常用文本处理命令 & 三剑客之 sed
今日内容
- 文本处理命令
- Linux 三剑客之 sed
内容详细
文本处理命令
1、sort : 文件内容排序
默认按照文件隔行内容的第一个字符大小进行排序(默认是升序)
默认输出文本结果
sort [参数] [操作对象]
[root@localhost tmp]# sort test
232
34
454
455
[root@localhost tmp]# sort test2
a
A
aa
AA
Ab
ba
Bb
# 如果是英文字符,则是按照 ascii 表的大小比较,且同字母的大小写会先进行比较,字母相同的位数会先比。
参数:
-n 依照数值的大小排序
[root@localhost tmp]# sort -n test
34
89
89
232
454
# 按照数值的大小比较
-r 以相反的顺序来排序
[root@localhost tmp]# sort -r test
909
89
89
677
# 与 n 比较数字大小配合使用
[root@localhost tmp]# sort -rn test
909
677
576
455
455
454
232
89
-k 以某列进行排序
# 以第二列第一个数字的大小进行升序排序
[root@localhost tmp]# sort -k2 test
909 235
576 4323
34 454
455 4667
# 与 n、r 配合使用,用数值大小进行倒序(降序)进行排序
[root@localhost tmp]# sort -k2nr test
454 97867
89 7887
232 6578
89 5456
-t 指定分割符,默认是以空格为分隔符
默认不能用 tab 符来分隔,先进行转义 : -t$'\t'
[root@localhost tmp]# sort -t$'\t' test
232 6578
34 454
454 97867
455 4667
2、uniq :检查和删除文本中重复出现的行列
用于检查和删除文本中重复出现的行列,注意,只有相邻并且重复的内容才会被识别出来,一般与 sort 命令结合使用
uniq [参数] [被操作对象]
[root@localhost tmp]# cat test3
456
456
867
867
867
456
456
9877
9877
[root@localhost tmp]# uniq test3
456
867
456
9877
# 由此可见:只有相邻并且重复的内容才会被识别出来,
# 解决 : 与 sort 命令结合使用,先排序才去重
参数:
-c : 每列旁边显示该行重复出现的次数
sort -nr test3 | uniq -c
先用 sort 进行数值降序排序,再进行去重并统计每行重复次数
[root@localhost tmp]# sort -nr test3 | uniq -c
3 9877
4 867
6 456
-d : 仅显示重复出现的行列
sort -nr test3 | uniq -d
先进行排序,再显示重复出行的行列
[root@localhost tmp]# sort -nr test3 | uniq -d
9877
867
456
-u : 仅显示出现一次的行列
uniq -u test3
[root@localhost tmp]# uniq -u test3
abcde
fghij
3、cut 显示行中指定部分,删除文件指定字段
cut命令可以从一个文本文件或者文本流中提取文本列
(切割必须指定字节、字符或字段的列表)
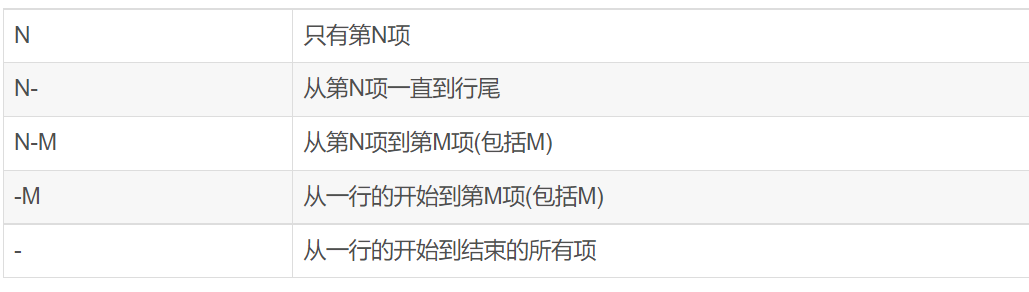
cut -f list [-d delim][-s] [file ...]
