pytest(8)-参数化
前言
什么是参数化,通俗点理解就是,定义一个测试类或测试函数,可以传入不同测试用例对应的参数,从而执行多个测试用例。
例如对登录接口进行测试,假设有3条用例:正确账号正确密码登录、正确账号错误密码登录、错误账号正确密码登录,那么我们只需要定义一个登陆测试函数test_login(),然后使用这3条用例对应的参数去调用test_login()即可。
在unittest中可以使用ddt进行参数化,而pytest中也提供非常方便的参数化方式,即使用装饰器@pytest.mark.parametrize()。
一般写为pytest.mark.parametrize("argnames", argvalues),其中:
argnames为参数名称,可以是单个或多个,多个写法为"argname1, argname2, ......"argvalues为参数值,类型必须为list(单个参数时可以为元组,多个参数时必须为list,所以最好统一)
当然pytest.mark.parametrize()不止这两个参数,感兴趣的可以去查看源代码,后面我们还会讲到其中的参数ids。
示例中所请求的登陆接口信息为:
- 接口url:http://127.0.0.1:5000/login
- 请求方式:post
- 请求参数:{"username": "xxx", "password": "xxxxxx"}
- 响应信息:{"code": 1000, "msg": "登录成功", "token": "xxxxxx"}
单个参数
只需要传入一个参数时,示例如下:
# 待测试函数
def sum(a):
return a+1
# 单个参数
data = [1, 2, 3, 4]
@pytest.mark.parametrize("item", data)
def test_add(item):
actual = sum(item)
print("\n{}".format(actual))
# assert actual == 3
if __name__ == '__main__':
pytest.main()
注意,@pytest.mark.parametrize()中的第一个参数,必须以字符串的形式来标识测试函数的入参,如上述示例中,定义的测试函数test_login()中传入的参数名为item,那么@pytest.mark.parametrize()的第一个参数则为"item"。
运行结果如下:
rootdir: E:\blog\python接口自动化\apiAutoTest, configfile: pytest.ini
plugins: html-2.1.1, metadata-1.10.0, ordering-0.6, rerunfailures-9.1.1
collecting ... collected 4 items
