JStorm:概念与编程模型
1、集群架构
JStorm从设计的角度,就是一个典型的调度系统,简单集群的架构如下图所示,其中Nimbus可增加一个备节点,多个Supervisor节点组成任务执行集群。
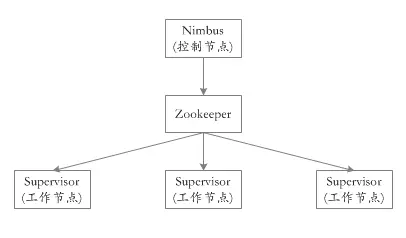
1.1、Nimbus
Nimbus是作为整个集群的调度器角色,负责分发topology代码、分配任务,监控集群运行状态等,其主要通过ZK与supervisor交互。可以和Supervisor运行在同一物理机上,JStorm中Nimbus可采用主从备份,支持热切。
1.2、Supervisor
Supervisor 是集群中任务的执行者,负责运行具体任务以及关闭任务。其从ZK中监听nimbus的指令,然后接收分发代码和任务并执行、监控反馈任务执行情况。
1.3 、Zookeeper
ZK是整个系统中的协调者,Nimbus的任务调度通过ZK下发至Supervisor来执行。
2、Topology编程模型
Topology是一个可以在JStorm中运行的任务的抽象表达,在JStorm的topology中,有两种组件:spout和bolt。下面是一张比较经典的Topology结构图。每一个topology,既可以有多个spout,代表同时从多个数据源接收消息,也可以多个bolt,来执行不同的业务逻辑。一个topology会一直运行直到你手动kill掉,JStorm自动重新分配执行失败的任务。
在JStorm中有对于流stream的抽象,流是一个不间断的无界的连续tuple,注意JStorm在建模事件流时,把流中的事件抽象为tuple即元组。
我们可以认为spout就是一个一个的水龙头,并且每个水龙头里流出的水是不同的tuple,我们想拿到哪种水tuple就拧开哪个水龙头,然后使用管道将水龙头的水tuple导向到一个水处理器(bolt),水处理器bolt处理后再使用管道导向另一个处理器或者存入容器中。
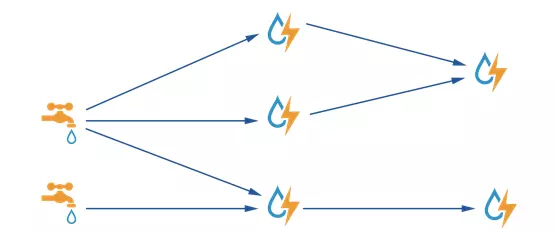
JStorm将上图抽象为Topology即拓扑,拓扑结构是有向无环的,拓扑是Jstorm中最高层次的一个抽象概念,它可以被提交到Jstorm集群执行,一个拓扑就是一个数据流转换图,图中每个节点是一个spout或者bolt,图中的边表示bolt订阅了哪些流,当spout或者bolt发送元组到流时,它就发送元组到每个订阅了该流的bolt。
2.1、spout
JStorm认为每个stream都有一个stream源,也就是原始元组的源头,所以它将这个源头抽象为spout,spout可能是连接消息中间件(如MetaQ, Kafka, TBNotify等),并不断发出消息,也可能是从某个队列中不断读取队列元素并装配为tuple发射。
JStorm框架对spout组件定义了一个主要方法:nextTuple,顾名思义,就是获取下一条消息。执行时,可以理解成JStorm框架会不停地调这个接口,以从数据源拉取数据并往bolt发送数据。
Tuple是一次消息传递的基本单元,tuple里的每个字段一个名字,并且不同tuple的对应字段的类型必须一样。tuple的字段类型可以是: integer, long, short, byte, string, double, float, boolean和byte array。还可以自定义类型,只要实现对应的序列化器。
JStorm中与spout相关的接口主要是ISpout和IRichSpout、IBatchSpout,后两接口实现了对ISpout接口的上层封装。
ISpout接口主要方法:
open:在worker中初始化该ISpout时调用,一般用来设置一些属性:比如从spring容器中获取对应的Bean。
close:和open相对应(在要关闭的时候调用)。
activate:从非活动状态变为活动状态时调用。
deactivate:和activate相对应(从活动状态变为非活动状态时调用)。
nextTuple:JStorm希望在每次调用该方法的时候,它会通过collector.emit发射一个tuple。
ack:jstorm发现msgId对应的tuple被成功地完整消费会调用该方法。
fail:和ack相对应(jstorm发现某个tuple在某个环节失败了)。和ack一起保证tuple一定被处理。
