[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency
Semi-Supervised Semantic Segmentation with High- and Low-level Consistency
创新点:
利用两个分支结构分别处理low-level和high-level的特征,进行半监督语义分割
网络结构
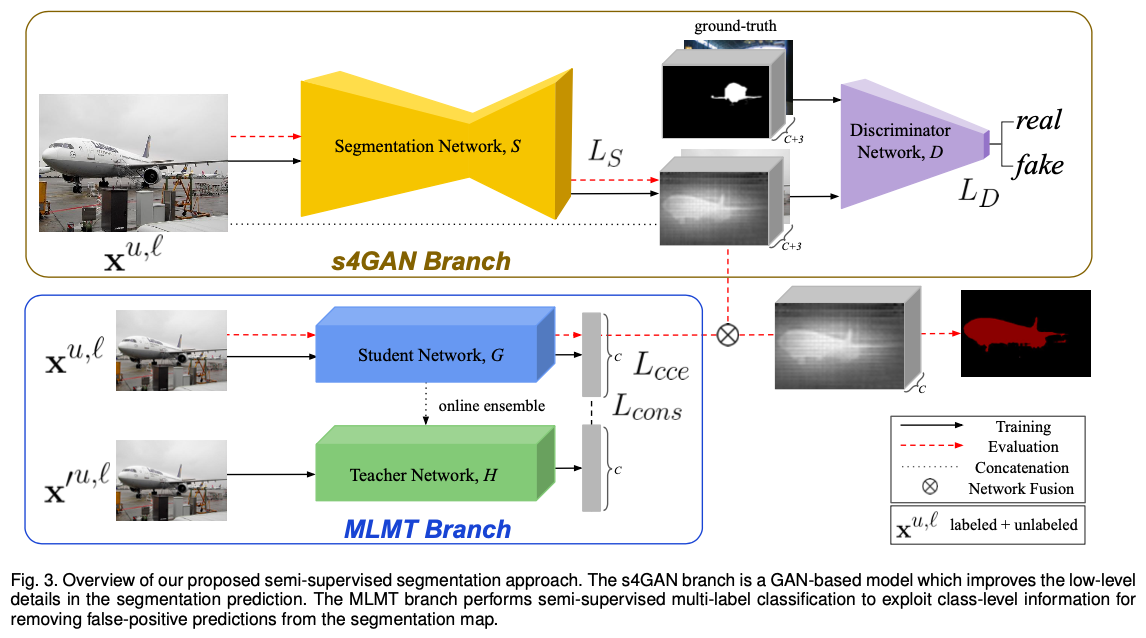
上分支:Semi-Supervised Semantic Segmentation GAN (s4GAN)
下分支:Multi-Label Mean Teacher (MLMT)
s4GAN
训练segmentation network \(S\)
segmentation network \(S\)的损失函数由以下三部分组成:
- Cross-entropy loss
输入原图到segmentation network \(S\)中,对于labeled images,输出的分割结果\(S(x^l)\)和标签\(y^l\)对比,计算交叉熵损失\(L_{ce}\)
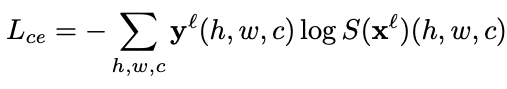
- Feature matching loss
为了使得分割结果\(S(x^l)\)和标签\(y^l\)的特征分布尽可能一致,本文计算分割结果\(S(x^l)\)和标签\(y^l\)的特征分布差异mean discrepancy,并设计Feature matching loss
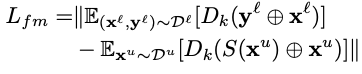
上式中\(D_k\)表示discriminator的第\(k\)层
注:此Feature matching loss适用于有标签和无标签的数据 - Self-training loss
本文认为,在训练过程中generator和discriminator需要达到某种平衡,如果discriminator过于strong,则无法给generator任何有用的学习信号。因此,对于unlabeled image,本文每次将generator产生的,可以成功欺骗discriminator的分割图当作真实标签,用于监督学习。由此可以促使segmentation network(即generator)变强,且一定程度上阻碍discriminator的进步,不希望discriminator过于强大,破坏平衡。
具体而言,discriminator在s4GAN中用于在image-level判断一张分割图是真实标签(real label),还是segmentation network的输出(fake label),根据为真实标签的可能性输出一个0~1之间的概率值(若为真实标签,则输出1)