test_case_2.py::test_add[1] PASSED [ 25%]
2
test_case_2.py::test_add[2] PASSED [ 50%]
3
test_case_2.py::test_add[3] PASSED [ 75%]
4
test_case_2.py::test_add[4] PASSED [100%]
5
============================== 4 passed in 0.02s ==============================
从结果我们可以看到,测试函数分别传入了data中的参数,总共执行了5次。
多个参数
测试用例需传入多个参数时,@pytest.mark.parametrize()的第一个参数同样是字符串, 对应用例的多个参数用逗号分隔。
示例如下:
import pytest
import requests
import json
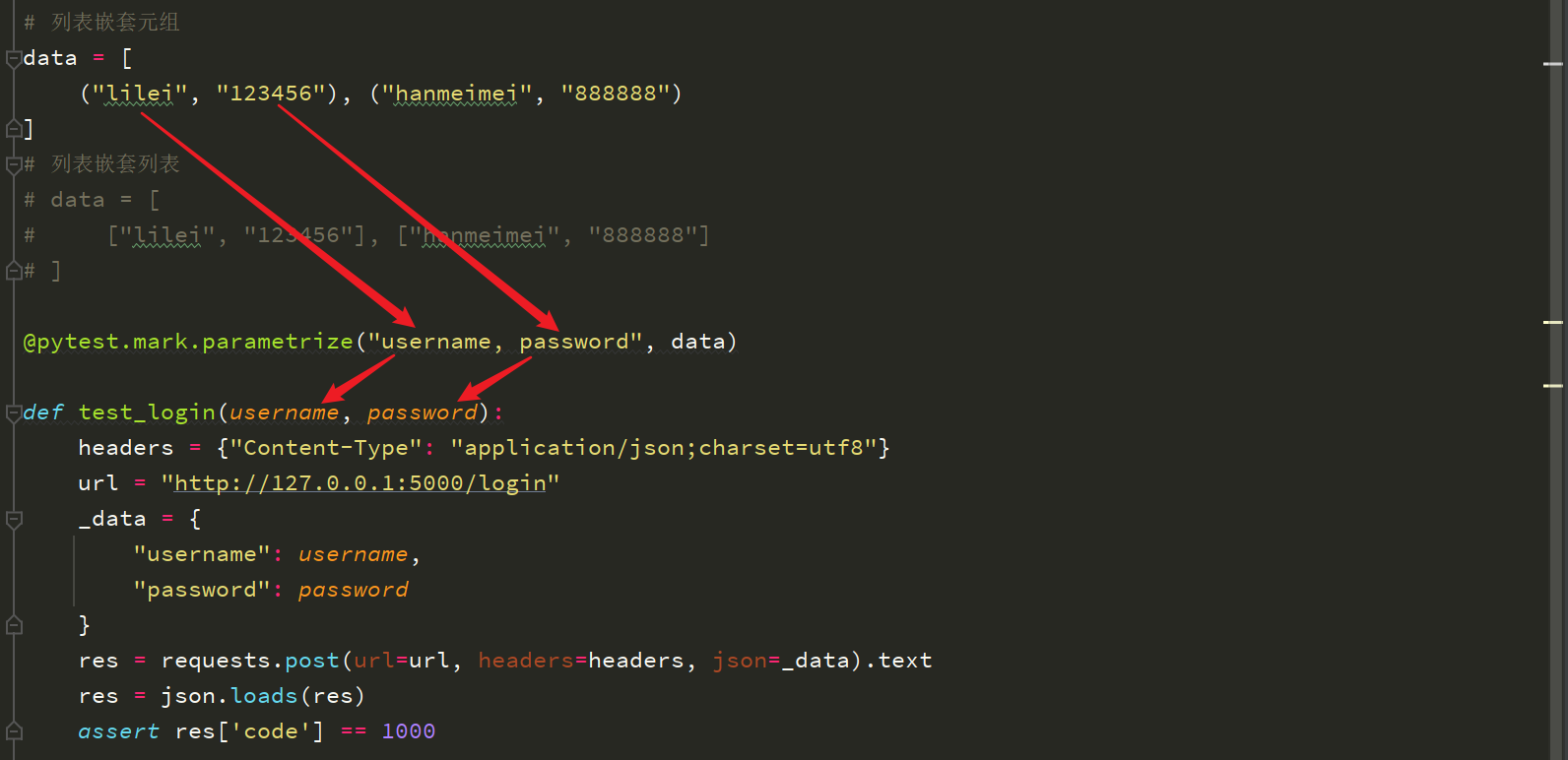
# 列表嵌套元组
data = [("lilei", "123456"), ("hanmeimei", "888888")]
# 列表嵌套列表
# data = [["lilei", "123456"], ["hanmeimei", "888888"]]
@pytest.mark.parametrize("username, password", data)
def test_login(username, password):
headers = {"Content-Type": "application/json;charset=utf8"}
url = "http://127.0.0.1:5000/login"
_data = {
"username": username,
"password": password
}
res = requests.post(url=url, headers=headers, json=_data).text
res = json.loads(res)
assert res['code'] == 1000
if __name__ == '__main__':
pytest.main()
这里需要注意:
- 代码中
data的格式,可以是列表嵌套列表,也可以是列表嵌套元组,列表中的每个列表或元组代表一组独立的请求参数。 "username, password"不能写成 "username", "password"。
运行结果如下:
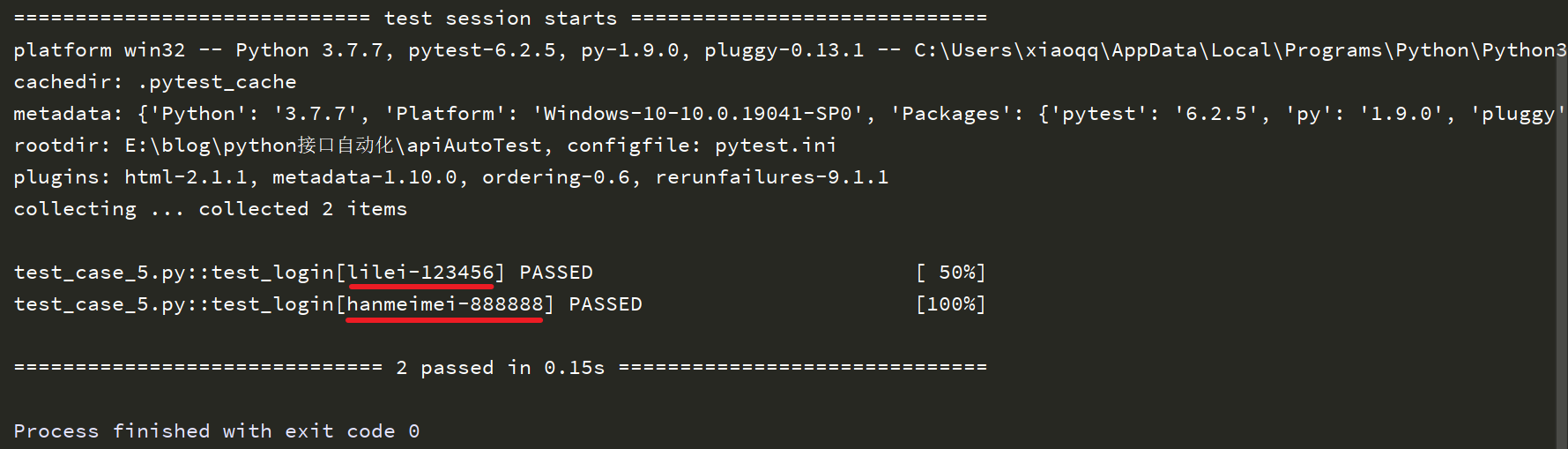
从结果中我们还可以看到每次执行传入的参数,如下划线所示部分。
这里所举示例是2个参数,传入3个或更多参数时,写法也同样如此,一定要注意它们之间一一对应的关系,如下图:
