【 记忆网络 2 】 End-to-End Memory Network
继上一篇:Memory Network
1. 摘要
引入了一个神经网络,在一个可能很大的外部记忆上建立了一个recurrent attention模型。
该体系结构是记忆网络的一种形式,但与该工作中的模型不同,它是端到端培训的,因此在培训期间需要的监督明显更少,这使得它更适合实际环境。
它还可以看作是RNNsearch的扩展,适用于每个输出符号执行多个计算步骤的情况。该模型的灵活性允许我们将其应用于各种任务,如(合成的)问题回答[22]和语言建模。
对于前者,我们的方法是与记忆网络竞争,但缺乏监督。对于后者,在Penn TreeBank和Text8数据集上,我们的方法显示了与RNNs和LSTMs相当的性能。在这两种情况下,我们都证明了多计算跃点的关键概念产生了改进的结果。
2. 基本思想
挑战:
1. 在回答问题或完成任务时实现多计算步骤 。
2. 描述序列数据的长期记忆。
---> 显示存储和attention概念可以解决。
本文:
1. 可以端到端训练的记忆网络。
2. 对于一个输出存在多计算步骤(hops)的RNNsearch扩展网络。
3. 具体方法
输入:x1, ... xn
查询:q
输出:回答(a)
每个xi、q和a都包含来自带有V words的字典的符号。
写入x的所有记忆模型到一个固定的缓冲区大小,然后找到x和q的连续表示。连续表示通过多个hops输出a。
在训练过程中,可以使用误差信号反向传播通过多个记忆访问回到输入。
单层
单层结构只含有一个跳操作。
输入记忆表示:
输入 xi, 通过将每一个xi嵌入到一个连续空间,转换为d维记忆 mi。
最简单的,使用嵌入d*V的嵌入矩阵A。
请求q也用同样的嵌入方式得到内部状态u。 // 方式同上,使用矩阵B
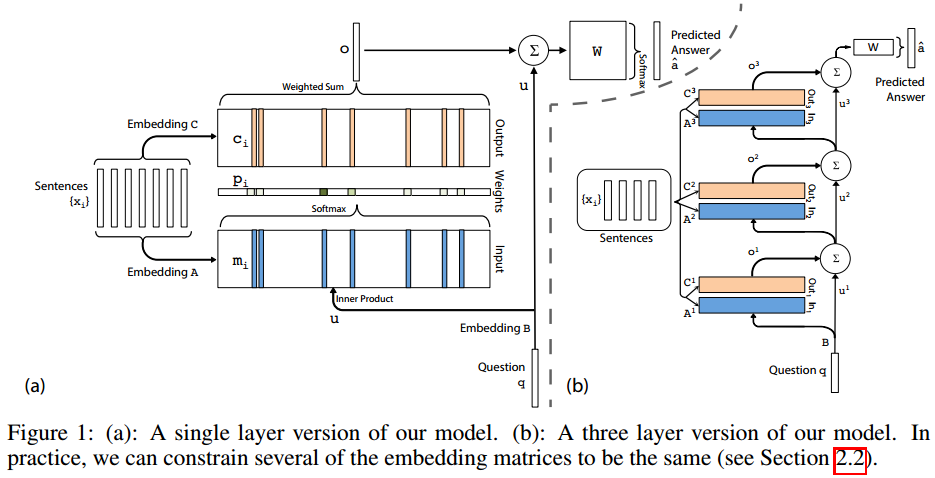
在嵌入空间,利用softmax计算u和每一个记忆mi的匹配情况,如下:

其中,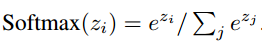
p是概率向量。
输出记忆表示:
每一个输入xi对应一个输出向量 ci。 // 方式同上,但使用另一个矩阵C
记忆o的回复向量被表示为:

该形式容易计算梯度,进行反向传播。
生成最终的预测:
最终V*d的权重矩阵W + softmax:

训练期间,对于三个嵌入矩阵A,B,C及W共同训练,以最小化损失函数。
损失函数:交叉熵。
使用SGD(随机梯度下降)。
多层
本文中给出的多层为三层结构。图1(b)
K hop 操作。
记忆层如下:
1. 第一层:k层输出&输入的和。

