Python3网络爬虫(1):利用urllib进行简单的网页抓取
1.开发环境
pycharm2017.3.3
python3.5
2.网络爬虫的定义
网络爬虫,也叫网络蜘蛛(web spider),如果把互联网比喻成一个蜘蛛网,spider就是一只在网上爬来爬去的蜘蛛,网络爬虫就是根据网页的地址来寻找网页的,也就是URL。举一个简单的例子,我们在浏览器的地址栏中输入的字符串就是URL,例如:https://www.baidu.com/
URL就是统一资源定位符(uniform resource location),他的一般格式如下(带方括号[]的为可选项)
protocol://hostname[:port]/path/[:parameters][?query]#fragment
URL的格式由三部分组成:
(1)protocol:第一部分就是协议,例如百度使用的就是https协议;
(2)hostname[:port]:第二部分人就是主机名(还有端口号为可选参数),一般网站默认的端口号为80
(3)path:第三部分就是主机资源的具体地址,如目录和文件名等,网络爬虫就是根据这个URL来获取网页信息的
3.简单爬虫实例
在Python3.x中,我们可以使用urllib这个组件抓取网页,urllib是一个URL处理包,这个包中集合了一下处理url的模块,如下:
(1)urllib.request模块是用来打开和读取URLs的;
(2)urllib.error模块包含一些由urllib.request产生的错误,可以使用try进行捕捉处理
(3)urllib.parse模块包含了一些解析URLs的方法;
(4)urllib.robotparser模块用来解析robots.txt文本文件,它提供了一个单独的RobotFileParser类,通过该类提供的can_fatch()方法测试爬虫是否可以下载一个页面
