.6.0/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
/opt/hadoop-2.6.0/yarn-site.xml
<configuration>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://localhost:19888/jobhistory/job/</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 设置HDFS可以使用硬盘的百分比,对于硬盘小的人很重要 -->
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>99.0</value>
</property>
</configuration>
SSH免密码登录
检查一下,是否可以对本地进行免密码登录
$ ssh localhost
如果你在ssh本地时,需要输入密码,那么按以下步骤,配置免密码登录
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
格式化hdfs目录
$ hdfs namenode -format
该命令执行后,只会格式化你的/opt/hadoop-2.6.0/tmp目录
启动HDFS
$ start-dfs.sh
启动hdfs后,会生成日志文件,在$HADOOP_HOME/logs目录下
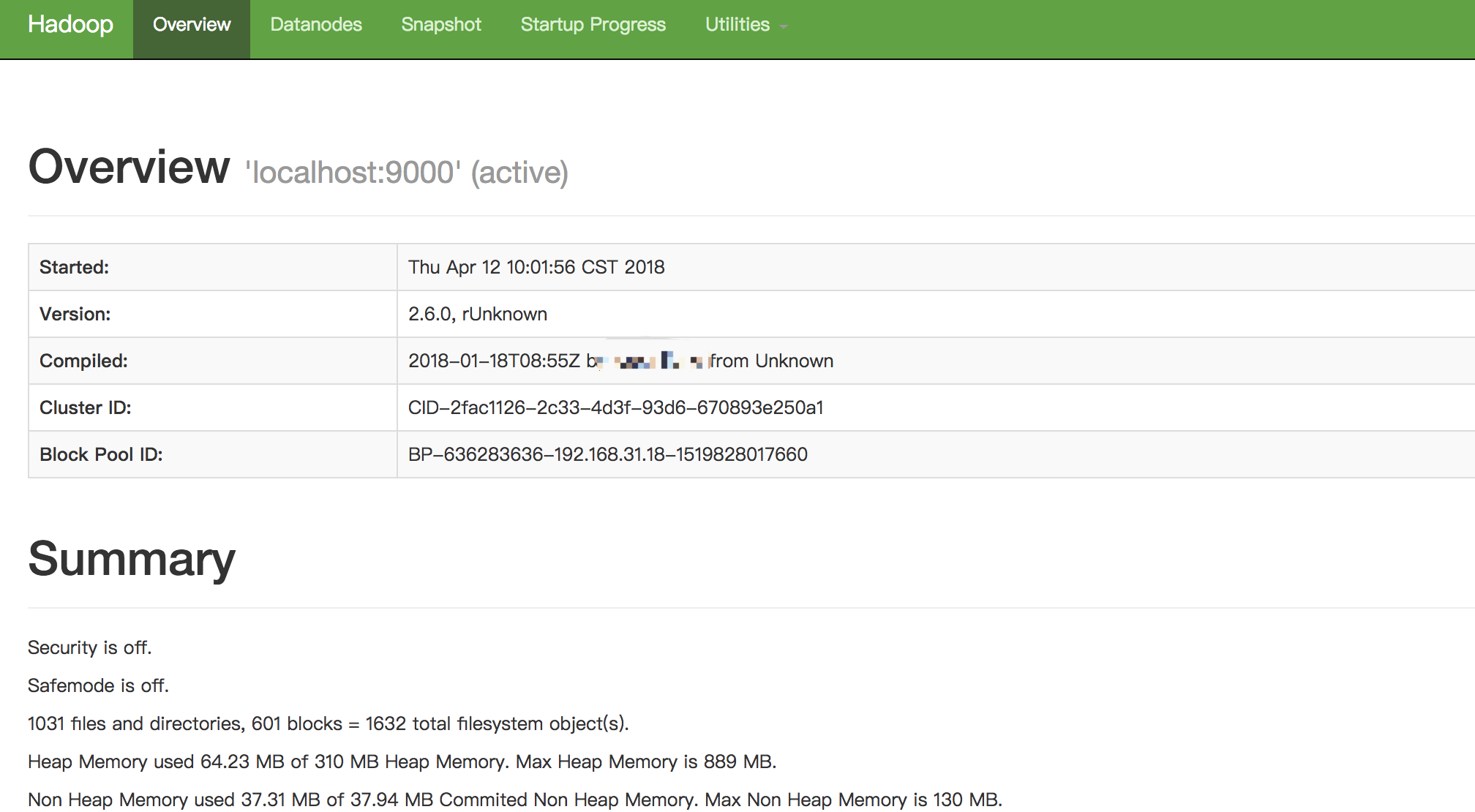