2.2、bolt
JStorm将tuple的中间处理过程抽象为Bolt,bolt可以消费任意数量的输入流,只要将流方向导向该bolt,同时它也可以发送新的流给其他bolt使用,这样一来,只要打开特定的spout(管口)再将spout中流出的tuple导向特定的bolt,然后bolt对导入的流做处理后再导向其他bolt或者目的地。
bolt代表处理逻辑,bolt收到消息之后,对消息做处理(即执行用户的业务逻辑),处理完以后,既可以将处理后的消息继续发送到下游的bolt,这样会形成一个处理流水线(不过更复杂的情况应该是个有向图);也可以直接结束。
bolt组件主要方法:execute,这个接口就是用户用来处理业务逻辑的地方。
通常一个流水线的最后一个bolt,会做一些数据的存储工作,比如将实时计算出来的数据写入DB、HBase等,以供前台业务进行查询和展现。Bolts可以发射多条消息流, 使用OutputFieldsDeclarer.declareStream定义stream,使用OutputCollector.emit来选择要发射的stream。
在保证不丢消息的场景中,在bolts必须要为它处理的每一个tuple调用OutputCollector的ack方法,以通知JStorm这个tuple被处理完成了,从而通知这个tuple的发射者spouts。 一般的流程是: bolts处理一个输入tuple, 发射0个或者多个tuple, 然后调用ack通知JStorm自己已经处理过这个tuple了。JStorm提供了一个IBasicBolt会自动调用ack。
JStorm中与Bolt相关的接口主要是IBolt,IRichBolt,IBasicBolt和IBatchBolt,后面接口实现了对IBolt接口的上层封装。
IBolt接口的主要方法:
prepare:在worker中初始化该IBolt时调用,一般用来设置一些属性:比如从spring容器中获取对应的Bean。
cleanup:和prepare相对应(在显示关闭topology的时候调用)
execute:处理jstorm发送过来的tuple。
2.3、Tuple
JStorm将流中数据抽象为tuple,一个tuple就是一个值列表value list,list中的每个value都有一个name,tuple可以由任意类型组合而成,因为storm是分布式的,所以它需要知道在task间如何序列化和反序列化数据的。storm使用Kryo进行序列化,Kryo是java开发中一个快速灵活序列器。默认情况下,storm可以序列化基础类型,比如字符串,字节,数组,ArrayList, HashMap, HashSet和 Clojure 集合类型,如果需要使用其他类型,需要自定义序列器。拓扑的每个节点都要说明它所发射出的元组的字段的name,其他节点只需要订阅该name就可以接收处理。
在spout和Bolt组件中,使用declareOutputFields方法定义发射出的tuple的字段名。
3、小结
本文主要讲述了JStorm中集群的架构以及Topology编程模型方面的概念知识。
https://www.jianshu.com/p/36394f897d36
https://yq.aliyun.com/articles/709401
JStorm:概念与编程模型的更多相关文章
- spark概念、编程模型和模块概述
http://blog.csdn.net/pipisorry/article/details/50931274 spark基本概念 Spark一种与 Hadoop 相似的通用的集群计算框架,通过将大量 ...
- 云巴:基于MQTT协议的实时通信编程模型
概要 有人常问,云巴实时通信系统到底提供了一种怎样的服务,与其他提供推送或 IM 服务的厂商有何本质区别.其实,从技术角度分析,云巴与其它同类厂商都是面向开发者的通信服务,宏观的编程模型都是大同小异, ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Linux IO模型和网络编程模型
术语概念描述: IO有内存IO.网络IO和磁盘IO三种,通常我们说的IO指的是后两者. 阻塞和非阻塞,是函数/方法的实现方式,即在数据就绪之前是立刻返回还是等待. 以文件IO为例,一个IO读过程是文件 ...
