Python3网络爬虫(1):利用urllib进行简单的网页抓取
1.开发环境
pycharm2017.3.3
python3.5
2.网络爬虫的定义
网络爬虫,也叫网络蜘蛛(web spider),如果把互联网比喻成一个蜘蛛网,spider就是一只在网上爬来爬去的蜘蛛,网络爬虫就是根据网页的地址来寻找网页的,也就是URL。举一个简单的例子,我们在浏览器的地址栏中输入的字符串就是URL,例如:https://www.baidu.com/
URL就是统一资源定位符(uniform resource location),他的一般格式如下(带方括号[]的为可选项)
protocol://hostname[:port]/path/[:parameters][?query]#fragment
URL的格式由三部分组成:
(1)protocol:第一部分就是协议,例如百度使用的就是https协议;
(2)hostname[:port]:第二部分人就是主机名(还有端口号为可选参数),一般网站默认的端口号为80
(3)path:第三部分就是主机资源的具体地址,如目录和文件名等,网络爬虫就是根据这个URL来获取网页信息的
3.简单爬虫实例
在Python3.x中,我们可以使用urllib这个组件抓取网页,urllib是一个URL处理包,这个包中集合了一下处理url的模块,如下:
(1)urllib.request模块是用来打开和读取URLs的;
(2)urllib.error模块包含一些由urllib.request产生的错误,可以使用try进行捕捉处理
(3)urllib.parse模块包含了一些解析URLs的方法;
(4)urllib.robotparser模块用来解析robots.txt文本文件,它提供了一个单独的RobotFileParser类,通过该类提供的can_fatch()方法测试爬虫是否可以下载一个页面
我们使用urllib.request.urlopen()这个接口函数就可以很轻松的打开一个网站,读取并打印信息
下面来写一个简单的程序实现一下
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.baidu.com")
html = response.read()
print(html)
运行结果(可以看到进度条还能拉倒很远)

这都是些什么鬼玩意呢
拿来对比一下,浏览器中打开www.baidu.com,查看页面元素,快捷键F12(浏览器最好用火狐或者Chrome)
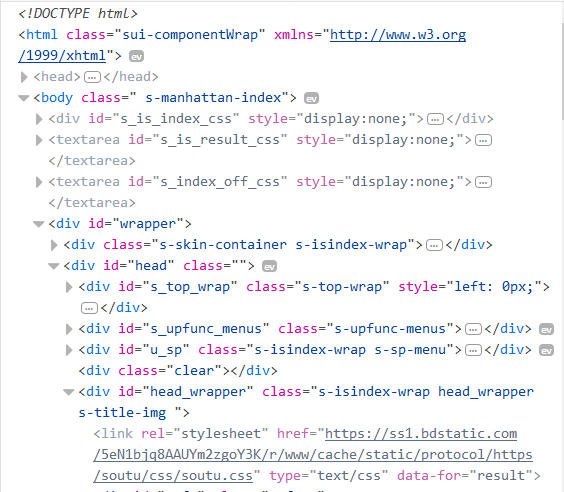
东西都一样,就是格式有点乱,可以通过简单的decode()命令将网页的信息进行解码并显示出来,在代码中添加一句html=html.decode("utf-8")即可
from urllib import request if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
输出正常的html格式
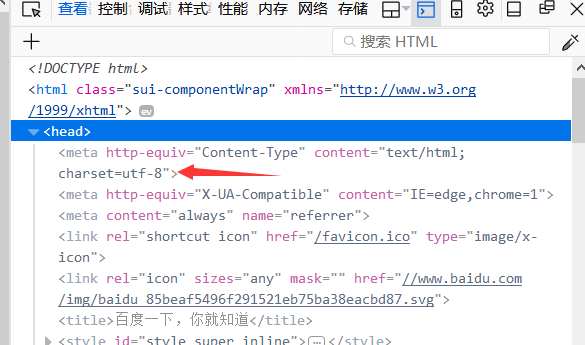
当然编码方式不是我们猜出来的,是查出来的,在查看元素中找到head标签,打开,看到charset="utf-8",就是编码方式
4.自动获取网页编码方式的方法
这里采用第三方库的方法,安装chardet
pip install chardet
对代码稍作修改用来判断网页的编码方式
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://www.baidu.com")
html = response.read()
#html = html.decode("utf-8")
charset = chardet.detect(html)
print(charset)
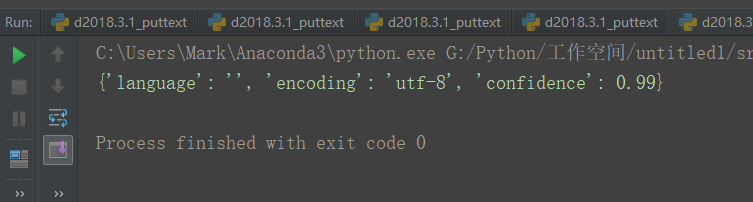
可以看到返回的是字典,最后也可以整合一下
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://www.baidu.com")
html = response.read()
charset = chardet.detect(html)
html = html.decode(charset.get('encoding')) print(html)
完美
Python3网络爬虫(1):利用urllib进行简单的网页抓取的更多相关文章
- Python实现简单的网页抓取
现在开源的网页抓取程序有很多,各种语言应有尽有. 这里分享一下Python从零开始的网页抓取过程 第一步:安装Python 点击下载适合的版本https://www.python.org/ 我这里选择 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- Python3网络爬虫(三):urllib.error异常
运行平台:Windows Python版本:Python3.x IDE:Sublime text3 转载请注明作者和出处:http://blog.csdn.net/c406495762/article ...