对测试类参数化
上面所举示例都是对测试函数进行参数化,那么对测试类怎么进行参数化呢?
其实,对测试类的参数化,就是对测试类中的测试方法进行参数化。@pytest.mark.parametrize()中标识的参数个数,必须与类中的测试方法的参数一致。示例如下:
# 将登陆接口请求单独进行了封装,仅仅只是为了方便下面的示例
def login(username, password):
headers = {"Content-Type": "application/json;charset=utf8"}
url = "http://127.0.0.1:5000/login"
_data = {
"username": username,
"password": password
}
res = requests.post(url=url, headers=headers, json=_data).text
res = json.loads(res)
return res
# 测试类参数化
data = [
("lilei", "123456"), ("hanmeimei", "888888")
]
@pytest.mark.parametrize("username, password", data)
class TestLogin:
def test_login_01(self, username, password):
res = login(username, password)
assert res['code'] == 1000
def test_login_02(self, username, password):
res = login(username, password)
assert res['msg'] == "登录成功!"
if __name__ == '__main__':
pytest.main(["-s"])
运行结果如下:
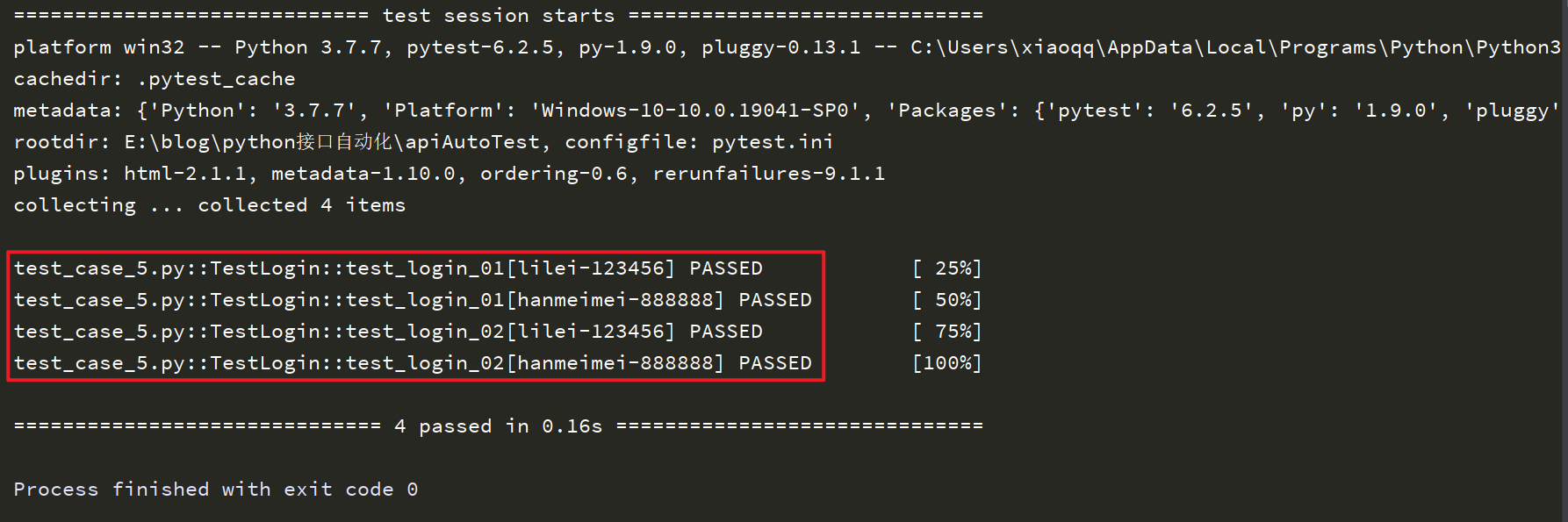
从结果中可以看出来,总共执行了4次,测试类中的每个测试方法都执行了2次,即每个测试方法都将data中的每一组参数都执行了一次。
注意,这里还是要强调参数对应的关系,即@pytest.mark.parametrize()中的第一个参数,需要与测试类下面的测试方法的参数一一对应。
参数组合
在编写测试用例的过程中,有时候需要将参数组合进行接口请求,如示例的登录接口中username有 lilei、hanmeimei,password有 123456、888888,进行组合的话有下列四种情况:
{"username": "lilei", "password": "123456"}
{"username": "lilei", "password": "888888"}