2. 每一层都有自己的嵌入矩阵Ak, Ck, 用来嵌入输入 {xi}.
3. 在网络的上层,W的输入也结合上层记忆层的输入和输出。

两种不同类型的权重:
1. Adjacent 邻近
一个层的输出嵌入是上面一层的输入嵌入,eg. Ak+1 = Ck
预测嵌入 = 最后的输出嵌入,eg. WT=CK
请求嵌入和第一层的输入嵌入进行匹配,eg. B = A1
2. Layer-wise (RNN-like) 层智能
每一层的输入嵌入和输出嵌入都是相同的。 A1 = A2 = ... = AK, C1 = C2 = ... = CK
加入线性映射H对u在hops间的更新有帮助。uk+1 = Huk + ok
这个线性映射和其他参数一起学习,并在实验中进行层智能的加权绑定。
生成a之前, 有几个计算步骤?
4. 实施与评价
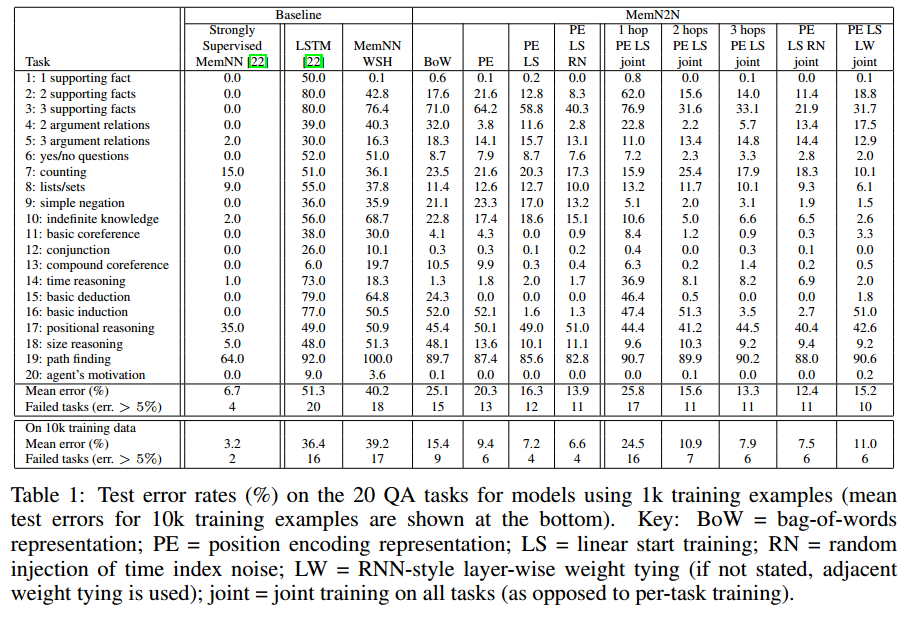
综合问答实验
QAtasks:回答是一个单词。只有小部分任务回答是几个词。
训练时,模型知道这些答案。测试时进行预测。

