数据结构 BM算法
BM算法是比KMP算法更快的字符串模式匹配算法。BM算法最好情况下的时间复杂度是O(n),KMP算法最好情况下的时间复杂度是O(n+m),两者最坏情况下的时间复杂度均是O(m*n)。其中,n指目标串长度,m指模式串长度。
KMP算法从左向右比较,通过失配时已匹配的字符信息来确定下一次匹配时模式串的起始位置。BM算法从右向左比较,运用了两种启发式规则:坏字符规则和好后缀规则,取这两种规则的跳跃距离大者作为P向右跳跃的距离。
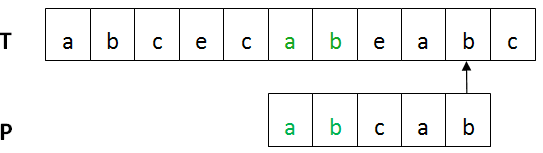
BM算法的基本流程:设目标串T,模式串为P。首先将T与P进行左对齐,然后进行从右向左比较 ,如下图所示:
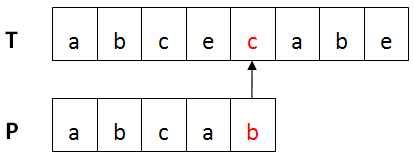
某趟比较不匹配时,通过坏字符规则和好后缀规则来计算模式串向右移动的距离,直到整个匹配过程的结束。
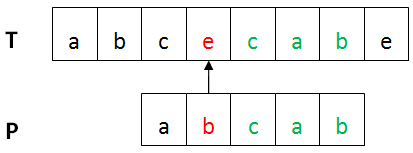
上图中,第一个不匹配的字符(红色部分)是坏字符,已匹配部分(绿色)是好后缀。
坏字符(Bad Character)规则:
出现某个字符x不匹配时,分如下两种情况讨论:
1 如果x在P中没有出现,则从x开始的m个字符不可能与P匹配成功,所以直接跳过该区域。
2 如果x在P中出现,则以该字符为基准右对齐。
设skip(x)是P右移的距离,max(x)是x在P中最右位置,用数学公式表示如下:
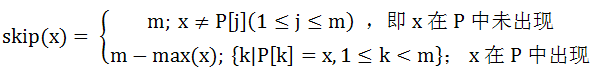
举例:
下图红色部分出现不匹配。
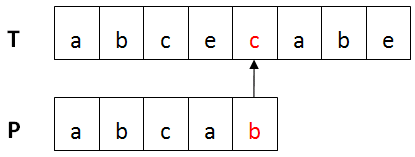
移动距离skip(c) = 5 - 3 = 2,则P向右移动2位。
移动后如下图:
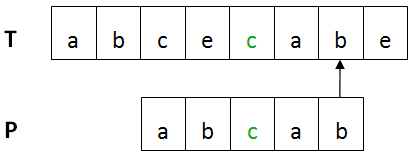
好后缀(Good Suffix)规则:
出现某个字符x不匹配时,如果已有部分字符匹配,则分如下两种情况讨论:
1 如果在P中位置t已匹配部分P'在P中的某位置t'也出现了,并且位置t'的前一个字符与位置t的前一个字符不相同,则将t'右移到t的位置。
2 如果已匹配部分P'在P中的任何位置都没有再出现,则找到与P'的后缀P''相同的在P中的最长前缀出现的位置x,将x右移到P''后缀所在的位置。
设Shift(j)是P右移的距离,j 是当前匹配的字符位置,s是t'与t的距离或者x与P''的距离,用数学公式表示如下:
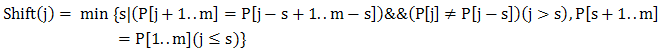
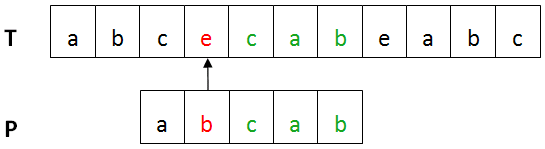
举例:
下图中,已匹配部分cab(绿色)在P中再没出现。
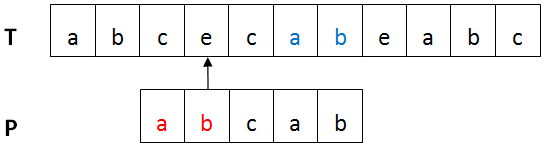
再看下图,已匹配部分P'中后缀T'(蓝色)与P中最长前缀P''(红色)匹配,则将P'移动到T'的位置。
移动后如下图:
取skip(x)与Shift(j)中的较大者作为跳跃的距离。
C语言代码
/*
函数:int* MakeSkip(char *, int)
目的:根据坏字符规则做预处理,建立一张坏字符表
参数:
ptrn => 模式串P
PLen => 模式串P长度
返回:
int* - 坏字符表
*/
int* MakeSkip(char *ptrn, int pLen)
{
int i;
//为建立坏字符表,申请256个int的空间
/*PS:之所以要申请256个,是因为一个字符是8位,
所以字符可能有2的8次方即256种不同情况*/
int *skip = (int*)malloc(*sizeof(int)); if(skip == NULL)
{
fprintf(stderr, "malloc failed!");
return ;
} //初始化坏字符表,256个单元全部初始化为pLen
for(i = ; i < ; i++)
{
*(skip+i) = pLen;
} //给表中需要赋值的单元赋值,不在模式串中出现的字符就不用再赋值了
while(pLen != )
{
*(skip+(unsigned char)*ptrn++) = pLen--;
} return skip;
} /*
函数:int* MakeShift(char *, int)
目的:根据好后缀规则做预处理,建立一张好后缀表
参数:
ptrn => 模式串P
PLen => 模式串P长度
返回:
int* - 好后缀表