{"username": "hanmeimei", "password": "123456"}
{"username": "hanmeimei", "password": "888888"}
在@pytest.mark.parametrize()也提供了这样的参数组合功能,编写格式示例如下:
import pytest
import requests
import json
username = ["lilei", "hanmeimei"]
password = ["123456", "888888"]
@pytest.mark.parametrize("password", password)
@pytest.mark.parametrize("username", username)
def test_login(username, password):
headers = {"Content-Type": "application/json;charset=utf8"}
url = "http://127.0.0.1:5000/login"
_data = {
"username": username,
"password": password
}
res = requests.post(url=url, headers=headers, json=_data).text
res = json.loads(res)
assert res['code'] == 1000
if __name__ == '__main__':
pytest.main()
运行结果如下:
rootdir: E:\blog\python接口自动化\apiAutoTest, configfile: pytest.ini
plugins: html-2.1.1, metadata-1.10.0, ordering-0.6, rerunfailures-9.1.1
collecting ... collected 4 items
test_case_5.py::test_login[lilei-123456] PASSED [ 25%]
test_case_5.py::test_login[lilei-888888] FAILED [ 50%]
test_case_5.py::test_login[hanmeimei-123456] FAILED [ 75%]
test_case_5.py::test_login[hanmeimei-888888] PASSED [100%]
=========================== short test summary info ===========================
