预训练模型时代:告别finetune, 拥抱adapter
NLP论文解读 原创•作者 |FLIPPED
研究背景
随着计算算力的不断增加,以transformer为主要架构的预训练模型进入了百花齐放的时代。BERT、RoBERTa等模型的提出为NLP相关问题的解决提供了极大的便利,但也引发了一些新的问题。
首先这些经过海量数据训练的模型相比于一般的深度模型而言,包含更多的参数,动辄数十亿。在针对不同下游任务做微调时,存储和训练这种大模型是十分昂贵且耗时的。
尤其对于机器翻译任务而言,如果针对一对语言对就需要存储和微调这样一个”庞然大物“,显然在时间和空间上都是不可接受的。
为了解决这个问题,以轻量和扩展性强闻名的Adapter方法被提出,相比于“劳民伤财”的全参数微调,它只需要以一个较小的训练和存储代价就可以取得和全模型微调相当的结果。
1、Adapter方法介绍
首先adapter方法的原理并不复杂,它是通过在原始的预训练模型中的每个transformer block中加入一些参数可训练的模块实现的。
假设原始的预训练模型的参数为ω,加入的adapter 参数为υ,在针对不同下游任务进行调整时,只需要将预训练参数固定住,只针对adapter参数υ进行训练。
通常情况下,参数量υ<<ω, 因此在对多个下游任务调整时,只需要调整极小数量的参数,大大的提高了预训练模型的扩展性和实用性。
对于adapter模块的网络组成,不同文章中针对不同任务略有不同。但是比较一致的结论是,bottleneck形式的两层全连接神经网络就已经可以满足要求。
在Houlsby[1]的文章中,每个transformer 层中有两个adapter模块,在每个adapter模块中,先将经过多头注意力和前馈层输出的output做一个降维的映射。
经过一个非线性激活层后,再将特征矢量映射回原始的维度。在下游训练任务中,只更新adapter模块和layer Norm 层(图一中的绿色部分)。
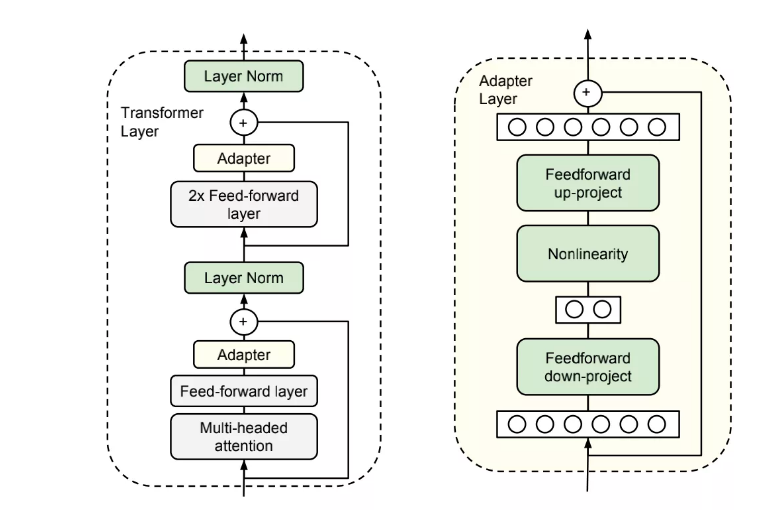
图1:elf-training的数据选择方法
相比于预训练模型的全参数微调,Adapter 方法的优势十分明显:
(1)针对不同下游任务可保持预训练模型不变,仅需训练adapter模块的少量参数,训练代价小,可移植性强。
(2)对于不同任务的连续学习(continual learning)而言,由于在训练不同任务时只需要训练不同的adapter,其他模型参数保持不变,避免了在学习新任务时对过往任务的遗忘。
2、Adapter 在神经机器翻译(NMT)中的应用
机器翻译是adapter大展拳脚的一个重要舞台,尤其是在处理领域自适应和多语言翻译问题上:
(1)领域自适应: 利用领域外的数据训练模型,进而提升在领域内数据的翻译表现。
(2)多语言翻译问题:对于新给的一个低资源的语言对数据,如何利用已有的翻译模型来提高在新语言对上的翻译表现。
在这两个比较典型的任务上,常用的方法仍然是基于整个模型的微调,然而对于持续不断地新任务(新的领域数据或者新语言对数据),显然adapter 嵌入调整的方法更具有优势。
Ankur Bapna [2]在论文中针对这两个问题给出了通用的解决方法,如下图所示。
针对不同的语言对或者领域数据,配置对应的adapter 模块分别训练,由于每个模块的参数量较小,所以总体训练的代价也较小。
同时因为原始模型的参数是固定不动的,所以原始任务的推理并不会受到新任务的干扰。
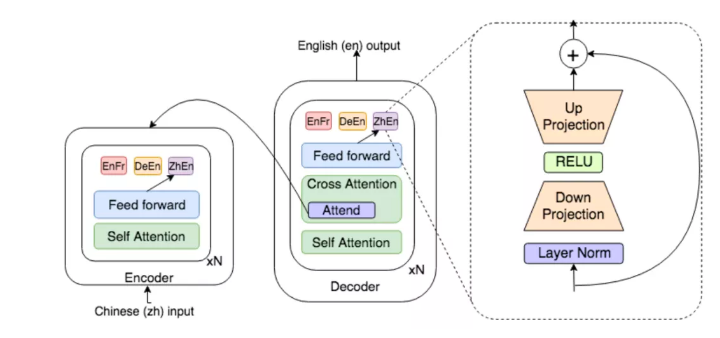
图2 多语言问题中的transformer模块和adapter 模块
实验结果方面,在领域自适应任务中,对比了微调方法、LHUC(在预训练模型中加入一些门控参数)、和adapter 微调的方法。
如表一所示,base模型是将WMT中的英法语言对作为领域外的数据进行预训练的结果,需要在IWSLT和JRC两个领域内数据的数据集上做微调对比。可以看出,Adapter方法取得了与全模型finetune方法相当甚至更好地结果。
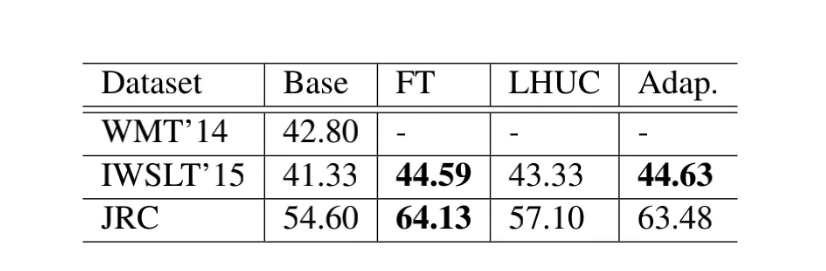
表一 :在领域适配问题上不同调整策略的表现
在多语言任务中,adapter调整策略略有不同。因为不同语言对的输入输出分布各不相同,进而造成了encoder端的embedding层和输出端的softmax层的差异较大。
因此对于一些语料数据充足的语言对来说,其对应adapter的训练需要做进一步的调整优化。
为此文章提出了两阶段训练的方法:
(1)全局训练阶段:利用所有语言对训练一个完全共享的预训练模型。
(2)局部精炼阶段:对于一些训练语料充足的语言对,对其adapter在本领域内数据做进一步局部调整。
这一步主要是为了弥补在全局训练阶段在全数据集上训练造成的性能损失。
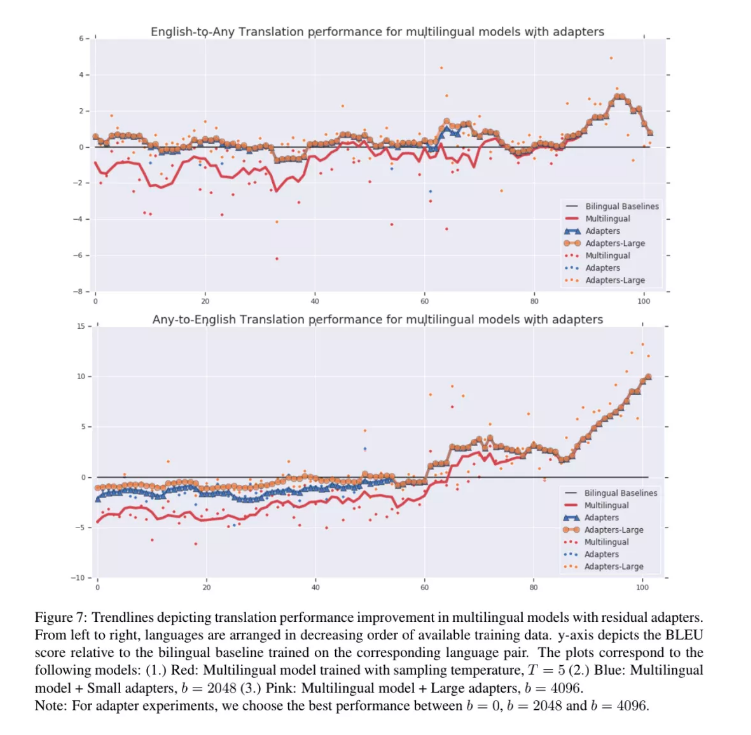
图3 包含103种语言的多语言模型采用不同调整方式的推理效果
x轴从左到右按照语言对数据量大小由多到少排列;
y轴,相对于双语模型BLEU分表现
由上图可以看出,两阶段训练的方法极大的弥补了常规多语言模型在富语料问题上的损失,并且对于低资源的语言对,利用adapter调整过的多语言模型的翻译效果要明显优于双语模型。
此外,adapter训练的灵活性和轻量化也极大的方便了该方法在不同语言对上的应用。