文章设置闸值,对于输出大于闸值的分割图,作为高质量的预测图,当作真实标签,用于监督学习,并计算交叉熵损失
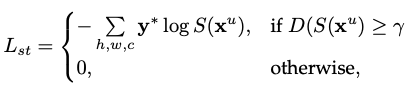
s4GAN总损失:
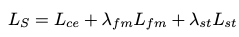
训练discriminator
discriminator的输入包含原图image和对应标签,训练discriminator,希望discriminator能给真实标签打高分,给fake label打低分。具体损失函数和传统的GAN相同。
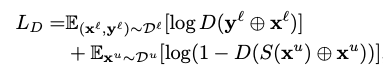
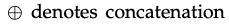 (channel wise)
(channel wise)
MLMT
该分支包含两个网络,分别为学生网络和老师网络,训练时,一张image经过微小的,不同的扰动之后分别输入学生网络和老师网络,学生网络和老师网络使用online ensemble的weight(老师网络是学生网络学习的目标,老师网络的权重在学生网络的基础上根据指数平均移动线移动,详见论文)。本文希望学生网络的输出和老师网络的输出尽可能一致,则对于所有image,使用均方误差来衡量两个网络输出的差异,对于labeled image,同时使用类交叉熵函数计算损失
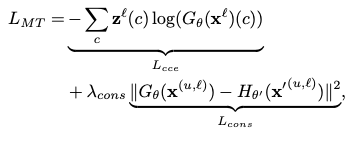
Network Fusion
简单的通过deactivate segmentation networks的输出中没有出现在input image中的图片来融合两个网络的结果。
对于一张image分割图的一个类别c的mask,尺寸为\(HxWx1\),(对于每一个像素?)如果学生网络的输出(soft label)小于设定的某个闸值,则令segmentation network的输出为0,否则segmentation network的输出不变。
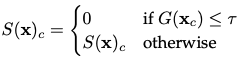
实验
数据集:
PASCAL VOC 2012 segmentation benchmark, the PASCAL-Context dataset, and the Cityscapes dataset.
网络具体结构:
segmentation network:
deeplab v2
discriminator:
4层卷积层,通道数分别为\({64,128,256,512}\),卷积核大小为4x4,每个卷积层后面都有一个negative slope of 0.2的Leaky-ReLU层和一个dropout概率为0.5的dropout层(该高概率的dropout layer对于GAN的稳定训练非常关键)。最后一个卷积层后面是一个全局平均池化层和全连接层,全局平均池化的输出用于Feature matching loss的计算