FAILED test_case_5.py::test_login[lilei-888888] - assert 1001 == 1000
FAILED test_case_5.py::test_login[hanmeimei-123456] - assert 1001 == 1000
========================= 2 failed, 2 passed in 0.18s =========================
从结果可以看出来,2个username、2个password 有4中组合方式,总执行了4次。如果是3个username、2个password,那么就有6中参数组合方式,依此类推。
注意,以上这些示例中的测试用例仅仅只是用于举例,实际项目中的登录接口测试脚本与测试数据会不一样。
增加测试结果可读性
从示例的运行结果中我们可以看到,为了区分参数化的运行结果,在结果中都会显示由参数组合而成的执行用例名称,很方便就能看出来执行了哪些参数组合的用例,如下示例:
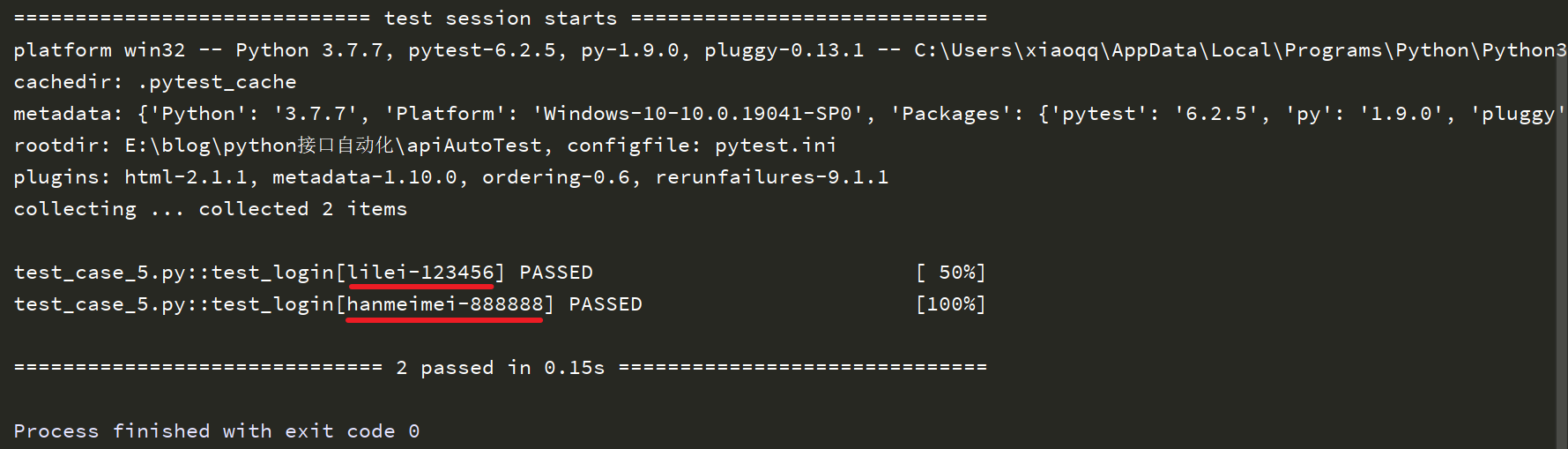
但这只是简单的展示,如果参数多且复杂的话,仅仅这样展示是不够清晰的,需要添加一些说明才能一目了然。
因此,在@pytest.mark.parametrize()中有两种方式来自定义上图中划线部分的显示结果,即使用@pytest.mark.parametrize()提供的参数 ids 自定义,或者使用pytest.param()中的参数id自定义。
ids(推荐)
ids使用方法示例如下:
import pytest
import requests
import json
data = [("lilei", "123456"), ("hanmeimei", "888888")]
ids = ["username:{}-password:{}".format(username, password) for username, password in data]
@pytest.mark.parametrize("username, password", data, ids=ids)
def test_login(username, password):
headers = {"Content-Type": "application/json;charset=utf8"}
url = "http://127.0.0.1:5000/login"
_data = {
"username": username,
"password": password
}
res = requests.post(url=url, headers=headers, json=_data).text
res = json.loads(res)
assert res['code'] == 1000
if __name__ == '__main__':
