【ShardingSphere技术专题】「ShardingJDBC」SpringBoot之整合ShardingJDBC实现分库分表(JavaConfig方式)
前提介绍
ShardingSphere介绍
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
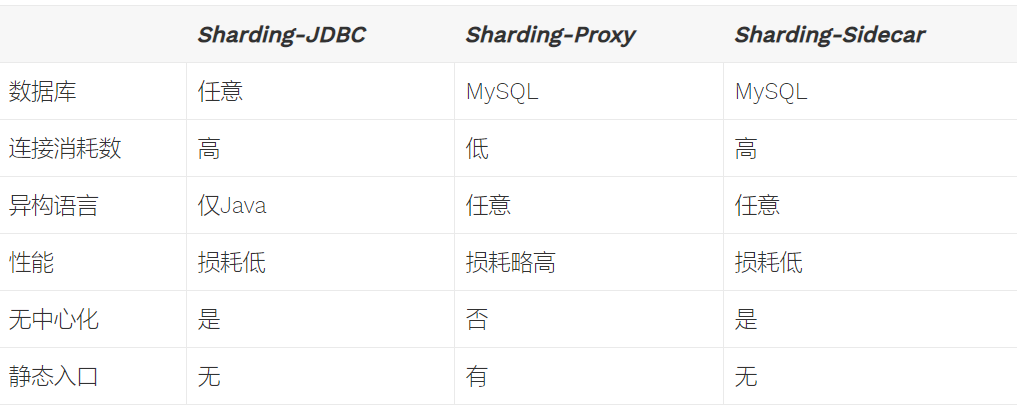
shardingJDBC使用的范围
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
详细一点的介绍直接看官网:https://shardingsphere.apache.org/document/current/cn/overview/
SQL语句相关
逻辑表:水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为2张表,分别是t_order_0到t_order_1,他们的逻辑表名为t_order。
真实表:在分片的数据库中真实存在的物理表。例:示例中的t_order_0到t_order_1
数据节点:数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0;ds_0.t_order_1;
绑定表:指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
广播表:指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景。
数据分片相关
- 分片键:用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。
SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
- 分片算法:通过分片算法将数据分片,支持通过=、>=、<=、>、<、BETWEEN和IN分片,分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法
- 精确分片算法:对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
- 范围分片算法:对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合StandardShardingStrategy使用。
- 复合分片算法:对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
- Hint分片算法:对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
分片策略:包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也就是分片策略。
目前提供5种分片策略
标准分片策略:对应StandardShardingStrategy,提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。
- StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
- PreciseShardingAlgorithm是必选的,用于=和IN的分片。
- RangeShardingAlgorithm是可选的,用于BETWEEN AND, >, <, >=, <=分片,不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
- StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。
复合分片策略:对应ComplexShardingStrategy。提供对SQL语句中的=, >, <, >=, <=, IN和BETWEEN AND的分片操作支持。
- ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装。
- 而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。
行表达式分片策略:对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL语句中的=和IN的分片操作支持,只支持单分片键。
对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如:
t_user_$->{u_id % 8}表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0到t_user_7。Hint分片策略:对应HintShardingStrategy。通过Hint指定分片值而非从SQL中提取分片值的方式进行分片的策略。
不分片策略:对应NoneShardingStrategy。
配置相关
分片规则:分片规则配置的总入口。包含数据源配置、表配置、绑定表配置以及读写分离配置等。
- 数据源配置:真实数据源列表。
- 表配置:逻辑表名称、数据节点与分表规则的配置
- 数据节点配置:用于配置逻辑表与真实表的映射关系。
- 分片策略配置:
- 数据源分片策略:对应于DatabaseShardingStrategy。用于配置数据被分配的目标数据源。
- 表分片策略:对应于TableShardingStrategy。用于配置数据被分配的目标表,该目标表存在与该数据的目标数据源内。故表分片策略是依赖与数据源分片策略的结果的。
- 自增主键生成策略:通过在客户端生成自增主键替换以数据库原生自增主键的方式,做到分布式主键无重复。(雪花算法)
开发步骤
开发整合方式
方式一:基于配置文件集成,方便简单但是不够灵活
<!--主要有以下依赖,分库分表策略直接在application.properties做相关配置即可-->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0.M1</version>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>3.1.0.M1</version>
</dependency>
方式二:这里我们主要基于java config的方式来集成到springboot中,更适合学习和理解
//相关依赖
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>3.1.0</version>
</dependency>