不再给出支持事实,模型需要自己判断。
模型细节
K = 3
句子表示:
2个不同的表示。
1. bag-of-words 词袋模型 BoW
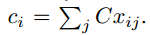
输入向量u和请求也用词袋模型嵌入:
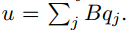
缺点:不能表示词序。这对于一些任务来讲是很重要的。
2. 对句子中的单词进行位置编码
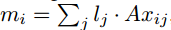
· 是元素智能的乘法。lj是列向量:
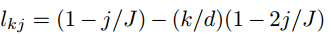
J是句子的字数,d是嵌入的位数。
位置编码(PE)
时间编码:
许多QA任务需要上下文概念。
记忆向量被修改为:
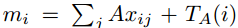
TA(i) 是编码了时间信息的矩阵TA第i行。
输出嵌入用同样的方式增强 // TC
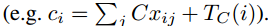
TA和TC都在训练中学习。
并且,它们像A和C一样在每一层中共享。
反向编码: x1 是故事的最后一句。
通过注入随机噪声来实现学习时间不变:
在正则化TA时加入虚拟记忆是有帮助的。
在训练的时候,可以随机地将10%的空白记忆添加到故事中。我们将这种方法称为随机噪声(RN)。
Baselines:
MemNN / MemNN-WSH / LSTM
结果
和有监督模型差不多。
优于弱监督的线性方法。
单词排序尤为重要。
随机空记忆(RN)可以在性能上有小的但持续的提升。
所有任务的联合训练都有帮助。// 所有参数一起训练
更多的计算跃点可以提高性能。
语言建模实验
目标:根据给出的文本语句中的前x个单词,预测下一个单词。
在词的层次上操作,而不是在句子的层次上。
序列中的前N个单词(包括当前单词)分别被嵌入到内存中。
每个记忆单元只包含一个单词,因此不需要在QA任务中使用BoW或线性映射表示。
采用时间嵌入方法。
由于不再有任何问题,q固定在一个常数向量0.1上(不嵌入)。
输出softmax预测词汇表中的哪个单词(大小为V)是序列中的下一个单词。
采用与QA任务相同的方法,通过将错误反向传播到多个记忆层来训练模型。
为了帮助训练,对每一层的一半cell采用ReLU操作。
使用分层(RNN-like)权值共享,即每一层的查询权值相同;每一层的输出权值是相同的。
权重绑定限制了模型中参数的数量,有助于对发现对该任务有效的更深层次的模型进行泛化。
使用了两个不同的数据集:
Penn Tree Bank:它由929k/73k/82k训练/验证/测试单词组成,分布在一个10k单词的词汇表中。使用了与相同的预处理。
Text8: 这是一个预处理版本的前1亿字符,从维基百科转储。这分为93.3M/5.7M/1M字符序列/验证/测试集。所有出现次数少于5次的单词都被替换为<UNK>令牌,导致词汇表大小为44k。
结果
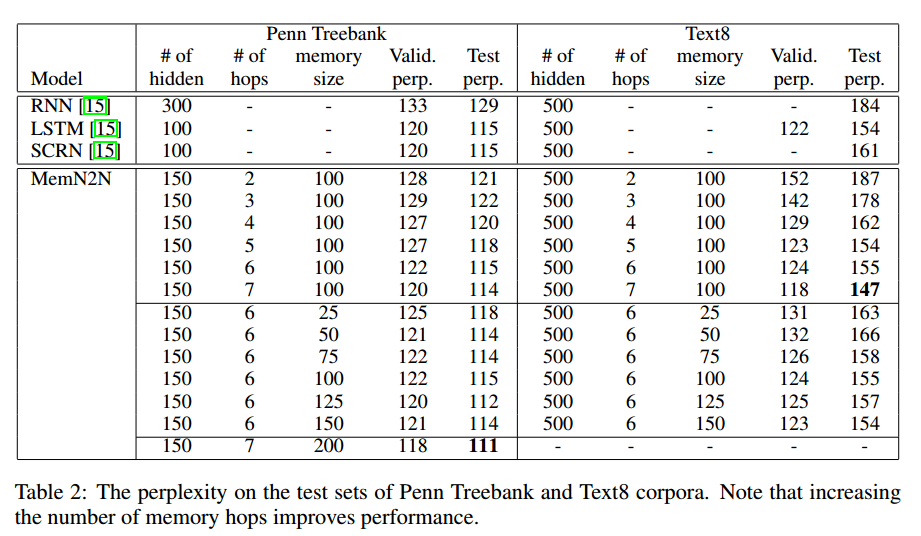
增加跳数是有帮助的。在图3中,我们展示了MemN2N如何在具有多个跃点的内存上运行。