pytest.main()
从编写方式可以看出来,ids就是一个list,且它的长度与参数组合的分组数量一致。
运行结果如下:
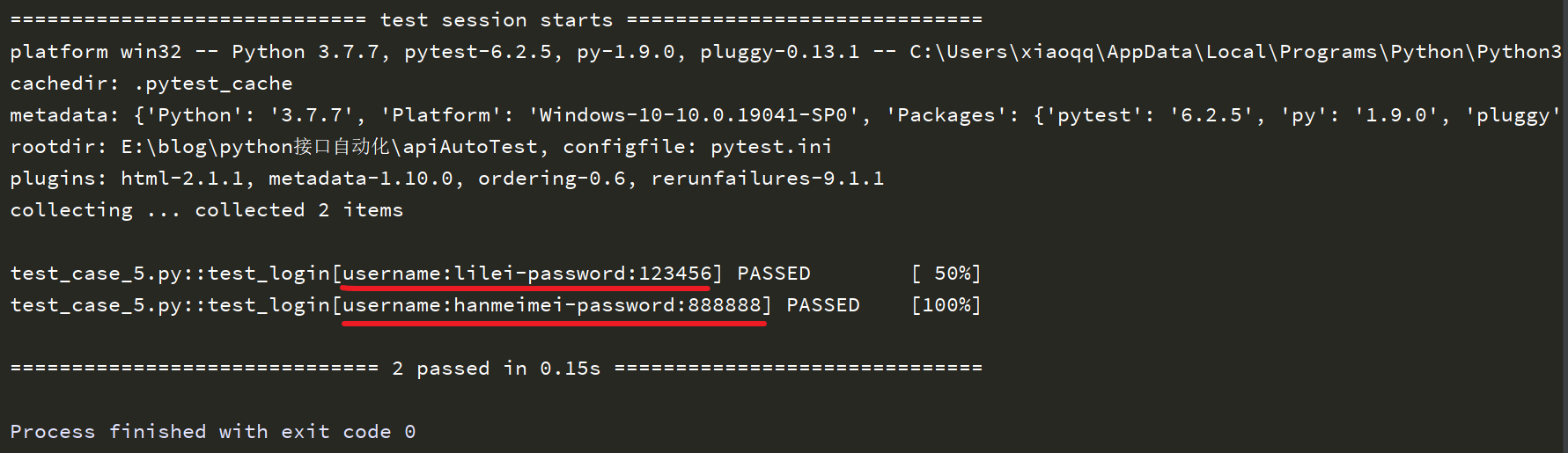
比较上面个执行结果,我们能看出ids自定义执行结果与默认执行结果展示的区别。使用过程中,需要根据实际情况来自定义。
id
使用方式示例如下:
import pytest
import requests
import json
data = [
pytest.param("lilei", "123456", id="correct username and correct password"),
pytest.param("lilei", "111111", id="correct user name and wrong password")
]
@pytest.mark.parametrize("username, password", data)
def test_login(username, password):
headers = {"Content-Type": "application/json;charset=utf8"}
url = "http://127.0.0.1:5000/login"
_data = {
"username": username,
"password": password
}
res = requests.post(url=url, headers=headers, json=_data).text
res = json.loads(res)
assert res['code'] == 1000
if __name__ == '__main__':
pytest.main()
运行结果如下:
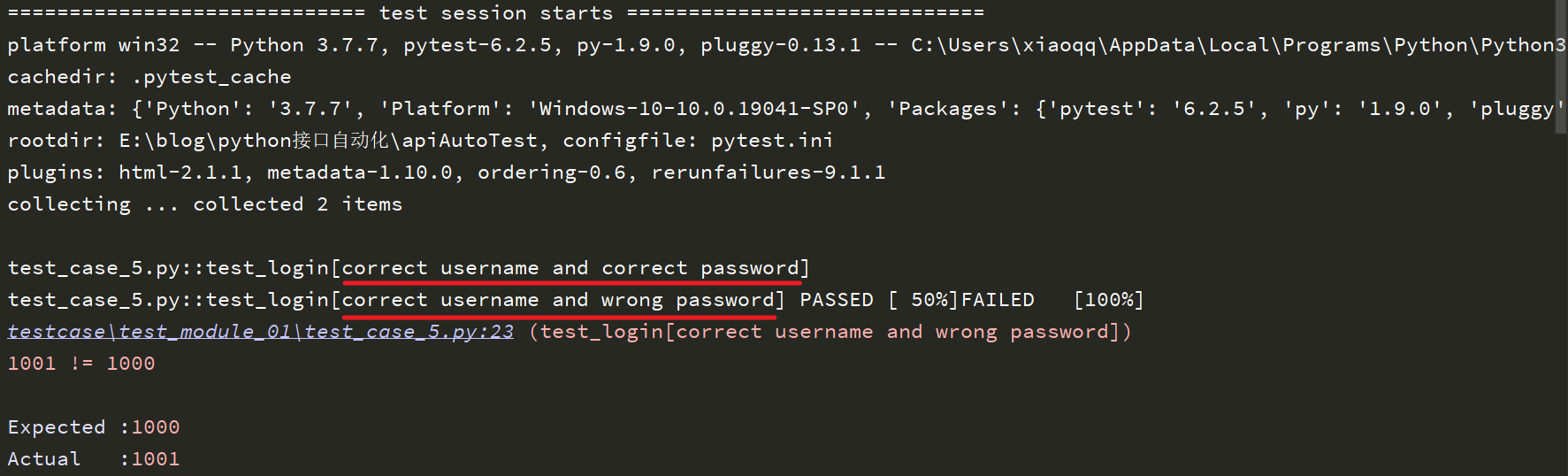
从个人实际使用体验来说,感觉id相对于ids,自定义的扩展性相当较小,而且我尝试着在id中使用中文进行定义,控制台显示的不是中文,而是编码后的结果。所以推荐使用ids。当然也可能是它的作用我没理解透彻。
总结
以上功能基本能覆盖我们平常自动化测试项目中的绝大部分场景。
当然,pytest.mark.parametrize()进行参数化的过程中,还有一些别的功能,如结合pytest.param()标记用例失败或跳过,感兴趣的可以自行查找使用方式,这里不做过多说明。
pytest(8)-参数化的更多相关文章
- pytest 8 参数化parametrize
pytest.mark.parametrize装饰器可以实现用例参数化 1.以下是一个实现检查一定的输入和期望输出测试功能的典型例子 import pytest @pytest.mark.parame ...