<!--<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-transaction-2pc-xa</artifactId>
<version>3.1.0</version>
</dependency>-->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-orchestration</artifactId>
<version>3.1.0</version>
</dependency>
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-orchestration-reg-zookeeper-curator</artifactId>
<version>3.1.0</version>
</dependency>
定义相关配置类(DataSourceConfig => MybatisConfig => TransactionConfig)
ShardingSphereDataSourceConfig
import javax.sql.DataSource;
import java.lang.management.ManagementFactory;
import java.sql.SQLException;
import java.util.*;
/**
* @Author zhangboqing
* @Date 2020/4/25
*/
@Configuration
@Slf4j
public class ShardingSphereDataSourceConfig {
@Bean("shardingDataSource")
DataSource getShardingDataSource() throws SQLException {
//初始化相关的分片规则配置信息控制机制
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
// 设置相关的数据源
shardingRuleConfig.setDefaultDataSourceName("ds0");
// 设置相关的Order表的相关的规则信息配置机制
shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration());
// 设置相关的OrderItem表的相关的规则信息配置机制
shardingRuleConfig.getTableRuleConfigs().add(getOrderItemTableRuleConfiguration());
// 配置绑定表关系
shardingRuleConfig.getBindingTableGroups().add("t_order, t_order_item");
// 广播表操作机制
shardingRuleConfig.getBroadcastTables().add("t_config");
// 设置相关的分片机制策略(数据源分片策略机制控制)
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "ds${user_id % 2}"));
// 设置相关的分片策略机制,子啊inline模式下(包含了两种模式)
shardingRuleConfig.setDefaultTableShardingStrategyConfig(getShardingStrategyConfiguration());
// ShardingPropertiesConstant相关配置选项
Properties properties = new Properties();
//是否打印SQL解析和改写日志
properties.put("sql.show",true);
//用于SQL执行的工作线程数量,为零则表示无限制
propertie.setProperty("executor.size","4");
//每个物理数据库为每次查询分配的最大连接数量
propertie.setProperty("max.connections.size.per.query","1");
//是否在启动时检查分表元数据一致性
propertie.setProperty("check.table.metadata.enabled","false");
//用户自定义属性
Map<String, Object> configMap = new HashMap<>();
configMap.put("effect","分库分表");
return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig, properties);
}
// 配置相关的分片策略机制
private ShardingStrategyConfiguration getShardingStrategyConfiguration(){
// 精确匹配
PreciseShardingAlgorithm<Long> preciseShardingAlgorithm = new PreciseShardingAlgorithm<Long>() {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
String prefix = shardingValue.getLogicTableName(); //逻辑表名称
Long orderId = shardingValue.getValue(); //订单编码
long index = orderId % 2; //订单表(分表路由索引)
// t_order + "" + 0 = t_order0
String tableName = prefix + "" +index;
// 精确查询、更新之类的,可以返回不存在表,进而给前端抛出异常和警告。
if (availableTargetNames.contains(tableName) == false) {
LogUtils.error(log,"PreciseSharding","orderId:{},不存在对应的数据库表{}!", orderId, tableName);
return availableTargetNames.iterator().next();
}
return tableName;
// return availableTargetNames.iterator().next();
}
};
// 范围匹配