?
5. 结论
证明了一个具有显式记忆和读取记忆的递归attention机制的神经网络可以通过反向传播成功地训练从问题回答到语言建模的各种任务。
与原来的记忆网络实现相比,没有对支持事实的监督,可以在更大范围的设置中使用。模型接近该模型的相同性能,并且显著优于具有相同监管级别的其他基线。
在语言建模任务上,它的性能略优于同等复杂度的调优RNNs和LSTMs。
在这两个任务中,增加内存跳数可以提高性能。
6. 不足与未来工作
仍旧无法精确地达到经过严格监督训练的记忆网络的性能,并且在一些1k QA任务中都失败了。
此外,平滑的查找可能无法很好地扩展到需要更大记忆的情况。
对于这些设置,作者计划探索多尺度的attention或哈希概念。
* 可以看一下相关工作中的attention概念。
【 记忆网络 2 】 End-to-End Memory Network的更多相关文章
- 【RS】Collaborative Memory Network for Recommendation Systems - 基于协同记忆网络的推荐系统
[论文标题]Collaborative Memory Network for Recommendation Systems (SIGIR'18) [论文作者]—Travis Ebesu (San ...
- 【 记忆网络 1 】 Memory Network
2015年,Facebook首次提出Memory Network. 应用领域:NLP中的对话系统. 1. 研究背景 大多数机器学习模型缺乏一种简单的方法来读写长期记忆. 例如,考虑这样一个任务:被告知 ...
- Memory Networks02 记忆网络经典论文
目录 1 Recurrent Entity Network Introduction 模型构建 Input Encoder Dynamic Memory Output Model 总结 2 hiera ...
- Memory Networks01 记忆网络经典论文
目录 1.Memory Networks 框架 流程 损失函数 QA 问题 一些扩展 小结 2.End-To-End Memory Networks Single Layer 输入模块 算法流程 Mu ...
- 如何预测股票分析--长短期记忆网络(LSTM)
在上一篇中,我们回顾了先知的方法,但是在这个案例中表现也不是特别突出,今天介绍的是著名的l s t m算法,在时间序列中解决了传统r n n算法梯度消失问题的的它这一次还会有令人杰出的表现吗? 长短期 ...
- 开源网络准入系统(open source Network Access Control system)
开源网络准入系统(open source Network Access Control system) http://blog.csdn.net/achejq/article/details/5108 ...
- Memory Network
转自:https://www.jianshu.com/p/e5f2b20d95ff,感谢分享! 基础Memory-network 传统的RNN/LSTM等模型的隐藏状态或者Attention机制的记忆 ...
- LSTM - 长短期记忆网络
循环神经网络(RNN) 人们不是每一秒都从头开始思考,就像你阅读本文时,不会从头去重新学习一个文字,人类的思维是有持续性的.传统的卷积神经网络没有记忆,不能解决这一个问题,循环神经网络(Recurre ...
- 递归神经网络之理解长短期记忆网络(LSTM NetWorks)(转载)
递归神经网络 人类并不是每时每刻都从头开始思考.正如你阅读这篇文章的时候,你是在理解前面词语的基础上来理解每个词.你不会丢弃所有已知的信息而从头开始思考.你的思想具有持续性. 传统的神经网络不能做到这 ...
随机推荐
- hue 记录
No databases are available. Permissions could be missing. Could not start SASL: Error in sasl_client ...
- nodejs & npm & gulp 安装和配置
熟悉 Hellolily的过程中,了解了这个. 环境: ubuntu 14.04 LTS 64bit 源码安装方式: 下载最新源码:如果被和谐请自行想办法. 解压并编译安装: cd node-xxx ...
- rmq区间最值
时间复杂度O(NlogN)+O(Q) int a[N]; int dpmax[N][20],dpmin[N][20]; void first(int n) { mm(dpmax,0); mm(dpmi ...
- cf 893 E
有 次询问,第 次询问包含两个数 . 求满足下面两个要求的 数组的方案数. 1. 数组由 个整数构成 2. A与B不同当且仅当至少存在一个数 满足 .答案对 取模 数据范围: 显 ...
- 窗口,父窗口parentwindow,所有者窗口ownerwindow
参考文档:http://www.cnblogs.com/fwycmengsoft/p/4026592.html 一. parent:创建者,owner:所有者 小玉的父母生下小玉,养到8岁,卖给贾府当 ...
- java学习(二)--- 变量类型
变量声明 type identifier [ = value][, identifier [= value] ...] ; 局部变量: 1.局部变量声明在方法.构造方法.语句块中 2.局部变量在方法. ...
- IIS多个应用程序共享Session
在应用程序目录下面添加一个Global.asax文件,在文件中添加以下代码: public override void Init() { base.Init(); foreach (string mo ...
- python-----函数参数类型
#函数参数类型:1 位置参数 2 默认参数 3 关键字参数 4可变参数 包裹位置参数*args 包裹关键字参数 **kargs#参数位置顺序:先位置参数,默认参数,包裹位置,包裹关键字(定义和调用都应 ...
- DELPHI中完成端口(IOCP)的简单分析(2)
DELPHI中完成端口(IOCP)的简单分析(2) 今天我写一下关于DELPHI编写完成端口(IOCP)的工作者线程中的东西.希望各位能提出批评意见.上次我写了关于常见IOCP的代码,对于IOCP ...
- Jemter 压测基础(一)——基本概念、JMeter安装使用、分布式测试、导出测试结果、编写测试报告
Jemter 压测基础(一) 1.压力测试的基本概念: 1.吞吐率(Requestspersecond) 服务器并发处理能力的量化描述,单位是reqs/s,指的是某个并发用户数下单位时间内处理的请 ...