*/
int* MakeShift(char* ptrn,int pLen)
{
//为好后缀表申请pLen个int的空间
int *shift = (int*)malloc(pLen*sizeof(int));
int *sptr = shift + pLen - ;//方便给好后缀表进行赋值的指标
char *pptr = ptrn + pLen - ;//记录好后缀表边界位置的指标
char c; if(shift == NULL)
{
fprintf(stderr,"malloc failed!");
return ;
} c = *(ptrn + pLen - );//保存模式串中最后一个字符,因为要反复用到它 *sptr = ;//以最后一个字符为边界时,确定移动1的距离 pptr--;//边界移动到倒数第二个字符(这句是我自己加上去的,因为我总觉得不加上去会有BUG,大家试试“abcdd”的情况,即末尾两位重复的情况) while(sptr-- != shift)//该最外层循环完成给好后缀表中每一个单元进行赋值的工作
{
char *p1 = ptrn + pLen - , *p2,*p3; //该do...while循环完成以当前pptr所指的字符为边界时,要移动的距离
do{
while(p1 >= ptrn && *p1-- != c);//该空循环,寻找与最后一个字符c匹配的字符所指向的位置 p2 = ptrn + pLen - ;
p3 = p1; while(p3 >= ptrn && *p3-- == *p2-- && p2 >= pptr);//该空循环,判断在边界内字符匹配到了什么位置 }while(p3 >= ptrn && p2 >= pptr); *sptr = shift + pLen - sptr + p2 - p3;//保存好后缀表中,以pptr所在字符为边界时,要移动的位置
/*
PS:在这里我要声明一句,*sptr = (shift + pLen - sptr) + p2 - p3;
大家看被我用括号括起来的部分,如果只需要计算字符串移动的距离,那么括号中的那部分是不需要的。
因为在字符串自左向右做匹配的时候,指标是一直向左移的,这里*sptr保存的内容,实际是指标要移动
距离,而不是字符串移动的距离。我想SNORT是出于性能上的考虑,才这么做的。
*/ pptr--;//边界继续向前移动
} return shift;
} /*
函数:int* BMSearch(char *, int , char *, int, int *, int *)
目的:判断文本串T中是否包含模式串P
参数:
buf => 文本串T
blen => 文本串T长度
ptrn => 模式串P
PLen => 模式串P长度
skip => 坏字符表
shift => 好后缀表
返回:
int - 1表示成功(文本串包含模式串),0表示失败(文本串不包含模式串)。
*/
int BMSearch(char *buf, int blen, char *ptrn, int plen, int *skip, int *shift)
{
int b_idx = plen;
if (plen == )
return ;
while (b_idx <= blen)//计算字符串是否匹配到了尽头
{
int p_idx = plen, skip_stride, shift_stride;
while (buf[--b_idx] == ptrn[--p_idx])//开始匹配
{
if (b_idx < )
return ;
if (p_idx == )
{
return ;
}
}
skip_stride = skip[(unsigned char)buf[b_idx]];//根据坏字符规则计算跳跃的距离
shift_stride = shift[p_idx];//根据好后缀规则计算跳跃的距离
b_idx += (skip_stride > shift_stride) ? skip_stride : shift_stride;//取大者
}
return ;
}
参考资料
数据结构 BM算法的更多相关文章
- hrbustoj 1551:基础数据结构——字符串2 病毒II(字符串匹配,BM算法练习)
基础数据结构——字符串2 病毒IITime Limit: 1000 MS Memory Limit: 10240 KTotal Submit: 284(138 users) Total Accepte ...