- python3一个简单的网页抓取
都是学PYTHON.怎么学都是学,按照基础学也好,按照例子增加印象也好,反正都是学 import urllib import urllib.request data={} data['word']=' ...
- 转:【Python3网络爬虫开发实战】 requests基本用法
1. 准备工作 在开始之前,请确保已经正确安装好了requests库.如果没有安装,可以参考1.2.1节安装. 2. 实例引入 urllib库中的urlopen()方法实际上是以GET方式请求网页,而 ...
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- [Python3网络爬虫开发实战] 2.3-爬虫的基本原理
我们可以把互联网比作一张大网,而爬虫(即网络爬虫)便是在网上爬行的蜘蛛.把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息.可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛 ...
- Python3网络爬虫开发实战PDF高清完整版免费下载|百度云盘
百度云盘:Python3网络爬虫开发实战高清完整版免费下载 提取码:d03u 内容简介 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.req ...
随机推荐
- BZOJ1178 APIO2009 会议中心 贪心、倍增
传送门 只有第一问就比较水了 每一次贪心地选择当前可以选择的所有线段中右端点最短的,排序之后扫一遍即可. 考虑第二问.按照编号从小到大考虑每一条线段是否能够被加入.假设当前选了一个区间集合\(T\), ...
- 使用Win PE修改其他硬盘中的系统注册表
使用场景:原来装的机械硬盘系统盘为C盘,后来买了个SSD固态硬盘后,进入WinPE系统后,把原来的C盘整个复制到了固态硬盘,然后用BooticeX64.exe工具在UEFI启动中增加SSD固态硬盘中的 ...
- 《Java程序设计》教学进程
<Java程序设计>教学进程 目录 考核方式 课前准备 教学进程 第00周学习任务和要求 第01周学习任务和要求 第02周学习任务和要求 第03周学习任务和要求 第04周学习任务和要求 第 ...
- visual studio Web发布至 IIS WebDeploy出错(未能创建SSL/TLS安全通道)Could not create SSL/TLS secure channel
问题发生的原因是VS 15.9尝试使用系统默认值进行TLS握手,但是要在VS内的某处设置为TLS1.2. 此问题的解决方法是在部署项目的IIS服务器上启用TLS 1.2.例如,请按照此文章中的说明操作
- python3通过gevent.pool限制协程并发数量
协程虽然是轻量级的线程,但到达一定数量后,仍然会造成服务器崩溃出错.最好的方法通过限制协程并发数量来解决此类问题. server代码: #!/usr/bin/env python # -*- codi ...
- postgresql总结
这篇博客主要对PostgreSQL进行总结,内容偏基础. 这里先附上一个PostgreSQL的中文资源:PostgreSQL 8.1 中文文档.英文不好的同学可以看看这个. 安装PostgreSQL ...
- 学习ML.NET(2): 使用模型进行预测
训练模型 在上一篇文章中,我们已经通过LearningPipeline训练好了一个“鸢尾花瓣预测”模型, var model = pipeline.Train<IrisData, IrisPre ...
- 【JVM.2】垃圾收集器与内存分配策略
垃圾收集器需要完成的3件事情: 哪些内存需要回收? 什么时候回收? 如何回收? 在前一节中介绍了java内存运行时区域的各个部分,其中程序计数器.虚拟机栈.本地方法栈3个区域随线程而生,随线程而灭:栈 ...
- jdbc操作根据bean类自动组装sql,天啦,我感觉我实现了hibernate
场景:需要将从ODPS数仓中计算得到的大额可疑交易信息导入到业务系统的mysql中供业务系统审核.最简单的方式是用阿里云的组件自动进行数据同步了.但是本系统是开放是为了产品化,要保证不同环境的可移植性 ...
- Linux运维笔记-日常操作命令总结(2)
回想起来,从事linux运维工作已近5年之久了,日常工作中会用到很多常规命令,之前简单罗列了一些命令:http://www.cnblogs.com/kevingrace/p/5985486.html今 ...