- Spark中文指南(入门篇)-Spark编程模型(一)
前言 本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程 本章知识点概括 Apache Spark简介 Spark的四种运行模式 Spark基于Standlone的运行流程 Spark ...
- ASP.NET编程模型之ASP.NET页面生命周期图解
ASP.NET编程模型中ASP.NET页面生命周期是指什么呢?它包括什么呢?ASP.NET编程模型之ASP.NET页面生命周期具体的过程有哪些呢?下面就开始我们的讲解吧: ASP.NET 页运行时,此 ...
- 并行计算基础&编程模型与工具
在当前计算机应用中,对快速并行计算的需求是广泛的,归纳起来,主要有三种类型的应用需求: 计算密集(Computer-Intensive)型应用,如大型科学project计算与数值模拟: 数据密集(Da ...
- .Net插件编程模型:MEF和MAF[转载]
.Net插件编程模型:MEF和MAF MEF和MAF都是C#下的插件编程框架,我们通过它们只需简单的配置下源代码就能轻松的实现插件编程概念,设计出可扩展的程序.这真是件美妙的事情! 今天抽了一点时间, ...
- 老李分享: 并行计算基础&编程模型与工具 1
老李分享: 并行计算基础&编程模型与工具 在当前计算机应用中,对高速并行计算的需求是广泛的,归纳起来,主要有三种类型的应用需求: 计算密集(Computer-Intensive)型应用,如 ...
随机推荐
- 010_Mybatis简介
目录 Mybatis简介 什么是 MyBatis? 如何获得Mybatis 持久化 持久层 为什么需要Mybatis 第一个Mybatis程序 搭建环境 建库建表 新建父工程 新建普通maven项目 ...
- hugegraph 源码解读 —— 索引与查询优化分析
为什么要有索引 gremlin 其实是一个逐级过滤的运行机制,比如下面的一个简单的gremlin查询语句: g.V().hasLabel("label").has("pr ...
- XCTF GAME
首先这题有两种解法,一种是使用ida查看伪代码直接写exp跑出flag,另外一种是调试,因为最近在学调试,刚好用于实战上了. 一.查壳 二.32位文件拖入od动态调试 先找到game的主要函数,插件中 ...
- XCTF re-100
一.无壳并拉入ida64静态调试(注释说的很明白了) 二.confuseKey是个关键函数,进入看看 发现就是将我们所输入的字符串分割,并把顺序调换了,调回来就是我们的flag. 三.flag: 提交 ...
- bat自动创建快捷方式并更换图标
1 :: 此脚本主要的作用创建1.自动创建快捷方式:2.自动更换快捷方式图标 2 @echo off 3 >nul 2>&1 "%SYSTEMROOT%\system32 ...
- Java中为什么notify()可能导致死锁,而notifyAll()则不会(针对生产者-消费者模式)
1.先说两个概念:锁池 和 等待池 锁池:假设线程A已经拥有了某个对象(注意:不是类)的锁,而其它的线程想要调用这个对象的某个synchronized方法(或者synchronized块),由于这些线 ...
- C++泛型编程-举例
就是C++里面说的函数模板和类模板,我们以前写C语言的时候,不同的类型参数,可能要写不同的函数. C++的模板出现之后,就可以实现函数模板,函数模板可以接纳不同的类型,然后这些类型都可以调用同一个函数 ...
- Python3.7 lxml引入etree
用xml代替lxml,Python3.7中已经没有etree这个模块了 import xml.etree.ElementTree as etree from lxml import etree 这种方 ...
- PAT乙级:1084 外观数列 (20分)
PAT乙级:1084 外观数列 (20分) 题干 外观数列是指具有以下特点的整数序列: d, d1, d111, d113, d11231, d112213111, ... 它从不等于 1 的数字 d ...
- POJ1456 Supermarket 题解
思维题. 关键在于如何想到用堆来维护贪心的策略. 首先肯定是卖出的利润越大的越好,但有可能当前这天选定了利润最大的很久才过期而利润第二大的第二天就过期,这时的策略就不优了. 所以我们必须动态改变策略, ...