学生网络和老师网络:
ResNet101(在imagenet上预训练)
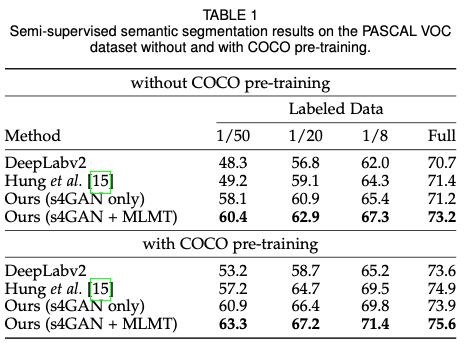
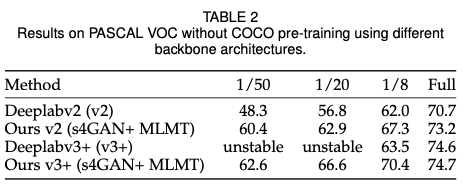
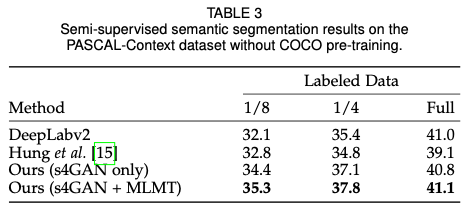
实验结果:
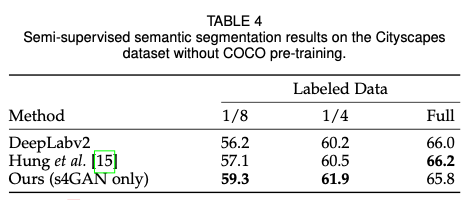

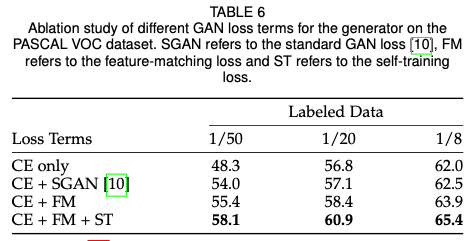
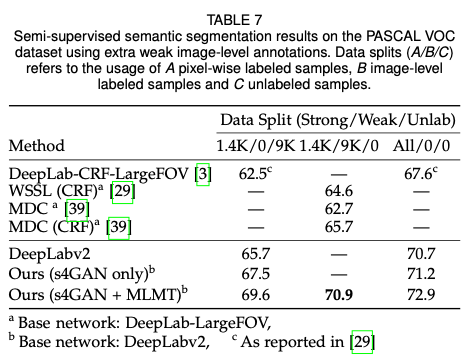
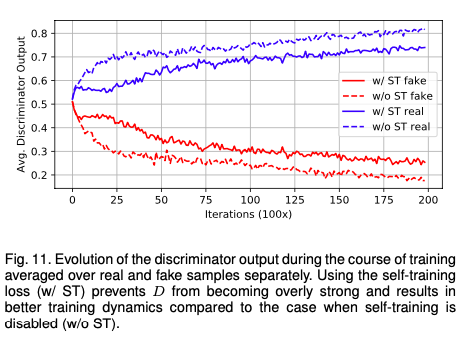
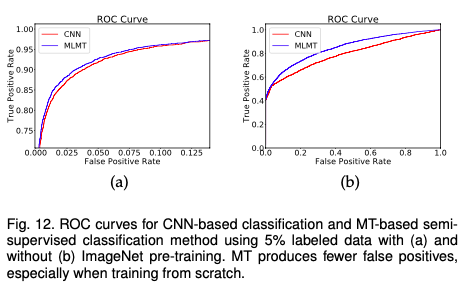
疑问:
- 网络融合的目的?
- self-train loss的设定(为阻止discriminator变强)?
[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency的更多相关文章
- [论文笔记][半监督语义分割]Universal Semi-Supervised Semantic Segmentation
论文原文原文地址 Motivations 传统的训练方式需要针对不同 domain 的数据分别设计模型,十分繁琐(deploy costs) 语义分割数据集标注十分昂贵,费时费力 Contributi ...
- [论文][半监督语义分割]Adversarial Learning for Semi-Supervised Semantic Segmentation
Adversarial Learning for Semi-Supervised Semantic Segmentation 论文原文 摘要 创新点:我们提出了一种使用对抗网络进行半监督语义分割的方法 ...
- OSVOS 半监督视频分割入门论文(中文翻译)
摘要: 本文解决了半监督视频目标分割的问题.给定第一帧的mask,将目标从视频背景中分离出来.本文提出OSVOS,基于FCN框架的,可以连续依次地将在IMAGENET上学到的信息转移到通用语义信息,实 ...
- 2018年发表论文阅读:Convolutional Simplex Projection Network for Weakly Supervised Semantic Segmentation
记笔记目的:刻意地.有意地整理其思路,综合对比,以求借鉴.他山之石,可以攻玉. <Convolutional Simplex Projection Network for Weakly Supe ...