3、adapter开源库
既然adapter有这么多好处,那有没有比较好的开源库可以直接用呢?答案当时是有的。我们都知道huggingface 开源的transformer 库十分的方便易用,各种SOTA的BERT、RoBERTa预训练模型应有尽有。
但是更贴心的是,他们在原来框架的基础上增添了adapter 模块的训练和扩展——AdapterHub[3],用户只需要在原来的训练脚本中更改不超过两行的代码,就可以针对不同的下游任务无缝训练新的adapter模块,并且整个adapter模块的参数和原始的预训练模型参数是完全独立存储的。
此外,该库的另一大特点就是完全开源与共享,如下图所示,每个用户都可以基于huggingface提供的预训练模型训练并上传自己的adapter模块,而其他用户也可以根据个人的任务选择对应的预训练adapter模块直接使用。
具体细节感兴趣的同学可以参考他们的github仓库:
https://github.com/Adapter-Hub/adapter-transformers
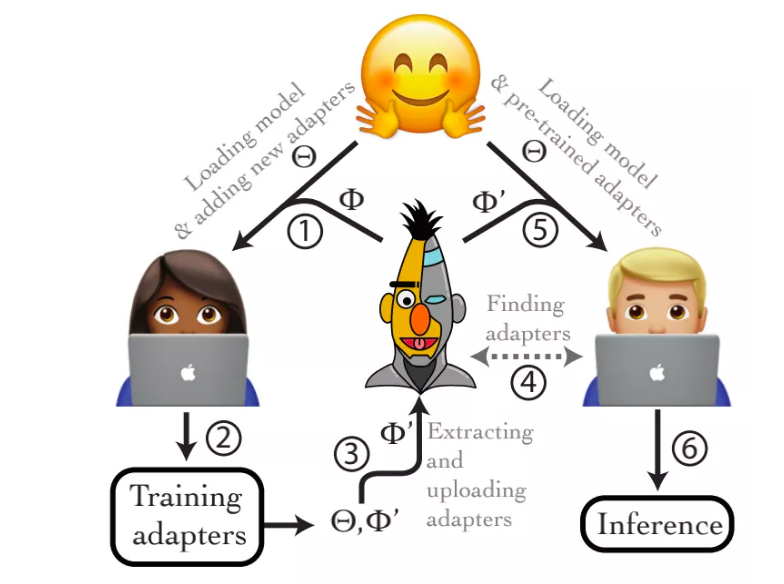
图4 AdapterHub 应用流程图
随着深度学习逐渐进入预训练模型时代,如何针对不同下游任务微调出一个更好地目标模型受到了越来越多学者的关注。
相比于全模型上的finetune, 轻量化和扩展性更强的adapter 方法显然更具优势,而如何将不同任务的adapter进行融合进而提升预训练模型在多任务学习上的表现,也将会是未来该领域一个重要的发展方向。
参考文献:
[1] Houlsby N, Giurgiu A, Jastrzebski S, et al.
Parameter-efficient transfer learning for NLP[C]//International Conference on Machine Learning. PMLR, 2019: 2790-2799.
[2] Bapna A, Firat O. Simple, Scalable Adaptation for Neural Machine Translation[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 1538-1548.
[3] Pfeiffer J, Rücklé A, Poth C, et al. AdapterHub: A Framework for Adapting Transformers[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020: 46-54.