RangeShardingAlgorithm<Long> rangeShardingAlgorithm = new RangeShardingAlgorithm<Long>() {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, RangeShardingValue<Long> shardingValue) {
String prefix = shardingValue.getLogicTableName();
Collection<String> resList = new ArrayList<>();
// 获取相关的数据值范围
Range<Long> valueRange = shardingValue.getValueRange();
// 如果没有上限或者下限的没有,则直接返回所有的数据表
if (!valueRange.hasLowerBound() || !valueRange.hasUpperBound()) {
return availableTargetNames;
}
// 获取下限数据范围
long lower = shardingValue.getValueRange().lowerEndpoint();
BoundType lowerBoundType = shardingValue.getValueRange().lowerBoundType();
// 获取下限数据范围
long upper = shardingValue.getValueRange().upperEndpoint();
BoundType upperBoundType = shardingValue.getValueRange().upperBoundType();
// 下限数据信息值
long startValue = lower;
long endValue = upper;
// 是否属于开区间(下限)
if (lowerBoundType.equals(BoundType.OPEN)) {
startValue++; //缩减范围1
}
// 是否属于开区间(上限)
if (upperBoundType.equals(BoundType.OPEN)) {
endValue--; // 缩减范围1
}
// 进行计算相关所需要是实体表
for (long i = startValue; i <= endValue ; i++) {
long index = i % 2;
String res = prefix + "" +index;
// 精确查询、更新之类的,可以返回不存在表,进而给前端抛出异常和警告。
if (availableTargetNames.contains(res) == false) {
LogUtils.error(log,"RangeSharding","orderId:{},不存在对应的数据库表{}!", i, res);
}else{
resList.add(res);
}
}
if (resList.size() == 0) {
LogUtils.error(log,"RangeSharding","无法获取对应表,因此将对全表进行查询!orderId范围为:{}到{}",startValue,endValue);
return availableTargetNames;
}
return resList;
}
};
// 设置相关整体的算法整合
ShardingStrategyConfiguration strategyConf = new StandardShardingStrategyConfiguration("order_id", preciseShardingAlgorithm, rangeShardingAlgorithm);
return strategyConf;
}
// 获取相关的Order订单规则表配置信息控制配置控制机制
TableRuleConfiguration getOrderTableRuleConfiguration() {
// 逻辑表 + 实际节点 :设置逻辑表与数据节点(数据分片的最小单位)的映射关系机制
TableRuleConfiguration result = new TableRuleConfiguration("t_order", "ds${0..1}.t_order${0..1}");
// 主键生成配置
result.setKeyGeneratorConfig(getKeyGeneratorConfigurationForTOrder());
return result;
}
//主键操作的生成策略
private KeyGeneratorConfiguration getKeyGeneratorConfigurationForTOrder() {
Properties keyGeneratorProp = getKeyGeneratorProperties();
return new KeyGeneratorConfiguration("SNOWFLAKE", "order_id", keyGeneratorProp);
}
// 获取相关的Order订单规则表配置信息控制配置控制机制
TableRuleConfiguration getOrderItemTableRuleConfiguration() {
TableRuleConfiguration result = new TableRuleConfiguration("t_order_item", "ds${0..1}.t_order_item${0..1}");
result.setKeyGeneratorConfig(getKeyGeneratorConfigurationForTOrderItem());
return result;
}
// 创建相关keyOrderItem机制控制操作
private KeyGeneratorConfiguration getKeyGeneratorConfigurationForTOrderItem() {
Properties keyGeneratorProp = getKeyGeneratorProperties();
return new KeyGeneratorConfiguration("SNOWFLAKE", "id", keyGeneratorProp);
}
// 生成键值相关的generator的配置信息控制
private Properties getKeyGeneratorProperties() {
Properties keyGeneratorProp = new Properties();
String distributeProcessIdentify = NetUtils.getLocalAddress() + ":" + getProcessId();