我们使用urllib.request.urlopen()这个接口函数就可以很轻松的打开一个网站,读取并打印信息
下面来写一个简单的程序实现一下
from urllib import request
if __name__ == "__main__":
response = request.urlopen("http://www.baidu.com")
html = response.read()
print(html)
运行结果(可以看到进度条还能拉倒很远)

这都是些什么鬼玩意呢
拿来对比一下,浏览器中打开www.baidu.com,查看页面元素,快捷键F12(浏览器最好用火狐或者Chrome)
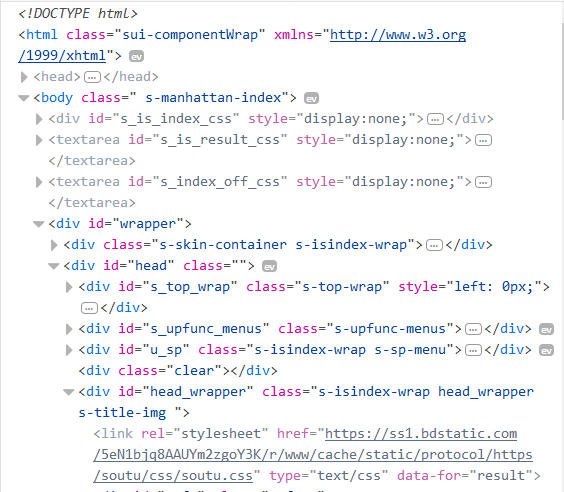
东西都一样,就是格式有点乱,可以通过简单的decode()命令将网页的信息进行解码并显示出来,在代码中添加一句html=html.decode("utf-8")即可
from urllib import request if __name__ == "__main__":
response = request.urlopen("http://www.fanyi.baidu.com/")
html = response.read()
html = html.decode("utf-8")
print(html)
输出正常的html格式
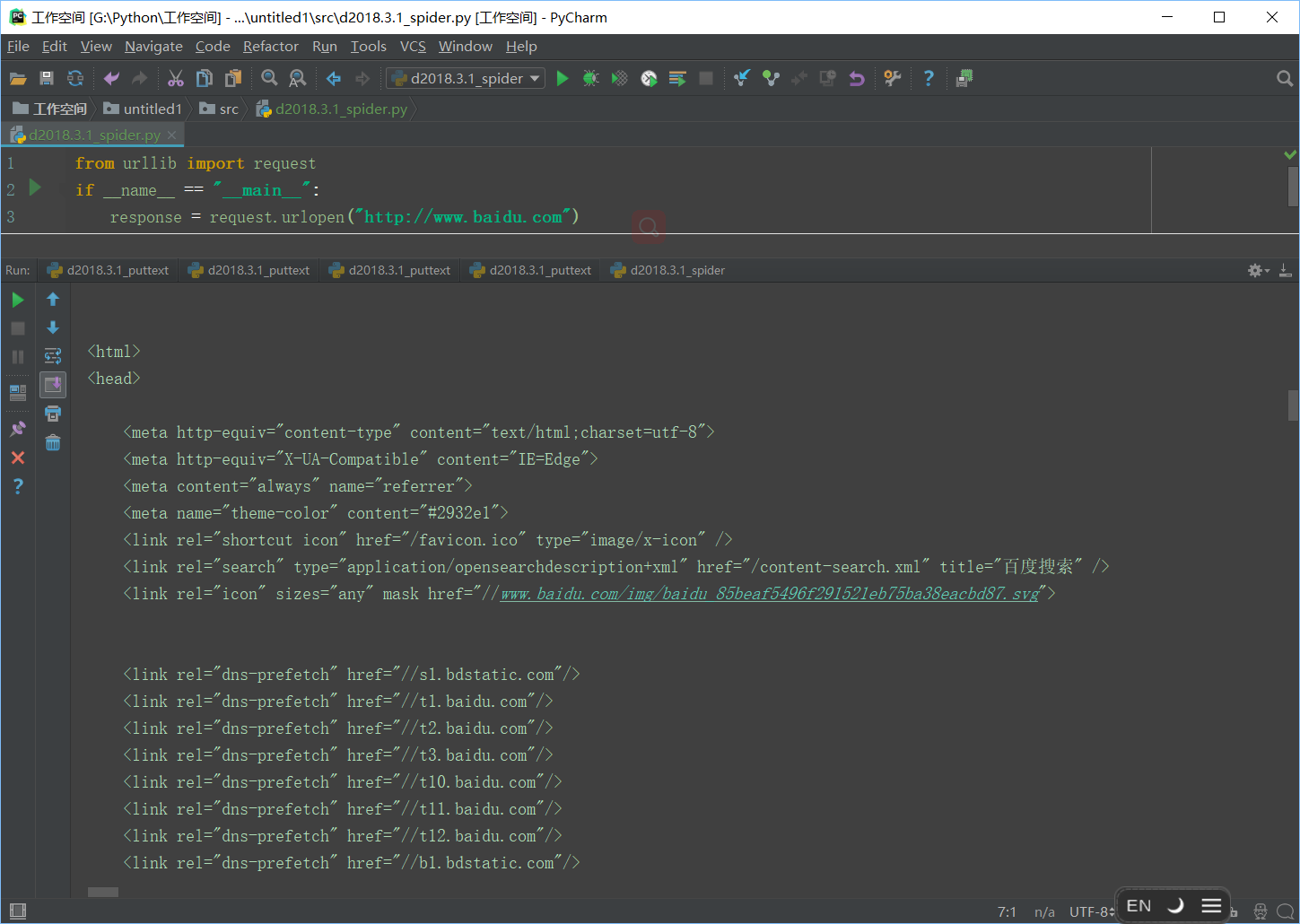
当然编码方式不是我们猜出来的,是查出来的,在查看元素中找到head标签,打开,看到charset="utf-8",就是编码方式