预训练模型时代:告别finetune, 拥抱adapter的更多相关文章
- Paddle预训练模型应用工具PaddleHub
Paddle预训练模型应用工具PaddleHub 本文主要介绍如何使用飞桨预训练模型管理工具PaddleHub,快速体验模型以及实现迁移学习.建议使用GPU环境运行相关程序,可以在启动环境时,如下图所 ...
- PyTorch保存模型与加载模型+Finetune预训练模型使用
Pytorch 保存模型与加载模型 PyTorch之保存加载模型 参数初始化参 数的初始化其实就是对参数赋值.而我们需要学习的参数其实都是Variable,它其实是对Tensor的封装,同时提供了da ...
- 我的Keras使用总结(4)——Application中五款预训练模型学习及其应用
本节主要学习Keras的应用模块 Application提供的带有预训练权重的模型,这些模型可以用来进行预测,特征提取和 finetune,上一篇文章我们使用了VGG16进行特征提取和微调,下面尝试一 ...
- 百度NLP预训练模型ERNIE2.0最强实操课程来袭!【附教程】
2019年3月,百度正式发布NLP模型ERNIE,其在中文任务中全面超越BERT一度引发业界广泛关注和探讨.经过短短几个月时间,百度ERNIE再升级,发布持续学习的语义理解框架ERNIE 2.0,及基 ...
- 自然语言处理(三) 预训练模型:XLNet 和他的先辈们
预训练模型 在CV中,预训练模型如ImagNet取得很大的成功,而在NLP中之前一直没有一个可以承担此角色的模型,目前,预训练模型如雨后春笋,是当今NLP领域最热的研究领域之一. 预训练模型属于迁移学 ...
- 我的Keras使用总结(3)——利用bottleneck features进行微调预训练模型VGG16
Keras的预训练模型地址:https://github.com/fchollet/deep-learning-models/releases 一个稍微讲究一点的办法是,利用在大规模数据集上预训练好的 ...
- 【AI】Pytorch_预训练模型
1. 模型下载 import re import os import glob import torch from torch.hub import download_url_to_file from ...
- 告别node-forever,拥抱PM2
告别node-forever,拥抱PM2 返回原文英文原文:Goodbye node-forever,hello PM2 devo.ps团队对JavaScript的迷恋已经不是什么秘密了;node.j ...
- 使用MxNet新接口Gluon提供的预训练模型进行微调
1. 导入各种包 from mxnet import gluon import mxnet as mx from mxnet.gluon import nn from mxnet import nda ...
随机推荐
- nextcloud搭建私有云盘
一.基础环境准备 1.安装一台centos7的linux服务器. # 系统初始化 # 如果时区不对,请修改时区 #mv /etc/localtime /etc/localtime_bak #ln -s ...
- Spark(八)【利用广播小表实现join避免Shuffle】
目录 使用场景 核心思路 代码演示 正常join 正常left join 广播:join 广播:left join 不适用场景 使用场景 大表join小表 只能广播小表 普通的join是会走shuff ...
- C++11的auto自动推导类型
auto是C++11的类型推导关键字,很强大 例程看一下它的用法 #include<vector> #include<algorithm> #include<functi ...
- SVN的基本介绍\服务器配置
### 1. 工作场景 1. 进入公司需要做的关于开发的第一件事, 就是向项目经理索要SVN服务器地址+用户名+密码### 2. 角色解释> 服务器: 用于存放所有版本的代码,供客户端上传下载更 ...
- 01_ubantu国内软件源配置
查找自己版本对应的软件源 https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/ 以下为19.10版本清华大学的,个人100M的带宽,平均安装速度在600K ...
- my38_MySQL事务知识点零记
从innodb中查看事务信息 show engine innodb status\G; ------------ TRANSACTIONS------------Trx id counter 3153 ...
- 网页设计单位 px,em,rem,vm,vh,%
px(pixels) 像素 (px) 是一种绝对单位,因为无论其他相关的设置怎么变化,像素指定的值是不会变化的. px就是设备或者图片最小的一个点,比如常常听到的电脑像素是1024x768的,表示的是 ...
- spring整合mybatis和springmvc的配置概图
- synchronized底层浅析(二)
一张图了解锁升级流程:
- 论文翻译:2021_A Perceptually Motivated Approach for Low-complexity, Real-time Enhancement of Fullband Speech
论文地址:一种低复杂度实时增强全频带语音的感知激励方法 论文代码 引用格式:A Perceptually Motivated Approach for Low-complexity, Real-tim ...