如果启动成功,你可以通过浏览器打开http://localhost:50070/,查看hdfs的相关信息
如果你想停止hdfs,请输入以下命令
$ stop-dfs.sh
启动yarn
$ start-yarn.sh
启动yarn后,会生成日志文件,在$HADOOP_HOME/logs目录下
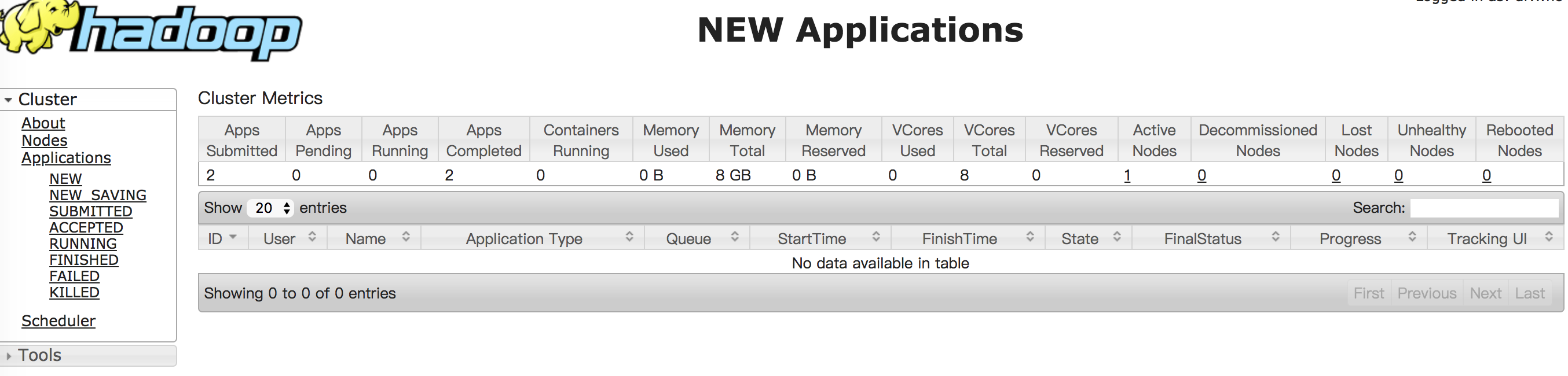
如果启动成功,你可以通过浏览器打开http://localhost:8088/,查看yarn的相关信息
如果你想停止yarn,请输入以下命令
$ stop-yarn.sh
启动JobHistory
$ mr-jobhistory-daemon.sh start historyserver
启动JobHistory后,会生成日志文件,在$HADOOP_HOME/logs目录下
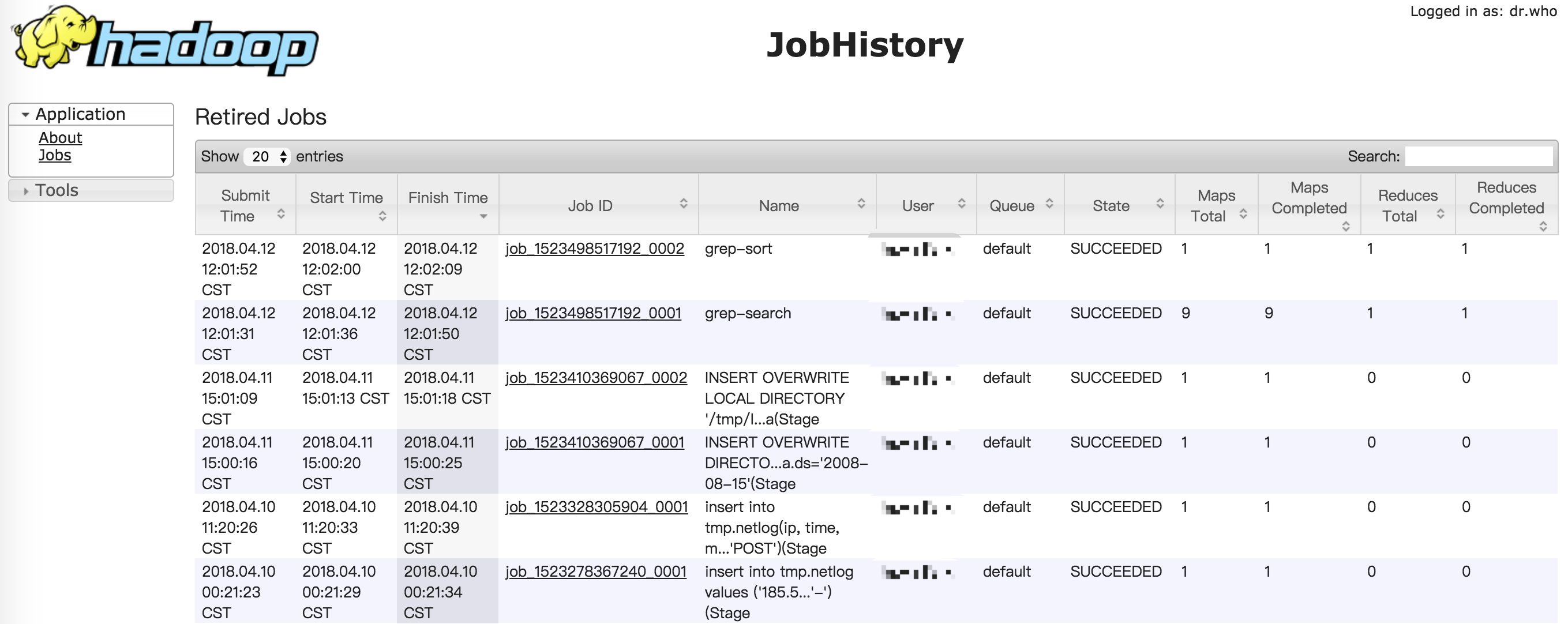
如果启动成功,你可以通过浏览器打开http://localhost:19888/,查看jobhistory的相关信息
如果你想停止JobHistory,请输入以下命令
$ mr-jobhistory-daemon.sh stop historyserver
测试hadoop
成功安装完hadoop后,我们可以通过一些命令来感受一下hadoop
创建目录
$ hdfs dfs -mkdir /tmp/input
上传本地文件到hdfs $ hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml /tmp/input
使用MapReduce来计算我们刚才上传文件的以dfs开头的单词个数
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep /tmp/input /tmp/output 'dfs[a-z.]+'
查看MapReduce的结果
可以把hdfs上的结果文件下载到本地后查看
$ hdfs dfs -get /tmp/output output $ cat output/*
也可以通过hdfs查看命令直接查看
$ hdfs dfs -cat /tmp/output/part-r-00000
通过查询http://localhost:8088/,你会发现刚才执行MapReduce任务的历史记录


- windows下大数据开发环境搭建(2)——Hadoop环境搭建
一.所需环境 ·Java 8 二.Hadoop下载 http://hadoop.apache.org/releases.html 三.配置环境变量 HADOOP_HOME: C:\hadoop- Pa ...
- windows下大数据开发环境搭建(4)——Spark环境搭建
一.所需环境 · Java 8 · Python 2.6+ · Scala · Hadoop 2.7+ 二.Spark下载与解压 http://spark.apache.org/downloads.h ...
- windows下大数据开发环境搭建(1)——Java环境搭建
一.Java 8下载 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 下载之后 ...