[root@localhost tmp]# cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
[root@localhost ~]# cut -f1 -d':' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
# passwd 用户信息文件内容以 : 为分隔符分隔为多列,顺利地
参数:
-d :指定字段的分隔符,默认的字段分隔符为"TAB"
cut -d':' /etc/passwd
将 passwd 中的内容以冒号 ':' 为分割符分割成好几列
-f : 显示指定字段的内容
cut -f1 /etc/passwd
取出 passwd 中分列之后的第一个字段的所有内容
4、tr : 替换或删除命令
可以将 tr 看作为 sed的(极其)简化的变体:
它可以用一个字符来替换另一个字符
可以完全除去一些字符
也可以用它来除去重复字符
替换字符
[root@localhost tmp]# cat test3
456
456
456
867
867
# 把 456 替换成 son
注意:替换是一个一个字符相对位置替换的,也就是 s 替换了 4, o 替换了 5, n 替换了 6
[root@localhost tmp]# cat test3 | tr '456' 'son'
son
son
son
8n7
8n7
-d : 删除字符
cat test3 | tr -d '123'
[root@localhost tmp]# cat test3 | tr -d '456'
87
87
# 成功删除 456
5、wc : 统计,计算数字
默认会统计文件的 行数(l)、单词个数(w)、文件大小(c)
[root@localhost tmp]# wc test3
15 17 75 test3
行数 单词数 文件大小
-l : 统计文件的行数
[root@localhost tmp]# wc -l test3
15 test3
-w : 统计文件中单词的个数,默认以空白字符做为分隔符
[root@localhost tmp]# wc -w test3
17 test3
-c : 统计文件的Bytes数
[root@localhost tmp]# wc -c test3
75 test3
Linux 三剑客之 sed
三剑客:
grep : 过滤文件
sed : 更改文件
awk : 处理文件
sed是linux中的流媒体编辑器
1、语法格式
sed [参数] '处理规则' [操作对象]
2、参数
-e : 允许多项编辑
[root@localhost tmp]# cat 1.txt
heihei
eat tanyuan
wowowo
wowowowo
# 把 1.txt 文件第 1 行和第 3 行删除
[root@localhost tmp]# sed -e '1d' -e '3d' 1.txt
eat tanyuan
wowowowo
-n : 取消默认输出
# 打印第二行
[root@localhost tmp]# sed '2p' 1.txt
heihei
eat tanyuan
eat tanyuan < -- 多打印的一行
wowowo
wowowowo
# 取消其它的默认输出行
[root@localhost tmp]# sed -n '2p' 1.txt
eat tanyuan
-i : 就地编辑
就地编辑会把 指定打印 的内容直接编辑进文件里面去(正常使用 sed 的时候都只会在终端输出更改结果,不会直接写入文件)
删除效果也可以直接作用到文件中
就地编辑 : 把更改过的效果写入到文件里面去,真实修改
[root@localhost tmp]# cat 1.txt
heihei
eat tanyuan
wowowo
wowowowo
# 直接把打印的第二行内容写入了 1.txt 文件中
[root@localhost tmp]# sed -i '2p' 1.txt
[root@localhost tmp]# cat 1.txt
heihei
eat tanyuan
eat tanyuan
wowowo
wowowowo
-r : 支持拓展正则
-f : 指定 sed 匹配规则脚本文件
[root@localhost tmp]# cat 1.txt
heihei
eat tanyuan
wowowo
wowowowo
# 可以把复杂的正则表达式写入另一个脚本文件中,要使用正则表达式的时候可以用 -f 来调用脚本文件
vim role.