String workId = String.valueOf(convertString2Long(distributeProcessIdentify));
keyGeneratorProp.setProperty("worker.id", workId);
LogUtils.info(log, "shardingsphere init", "shardingsphere work id raw string is {}, work id is {}", distributeProcessIdentify, workId);
return keyGeneratorProp;
}
// 数据源相关配置机制
Map<String, DataSource> createDataSourceMap() {
Map<String, DataSource> result = new HashMap<>();
result.put("ds0", DataSourceUtils.createDataSource("ds0"));
result.put("ds1", DataSourceUtils.createDataSource("ds1"));
return result;
}
// 常见相关的workerid和dataid对应相关的进程id
private String getProcessId(){
String name = ManagementFactory.getRuntimeMXBean().getName();
String pid = name.split("@")[0];
return pid;
}
// 转换字符串成为相关的long类型
private Long convertString2Long(String str){
long hashCode = str.hashCode() + System.currentTimeMillis();
if(hashCode < 0){
hashCode = -hashCode;
}
return hashCode % (1L << 10);
}
}
ShardingsphereMybatisConfig 配置机制
/**
* @Author zhangboqing
* @Date 2020/4/23
*/
@Configuration
@MapperScan(basePackages = "com.zbq.springbootshardingjdbcjavaconfigdemo.dao",sqlSessionFactoryRef = "sqlSessionFactoryForShardingjdbc")
public class ShardingsphereMybatisConfig {
@Autowired
@Qualifier("shardingDataSource")
private DataSource dataSource;
@Bean("sqlSessionFactoryForShardingjdbc")
public SqlSessionFactory sqlSessionFactoryForShardingjdbc() throws Exception {
SqlSessionFactoryBean sessionFactory = new SqlSessionFactoryBean();
sessionFactory.setDataSource(dataSource);
// sessionFactory.setMapperLocations(new PathMatchingResourcePatternResolver().
// getResources("classpath*:**/*.xml"));
sessionFactory.setTypeAliasesPackage("com.zbq.springbootshardingjdbcjavaconfigdemo.domain.entity");
org.apache.ibatis.session.Configuration configuration = new org.apache.ibatis.session.Configuration();
configuration.setMapUnderscoreToCamelCase(true);
sessionFactory.setConfiguration(configuration);
return sessionFactory.getObject();
}
}
ShardingsphereTransactionConfig 配置机制
主要定制化配置事务操作可以空战未来的,为了未来的查询扩展XA
@Configuration
@EnableTransactionManagement
public class ShardingsphereTransactionConfig {
@Bean
@Autowired
public PlatformTransactionManager shardingsphereTransactionManager(@Qualifier("shardingDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
}
【ShardingSphere技术专题】「ShardingJDBC」SpringBoot之整合ShardingJDBC实现分库分表(JavaConfig方式)的更多相关文章
- 分库分表(3) ---SpringBoot + ShardingSphere 实现读写分离
分库分表(3)---ShardingSphere实现读写分离 有关ShardingSphere概念前面写了两篇博客: 1.分库分表(1) --- 理论 2. 分库分表(2) --- ShardingS ...
- 一文快速入门分库分表中间件 Sharding-JDBC (必修课)
书接上文 <一文快速入门分库分表(必修课)>,这篇拖了好长的时间,本来计划在一周前就该写完的,结果家庭内部突然人事调整,领导层进行权利交接,随之宣布我正式当爹,紧接着家庭地位滑落至第三名, ...
- 分库分表之ShardingSphere
目录 分库分表诞生的前景 分库分表的方式(垂直拆分,水平复制) 1.垂直拆分 1.1 垂直分库 1.2 垂直分表 2.水平拆分 2.1 水平分库 2.2 水平分表 分库分库中间件 ShardingSp ...
- 分库分表神器 Sharding-JDBC,几千万的数据你不搞一下?
今天我们介绍一下 Sharding-JDBC框架和快速的搭建一个分库分表案例,为讲解后续功能点准备好环境. 一.Sharding-JDBC 简介 Sharding-JDBC 最早是当当网内部使用的一款 ...