- pytest.5.参数化的Fixture
From: http://www.testclass.net/pytest/parametrize_fixture/ 背景 继续上一节的测试需求,在上一节里,任何1条测试数据导致断言不通过后测试用例就 ...
- pytest的参数化
参数化有两种方式: 1. @pytest.mark.parametrize 2.利用conftest.py里的 pytest_generate_tests 1中的例子如下: @pytest.mark. ...
- pytest的参数化测试
感觉在单元测试当中可能有用, 但在django这种框架中,用途另一说. import pytest import tasks from tasks import Task def test_add_1 ...
- pytest封神之路第五步 参数化进阶
用过unittest的朋友,肯定知道可以借助DDT实现参数化.用过JMeter的朋友,肯定知道JMeter自带了4种参数化方式(见参考资料).pytest同样支持参数化,而且很简单很实用. 语法 在& ...
- pytest和unittest中参数化如何做
参数化应用场景,一个场景的用例会用到多条数据来进行验证,比如登录功能会用到正确的用户名.密码登录,错误的用户名.正确的密码,正确的用户名.错误的密码等等来进行测试,这时就可以用到框架中的参数化,来便捷 ...
- 『德不孤』Pytest框架 — 15、Pytest参数化
目录 1.Pytest参数化说明 2.Pytest参数化方式 3.parametrize装饰器参数说明 4.Pytest参数化(单个参数) 5.Pytest参数化(多个参数) 6.ids参数说明 1. ...
- pytest学习笔记(三)
接着上一篇的内容,这里主要讲下参数化,pytest很好的支持了测试函数中变量的参数化 一.pytest的参数化 1.通过命令行来实现参数化 文档中给了一个简单的例子, test_compute.py ...
- 【Python】【自动化测试】【pytest】
https://docs.pytest.org/en/latest/getting-started.html#create-your-first-test http://www.testclass.n ...
随机推荐
- 关于 this.$route.meta.operations.includes('delete') 取不到值的问题
原因是:src/mock/api/sys.login.js中定义的路径 要与src/router/modules/下定义的路由要一致 作用this.$route.matched可以查看匹配信息 来自为 ...
- git -remote: Support for password authentication was removed on August 13, 2021
克隆代码时,报错: Support for password authentication was removed on August 13, 2021. Please use a personal ...
- mysql 的 if 和 SQL server 的 iif
在sql语句中,mysql 使用 if 而SQL server 使用iif 如 mysql : SELECT IF(1<2,'yes ','no'); sql server: SELECT II ...
- c# - 关于位移符号 >> 和 << 的使用
1.前言 这是对二进制数据进行位移的方法 2.操作 using System; namespace ConsoleApp1.toValue { public class test1 { public ...
- systemd学习及使用
什么是systemd? (译)systemd是linux系统的一组基础构件块.它提供了一个系统和服务的管理,它以PID 1 的形式运行并启动系统的其余部分.systemd 使用积极的并行化功能,使用s ...
- SYCOJ1793
题目-统计单词前缀数 (shiyancang.cn) 1 #include<bits/stdc++.h> 2 using namespace std; 3 map<string,in ...
- 蓝桥杯ALGO-1003
问题描述 JiaoShou在爱琳大陆的旅行完毕,即将回家,为了纪念这次旅行,他决定带回一些礼物给好朋友. 在走出了怪物森林以后,JiaoShou看到了排成一排的N个石子. 这些石子很漂亮,JiaoSh ...
- 小程序onShareAppMessage有点迷
小程序遇到的问题 起因 目前项目需求是分享时携带参数去进行裂变,但是在查看微信文档后发现有onShareAppMessage这个页面处理事件可以使用.事件可以使用return一个Object,用于自定 ...
- python pip无法安装到2.7
问题 pip默认指向python3.6,没有pip2,pip2.7 解决办法 加上应用路径 加上系统环境变量 参考 https://www.cnblogs.com/fanyuchen/p/712768 ...
- 针对vue中请求数据对象新添加的属性不能响应式的解决方法
1.需要给对象添加属性时,不能采用传统的obj.属性=值,obj[属性]=值 来添加属性,在vue页面时需要这样使用 this.$set(obj,"propertyName",&q ...