- 数据结构与算法 Big O 备忘录与现实
不论今天的计算机技术变化,新技术的出现,所有都是来自数据结构与算法基础.我们需要温故而知新. 算法.架构.策略.机器学习之间的关系.在过往和技术人员交流时,很多人对算法和架构之间的关系感 ...
- 数据结构 Sunday算法
Sunday算法是Daniel M.Sunday于1990年提出的字符串模式匹配算法.相对比较KMP和BM算法而言,简单了许多. Sunday算法的思想类似于BM算法中的坏字符思想,有点像其删减版.差 ...
- 字符串匹配算法之BM算法
BM算法,全称是Boyer-Moore算法,1977年,德克萨斯大学的Robert S. Boyer教授和J Strother Moore教授发明了一种新的字符串匹配算法. BM算法定义了两个规则: ...
- java之数据结构与算法
1.了解基本数据结构及特点 如,有哪些二叉树,各有什么特点 树二叉搜索树 每个节点都包含一个值,每个节点至多有两棵子树,左孩子小于自己,右孩子大于自己,时间复杂度是O(log(n)),随着不断插入节点 ...
- 开启基本数据结构和算法之路--初识Graphviz
在我的Linux刀耕开荒阶段,就想开始重拾C,利用C实现常用的基本数据结构和算法,而数据结构和算法的掌握的熟练程度正是程序的初学者与职业程序员的分水岭. 那么怎么开启这一段历程呢? 按照软件工程的思想 ...
- 【转】MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- [转]MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
随机推荐
- Hyper-V 替换 vmwp
要激活 Hyper-V 下的虚机 最简单的方法是用带证书的vmwp替换掉原来的 带证书的vmwp参见:http://bbs.pcbeta.com/viewthread-1408240-1-1.html ...
- 彻底明确怎样设置minSdkVersion和targetSdkVersion
minSdkVersion和targetSdkVersion相信非常多人都不太理解.我在网上也看了很多关于这两者差别的文章,感觉说的都非常模糊.直到我在stackOverFlow看到Android M ...
- javascript var变量删除
var有三种声明的情形: var声明的全局变量 var在函数范围内声明的局部变量 eval中声明的全局变量. 首先, 1.2种情形var声明的变量是无法删除的. 尽管var声明的全局变量是属于wind ...
- Note for "Some Remarks on Writing Mathematical Proofs"
John M. Lee is a famous mathematician, who bears the reputation of writing the classical book " ...
- Spring Boot配置文件放在jar外部
Spring Boot程序默认从application.properties或者application.yaml读取配置,如何将配置信息外置,方便配置呢? 查询官网,可以得到下面的几种方案: 通过命令 ...
- django引入现有数据库 转
django引入现有数据库 Django引入外部数据库还是比较方便的,步骤如下: 1.创建一个项目,修改seting文件,在setting里面设置你要连接的数据库类型和连接名称,地址之类,和创建新 ...
- 关于appium-doctor运行时提示不是内部或外部的命令
1.一定要单独配置android_home (我之前是直接将D:\SDK\platform-tools;D:\SDK\tools;加到path里面会导致appnium-doctor运行时失败,原因为A ...
- 51Nod1306 高楼和棋子 动态规划
原文链接https://www.cnblogs.com/zhouzhendong/p/51Nod1306.html 题目传送门 - 51Nod1306 题意 有个N层的高楼和若干个棋子,所有的棋子都是 ...
- HDU4622 Reincarnation 字符串 SAM
原文链接https://www.cnblogs.com/zhouzhendong/p/HDU4622.html 题目传送门 - HDU4622 题意 多组数据. 对于每一组数据,给定一个字符串 s , ...
- L3-001 凑零钱 (30 分) dfs加后缀剪枝
韩梅梅喜欢满宇宙到处逛街.现在她逛到了一家火星店里,发现这家店有个特别的规矩:你可以用任何星球的硬币付钱,但是绝不找零,当然也不能欠债.韩梅梅手边有 1 枚来自各个星球的硬币,需要请你帮她盘算一下,是 ...