- windows下大数据开发环境搭建(3)——Scala环境搭建
一.所需环境 ·Java 8 二.下载Scala https://www.scala-lang.org/download/ 三.配置环境变量 SCALA_HOME: C:\scala Path: ...
- 大数据开发,Hadoop Spark太重?你试试esProc SPL
摘要:由于目标和现实的错位,对很多用户来讲,Hadoop成了一个在技术.应用和成本上都很沉重的产品. 本文分享自华为云社区<Hadoop Spark太重,esProc SPL很轻>,作者: ...
- 搭建Hadoop+Python的大数据开发环境
实验环境 CentOS镜像为CentOS-7-x86_64-Everything-1804.iso 虚机配置 节点名称 IP地址 子网掩码 CPU/内存 磁盘 安装方式 master 192.168. ...
- windows下大数据开发环境搭建(1)——Hadoop环境搭建
所需环境 jdk 8 Hadoop下载 http://hadoop.apache.org/releases.html 配置环境变量 HADOOP_HOME: C:\hadoop-2.7.7 Path: ...
- 小白入门AI教程:教你快速搭建大数据平台『Hadoop+Spark』
Apache Spark 简介 Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎.Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源 ...
- Eclipse和PyDev搭建完美Python开发环境 Windows篇
1,安装Python Python是一个跨平台语言,Python从3.0的版本的语法很多不兼容2版本,官网找到最新的版本并下载:http://www.python.org, 因为之前的一个项目是2版本 ...
随机推荐
- Java 从入门到进阶之路(四)
之前的文章我们介绍了 Java 的运算符和表达式,本章我们来看一下 Java 的循环结构. 循环是程序设计语言中反复执行某些代码的一种计算机处理过程,是一组相同或相似语句被有规律的重复性进行. 循环的 ...
- Spring学习之旅(一)--初始Spring
之前从博客.视频断断续续的学到了 Spring 的相关知识,但是都是一个个碎片化的知识.刚好最近在读 <Sprign实战(第四版)>,所以借此机会重新整理下Spring 系列的内容. Sp ...
- Count the string[KMP]HDU3336
题库链接http://acm.hdu.edu.cn/showproblem.php?pid=3336 这道题是KMP的next数组的一个简单使用,首先要理解next数组的现实意义:next[i]表示模 ...
- MSIL实用指南-返回结果
一个方法体执行完指令后,必须要完成调用并返回,这是要使用Ret指令.Ret指令的详细解释是从当前方法返回,并将返回值(如果存在)从被调用方的计算堆栈推送到调用方的计算堆栈上.就是说如果计算堆栈上没有变 ...
- Oracle性能图表工具:awrcrt.sql 介绍,更新到了2.14 (2018年3月31日更新)
2018-03-31 awrcrt更新到了2.14版本, 下载地址为 https://pan.baidu.com/s/1IlYVrBJuZWwOljomVfta5g https://pan.baidu ...
- Atcode B - Colorful Hats(思维)
题目链接:http://agc016.contest.atcoder.jp/tasks/agc016_b 题解:挺有意思的题目主要还是模拟出最多有几种不可能的情况,要知道ai的差距不能超过1这个想想就 ...
- lightoj 1097 - Lucky Number(线段树)
Lucky numbers are defined by a variation of the well-known sieve of Eratosthenes. Beginning with the ...
- 如何将 JavaScript 代码添加到网页中,以及 <script> 标签的属性
Hello, world! 本教程的这一部分内容是关于 JavaScript 语言本身的. 但是,我们需要一个工作环境来运行我们的脚本,由于本教程是在线的,所以浏览器是一个不错的选择.我们会尽可能少地 ...
- Nacos配置服务原理
Nacos Client配置机制 spring加载远程配置 在了解NACOS客户端配置之前,我们先看看spring怎么样加载远程配置的.spring 提供了加载远程配置的扩展接口 PropertySo ...
- 泛型接口、JAVA API、包装类
泛型接口就是拥有一个或多个类型参数的接口 语法: public interface 接口名<类型形参>{ 方法名(类型形参 类型形参实例); } 示例: public interface ...