- 采用Sharding-JDBC解决分库分表
源码:Sharding-JDBC(分库分表) 一.Sharding-JDBC介绍 1,介绍 Sharding-JDBC是当当网研发的开源分布式数据库中间件,从 3.0 开始Sharding-JDBC被 ...
- 利用sharding-jdbc分库分表
sharding-jdbc是当当开源的一款分库分表的数据访问层框架,能对mysql很方便的分库.分表,基本不用修改原有代码,只要配置一下即可,完整的配置参考以下内容: <?xml version ...
- 分库分表(4) ---SpringBoot + ShardingSphere 实现分表
分库分表(4)--- ShardingSphere实现分表 有关分库分表前面写了三篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3.分库 ...
- 分库分表(5) ---SpringBoot + ShardingSphere 实现分库分表
分库分表(5)--- ShardingSphere实现分库分表 有关分库分表前面写了四篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3. ...
- 分库分表(6)--- SpringBoot+ShardingSphere实现分表+ 读写分离
分库分表(6)--- ShardingSphere实现分表+ 读写分离 有关分库分表前面写了五篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论 ...
随机推荐
- CSS 奇思妙想 | 巧妙的实现带圆角的三角形
之前在这篇文章中 -- <老生常谈之 CSS 实现三角形>,介绍了 6 种使用 CSS 实现三角形的方式. 但是其中漏掉了一个非常重要的场景,如何使用纯 CSS 实现带圆角的三角形呢?,像 ...
- Docker基础:VMware虚拟机Centos7环境下docker安装及使用
1.docker简介 2.docker安装 3.卸载docker 4.阿里云镜像加速 5.docker的常用命令 5.1 帮助命令 5.2 镜像命令 5.3 容器命令 5.4 后台启动命令 5.5 查 ...
- 详解API Gateway流控实现,揭开ROMA平台高性能秒级流控的技术细节
摘要:ROMA平台的核心系统ROMA Connect源自华为流程IT的集成平台,在华为内部有超过15年的企业业务集成经验. 本文分享自华为云社区<ROMA集成关键技术(1)-API流控技术详解& ...
- 前端开发入门到进阶第二集【emmet插件的使用技巧】
Emmet (前身为 Zen Coding) 是一个能大幅度提高前端开发效率的一个工具.基本上,大多数的文本编辑器都会允许你存储和重用一些代码块,我们称之为"片段".虽然片段能很好 ...
- golang拾遗:内置函数len的小知识
len是很常用的内置函数,可以测量字符串.slice.array.channel以及map的长度/元素个数. 不过你真的了解len吗?也许还有一些你不知道的小知识. 我们来看一道GO101的题目,这题 ...
- js实现0ms延时定时器的几种方式
这两天看到一篇介绍<如何实现准时的 setTimeout?>的文章,文章起源于一道面试题:有什么办法让setTimeout准时呀?具体文章内容可查看附录[1],看完之后,引起了我对setT ...
- java String转List<Device>集合
// 从Redis中获得正常设备的数量 String success = redisService.get(RedisKey.CULTIVATION_RECORD_SUCCESS); //建立一个li ...
- java内存模型——重排序
线程安全问题概括来说表现为三个方面:原子性,可见性和有序性. 在多核处理器的环境下:编译器可能改变两个操作的先后顺序:处理器可能不是完全依照程序的目标代码所指定的顺序执行命令:一个处理器执行的多个操作 ...
- 13Java进阶——IO、线程
1 字节缓冲流 BufferInputStream 将创建一个内部的缓冲区数组,内部缓冲区数组将根据需要从包含的输入流中重新填充,一次可以读取多个字节 BufferOutputStream 该类实现缓 ...
- Python自动化测试面试题-Selenium篇
目录 Python自动化测试面试题-经验篇 Python自动化测试面试题-用例设计篇 Python自动化测试面试题-Linux篇 Python自动化测试面试题-MySQL篇 Python自动化测试面试 ...