- 论文学习:Fully Convolutional Networks for Semantic Segmentation
发表于2015年这篇<Fully Convolutional Networks for Semantic Segmentation>在图像语义分割领域举足轻重. 1 CNN 与 FCN 通 ...
- 论文笔记《Fully Convolutional Networks for Semantic Segmentation》
一.Abstract 提出了一种end-to-end的做semantic segmentation的方法,也就是FCN,是我个人觉得非常厉害的一个方法. 二.亮点 1.提出了全卷积网络的概念,将Ale ...
- 【Semantic segmentation Overview】一文概览主要语义分割网络(转)
文章来源:https://www.tinymind.cn/articles/410 本文来自 CSDN 网站,译者蓝三金 图像的语义分割是将输入图像中的每个像素分配一个语义类别,以得到像素化的密集分类 ...
- 利用NVIDIA-NGC中的MATLAB容器加速语义分割
利用NVIDIA-NGC中的MATLAB容器加速语义分割 Speeding Up Semantic Segmentation Using MATLAB Container from NVIDIA NG ...
- A Three-Stage Self-Training Framework for Semi-Supervised Semantic Segmentation
论文阅读笔记: A Three-Stage Self-Training Framework for Semi-Supervised Semantic Segmentation 基本信息 \1.标题:A ...
随机推荐
- 取代 Maven?这款项目构建工具性能提升 300%
在 GitHub 上闲逛的时候,发现了一个新的项目:maven-mvnd,持续霸占 GitHub trending 榜单好几天了. maven-mvnd,可以读作 Maven Daemon,译作 Ma ...
- sping练习,在Eclipse搭建的Spring开发环境中,使用工厂方式创建Bean对象,将创建的Bean对象输出到控制台。
相关 知识 >>> 相关 练习 >>> 实现要求: 在Eclipse搭建的Spring开发环境中,使用工厂方式创建Bean对象,将创建的Bean对象输出到控制台.要 ...
- 图像数据到网格数据-1——Marching Cubes算法的一种实现
概述 之前的博文已经完整的介绍了三维图像数据和三角形网格数据.在实际应用中,利用遥感硬件或者各种探测仪器,可以获得表征现实世界中物体的三维图像.比如利用CT机扫描人体得到人体断层扫描图像,就是一个表征 ...
- Flask + UnitTest(十五)
被测试视图 # coding:utf-8 from flask import Flask, request, jsonify app = Flask(__name__) @app.route(&quo ...
- 10个JS技巧
1.过滤唯一值 Set 对象是es6新引入的,配合扩展运算符[...]一起使用,我们可以用它来过滤数组的唯一值. const array = [1, 1, 2, 3, 5, 5, 1] const u ...
- Keepalived高可用、四层负载均衡
目录 Keepalived高可用 高可用简介 常用的工具 问题 名称解释 VRRP协议 部署keepalived 下载安装 Keepalived配置 保证nginx配置一样 解决keepalived的 ...
- 浅讲EF高级用法之自定义函数
介绍 好久没给大家更新文章了,前2个月因家庭原因回到青岛,比较忙所以没有什么时间给大家更新知识分享,这2个月在和同事一起做项目,发现了很多好意思的东西拿出来给大家讲一讲. 正文 大家先来下面这幅图,这 ...
- test_5 排序‘+’、‘-’
题目是:有一组"+"和"-"符号,要求将"+"排到左边,"-"排到右边,写出具体的实现方法. 方法一: l=['-', ...
- 机器学习&恶意代码静态检测
目录 分析工具 方法概述 二进制灰度图 字节(熵)直方图 字符串信息 ELF结构信息 源码分析与OPcode FCG references: 分析工具 readelf elfparser ninja ...
- postman设置token等关联参数
登陆时登录成功后服务器会返回一个token,这个token作为第二步骤的入参:第二个步骤请求成功后服务器会返回一个新token,然后这个token作为第三步骤的入参!如此一来的话,要用postman做 ...