3、定位
d : sed的编辑模式 --> 删除
p : 打印
1、数字定位法
[root@localhost tmp]# cat -n test3
1 456
2 456
3 456
4 456
5 867
6 867
# 定位文件的第三行,删除 d
[root@localhost tmp]# cat -n test3 | sed '3d'
1 456
2 456 < -- 第三行被删除了
4 456
5 867
6 867
# 定位到内容第二和第四行,会删除内容的 3到4 行
[root@localhost tmp]# cat -n test3 | sed '2,4d'
1 456 < -- 第 2 到 第 4 行被删除了
5 867
6 867
2、正则定位法
把正则表达式写在 引号的 / / 内
在 grep 中,正则规则写在 单引号中,在 sed 里正则规则要写到 / / 符号里面,外加引号添加更改选项
[root@localhost tmp]# cat test3
456
456
867
867
# 删除以四开头的内容
[root@localhost tmp]# sed '/^4/d' test3
867
867
3、数字和正则定位法
[root@localhost tmp]# cat test3
456
456
456
456
867
867
# 删除第 2 行到 以 8 开头的内容
[root@localhost tmp]# sed '2,/^8/d' test3
456
867
4、正则正则定位法
[root@localhost tmp]# cat test3
456
456
456
867
867
867
867
456
# 把以 8 开头 到以 4 开头 的内容删除
[root@localhost tmp]# sed '/^8/,/^4/d' test3
456
456
456
456
4、sed 的编辑模式:
d : 删除
[root@localhost tmp]# cat -n test3
1 456
2 456
3 456
4 456
5 867
6 867
# 定位文件的第三行,删除 d
[root@localhost tmp]# cat -n test3 | sed '3d'
1 456
2 456 < -- 第三行被删除了
4 456
5 867
6 867
p : 打印
# 打印 1.txt 文件的第二行
[root@localhost tmp]# sed '2p' 1.txt
heihei
eat tanyuan
eat tanyuan < -- 打印出来的第二行
wowowo
wowowowo
a : 在当前行后添加一行或多行
# 在文本的第二行之后添加 内容
[root@localhost tmp]# cat -n test3 | sed '2alixiaoze i am sorry'
1 456
2 456
lixiaoze i am sorry
3 456
4 456
c : 用新文本修改(替换)当前行
# 把文本第二行内容替换成 c 后面的内容
[root@localhost tmp]# cat -n test3 | sed '2cxiaoze wo cuo le'
1 456
xiaoze wo cuo le
3 456
4 456
5 867
r : 在文件中读内容
# 1.txt 中的内容:
[root@localhost tmp]# cat 1.txt
xiaoze qing yuanliang
# forgive 中的内容:
[root@localhost tmp]# cat forgive
heihei
eat tanyuan
wo
# 把 1.txt 中所有内容读取到 forgive 文件内容的第二行下方
[root@localhost tmp]# sed '2r 1.txt' forgive
heihei
eat tanyuan
xiaoze qing yuanliang
wo
w : 将指定行写入文件
# 把 1.txt 中的第三行内容写入到 forgive 文件中去
[root@localhost tmp]# sed '3w forgive' 1.txt
[root@localhost tmp]# cat forgive
wo
y : 将字符转换成另一个字符
# 将 1.txt 文件第三行中的 wo 转换成 WO
[root@localhost tmp]# sed '3y/wo/WO/' 1.txt
heihei
eat tanyuan
WO
wo
i : 在当前行之前,插入文本(单独使用时)
# 在第二行之前,插入内容
[root@localhost tmp]# cat -n test3 | sed '2ixiaoze forgive me please~~'
1 456
xiaoze forgive me please~~
2 456
3 456
4 456
i : 忽略大小写(与s模式一起使用时)
# 把 1.txt 文件内容中全部字符 wo 转换成 HE, 全部执行,忽略大小写
[root@localhost tmp]# sed 's/wo/HEE/gi' 1.txt
heihei
eat tanyuan
HEEHEEHEE
HEEHEEHEEHEE
s : 将字符串转换成另一个字符串(每一行只替换一次)
[root@localhost tmp]# cat 1.txt
heihei
eat tanyuan
wowowo
wowowowo
# 把 1.txt 文件内容中每一行的第一个字符 wo 转换成 HE
sed 's/wo/HEE/' 1.txt
[root@localhost tmp]# sed 's/wo/HEE/' 1.txt
heihei
eat tanyuan
HEEwowo
HEEwowowo
g : 全部执行(一般配合 s 使用)
# 把 1.txt 文件内容中全部字符 wo 转换成 HE, 全部执行
[root@localhost tmp]# sed 's/wo/HEE/g' 1.txt
heihei
eat tanyuan
HEEHEEHEE
HEEHEEHEEHEE
常用文本处理命令 & 三剑客之 sed的更多相关文章
- linux100day(day3)--常用文本处理命令和vim文本编辑器
今天,来介绍几个常用文本处理命令和vim文本编辑器 day3--常用文本处理命令和vim文本编辑器 col,用于过滤控制字符,-b过滤掉所有控制字符,这个命令并不常用,但可以使用man 命令名| co ...
- 005 Linux 命令三剑客之-sed
grep:数据查找定位 awk:数据切片,数据格式化,功能最复杂 sed:数据修改 01 Linux 命令三剑客? 三剑客各有所长,和锅锅一一搞起就是了! sed:擅长数据修改. grep:擅长数据查 ...