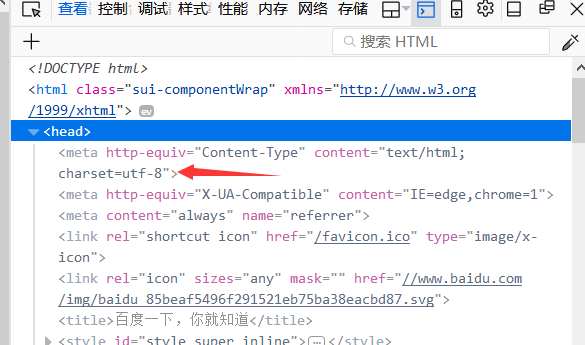
4.自动获取网页编码方式的方法
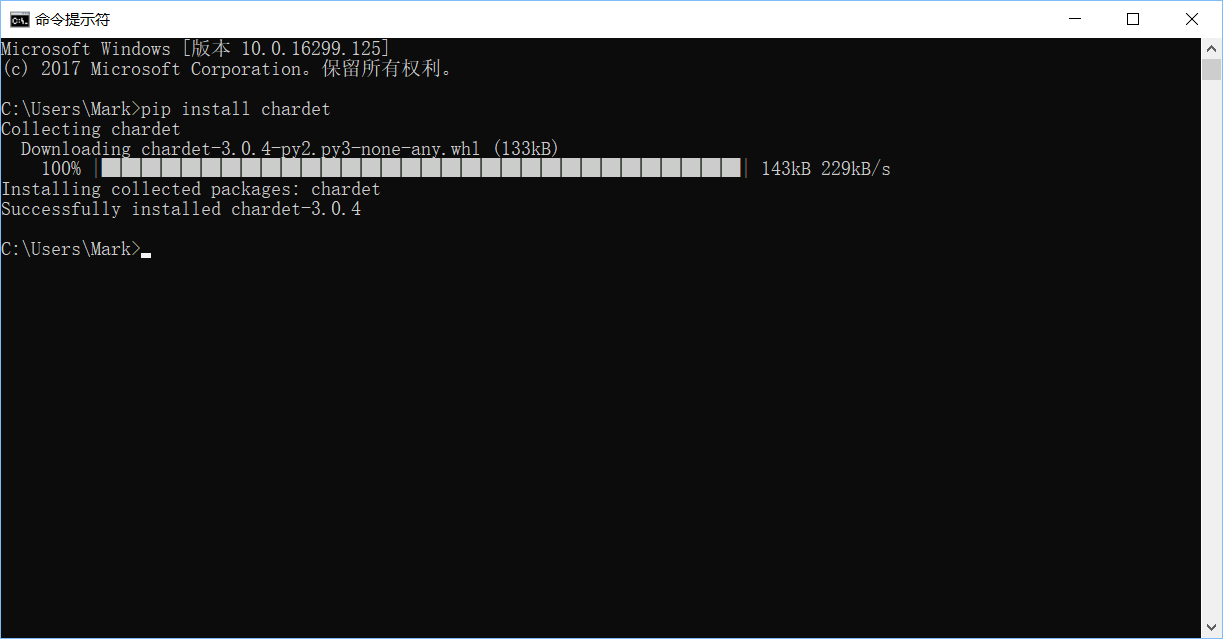
这里采用第三方库的方法,安装chardet
pip install chardet
对代码稍作修改用来判断网页的编码方式
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://www.baidu.com")
html = response.read()
#html = html.decode("utf-8")
charset = chardet.detect(html)
print(charset)
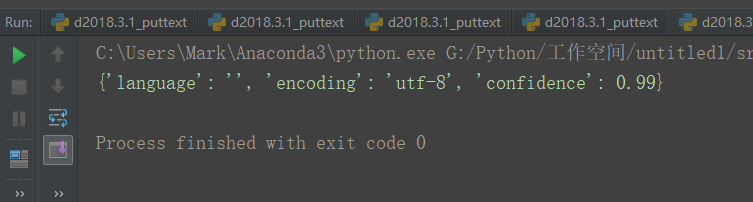
可以看到返回的是字典,最后也可以整合一下
from urllib import request
import chardet
if __name__ == "__main__":
response = request.urlopen("http://www.baidu.com")
html = response.read()
charset = chardet.detect(html)
html = html.decode(charset.get('encoding')) print(html)
完美
Python3网络爬虫(1):利用urllib进行简单的网页抓取的更多相关文章
- Python实现简单的网页抓取
现在开源的网页抓取程序有很多,各种语言应有尽有. 这里分享一下Python从零开始的网页抓取过程 第一步:安装Python 点击下载适合的版本https://www.python.org/ 我这里选择 ...