- linux学习-常用文本处理命令
1.文本处理命令 (1) tr 转换或删除字符 tr [OPTION]...SET1 SET2 选项: -c 取SET1字符串的补集 -d 删除属于SET1中的字符 -s 把连续重复出现的字符以单独一 ...
- linux常用文本编缉命令(strings/sed/awk/cut)
一.strings strings--读出文件中的所有字符串 二.sed--文本编缉 类型 命令 命令说明 字符串替换 sed -i 's/str_reg/str_rep/' filename 将文件 ...
- Linux常用文本处理命令
1.grep命令 echo 'zero\nzo\nzoo' | grep 'z.*o':将匹配以'z'开头以'o'结尾的所有字符串 echo 'zero\nzo\nzoo' | grep 'z.o': ...
- linux命令三剑客之一sed
a(a\或者a\\):在当前行后面加入一行文本sed '/^test/a---->this is a example2' example 在test开头的行下,添加一行新的文本“----> ...
- 【文本处理命令】之sed命令详解
sed行处理命令详解 一.简介 sed命令是一种在线编辑器.一个面向字符流的非交互式编辑器,也就是说sed不允许用户与它进行交互操作.sed是按行来处理文本内容的,它一次处理一行内容.处理时,把当前处 ...
- 文本处理命令--wc、sed
一.wc wc命令的功能为统计指定文件中的字节数.字数.行数,并将统计结果显示输出. 测试文件内容: (my_python_env)[root@hadoop26 ~]# cat test hnlinu ...
- 文本处理命令(sort+uniq+cut+tr+wc)+三剑客之sed
目录 文本处理命令+三剑客之sed 一.文本处理命令 1.排序命令 sort 2.检查/删除命令 uniq 3. cut 显示特定部分命令 4. 替换或删除命令 tr 5.统计 计算数字命令 wc 二 ...
随机推荐
- vscode中关闭python默认自动提示
vscode中python的默认自动代码提示工具是Jedi,我现在用的是kite.默认情况下连个自动补全工具会同时工作,提示窗口会重复出现相同的代码.以下操作可以关闭Jedi.
- [转]Vue之引用第三方JS插件
1.绝对路径引入,全局使用. 在index.html文件中使用script标签引入插件. 该种方式就是上面演示ckplayer插件使用的方式. 备注: 这种方式的引用,会在开启ESLint时,报错,可 ...
- 转雅虎web前端网站优化 34条军规
雅虎给出了优化网站加载速度的34条法则(包括Yslow规则22条) 详细说明,下载转发 ponytail 的译文 1.Minimize HTTP Requests 减少HTTP请求 图片.css.sc ...
- Android官方文档翻译 十七 4.1Starting an Activity
Starting an Activity 开启一个Activity This lesson teaches you to 这节课教给你 Understand the Lifecycle Callbac ...
- 【刷题-LeetCode】122 Best Time to Buy and Sell Stock II
Best Time to Buy and Sell Stock II Say you have an array for which the ith element is the price of a ...
- prometheus基本概念(思维导图)
参考文章: prometheus词汇表 prometheus的summary和histogram指标的简单理解
- 一次神奇的Azure speech to text rest api之旅
错误Max retries exceeded with url: requests.exceptions.ConnectionError: HTTPSConnectionPool(host='%20e ...
- 阿里巴巴如何进行测试提效 | 阿里巴巴DevOps实践指南
编者按:本文源自阿里云云效团队出品的<阿里巴巴DevOps实践指南>,扫描上方二维码或前往:https://developer.aliyun.com/topic/devops,下载完整版电 ...
- 2022GDUT寒训专题一C题
题目 题面 马在中国象棋以日字形规则移动. 请编写一段程序,给定n×m大小的棋盘,以及马的初始位置 (x, y),要求不能重复经过棋盘上的同一个点,计算马可以有多少途径遍历棋盘上的所有点. 输入格式 ...
- dubbo系列一、dubbo启动流程
目录 dubbo启动流程分析记录 一.dubbo provider启动流程 1.自动装配 2.ServiceBean处理 3.服务暴露export() 3.1.检测dubbo.xxx.配置属性,配置到 ...