- 【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图【华为云技术分享】
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- 转:【Python3网络爬虫开发实战】6.4-分析Ajax爬取今日头条街拍美图
[摘要] 本节中,我们以今日头条为例来尝试通过分析Ajax请求来抓取网页数据的方法.这次要抓取的目标是今日头条的街拍美图,抓取完成之后,将每组图片分文件夹下载到本地并保存下来. 1. 准备工作 在本节 ...
- Python3网络爬虫(三):urllib.error异常
运行平台:Windows Python版本:Python3.x IDE:Sublime text3 转载请注明作者和出处:http://blog.csdn.net/c406495762/article ...
- python3一个简单的网页抓取
都是学PYTHON.怎么学都是学,按照基础学也好,按照例子增加印象也好,反正都是学 import urllib import urllib.request data={} data['word']=' ...
- 转:【Python3网络爬虫开发实战】 requests基本用法
1. 准备工作 在开始之前,请确保已经正确安装好了requests库.如果没有安装,可以参考1.2.1节安装. 2. 实例引入 urllib库中的urlopen()方法实际上是以GET方式请求网页,而 ...
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- [Python3网络爬虫开发实战] 2.3-爬虫的基本原理
我们可以把互联网比作一张大网,而爬虫(即网络爬虫)便是在网上爬行的蜘蛛.把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息.可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛 ...
- Python3网络爬虫开发实战PDF高清完整版免费下载|百度云盘
百度云盘:Python3网络爬虫开发实战高清完整版免费下载 提取码:d03u 内容简介 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.req ...
随机推荐
- 《MySQL必知必会》[05] 存储过程和游标
1.存储过程 存储过程是什么,简单来讲,就像Java中的方法(函数),不过它是SQL世界中的方法. 大部分时候,我们所使用都是单条SQL,用来针对一个或多表连接.但是也有情况,是据判断先对表A执行操作 ...
- 创建一个Scalar-valued Function函数来实现LastIndexOf
昨天有帮助网友解决的个字符串截取的问题,<截取字符串中最后一个中文词语(MS SQL)>http://www.cnblogs.com/insus/p/7883606.html 虽然实现了, ...
- Cordova套网站
用Cordova套网站,只修改Content的话,打包后的App,在点击后会打开浏览器,并没有在App中显示内容. 需要设置allow-navigation为 * <?xml version=' ...
- A2dp连接流程源码分析
在上一篇文章中,我们已经分析了:a2dp初始化流程 这篇文章主要分析a2dp的连接流程,其中还是涉及到一些底层的profile以及protocol,SDP.AVDTP以及L2CAP等. 当蓝牙设备与主 ...
- 发布了一个基于jieba分词的ElasticSearch插件
github地址: https://github.com/hongfuli/elasticsearch-analysis-jieba 基于 jieba 的 elasticsearch 中文分词插件. ...
- 给echarts加个“全屏展示”
echarts的工具箱并没有提供放大/全屏的功能, 查找文档发现可自定义工具https://www.echartsjs.com/option.html#toolbox.feature show代码 t ...
- 关于用tesseract和tesserocr识别图片的一个问题
对于像我这样初学python网络爬虫的freshman来说,软件的准备和环境的配置能让我们崩溃.其中用刚安装好的tesseract和tesserocr库测试识别验证码就是其中一例. 这里我要测试的验证 ...
- html绝对路径,相对路径
.com/eat.php中引用.com/includes/headrt.php的话写includes/header.php .com/service/eat.php中引用.com/includes/h ...
- Centos7.4安装kvm虚拟机(使用virt-manager管理)
之前介绍了使用WebVirtMgr或Openstack来部署及管理kvm虚拟机,下面简单介绍centos7.4下使用virt-manager部署及管理kvm虚拟机的做法: 0)KVM是什么 KVM(K ...
- 20135337——Linux实践三:程序破解
程序破解 查看 运行 反汇编,查看汇编码 对反汇编代码进行分析: 在main函数的汇编代码中可以看出程序在调用"scanf"函数请求输入之后,对 [esp+0x1c] 和 [esp ...