MPI 学习笔记
MPI学习笔记
研究课题需要用到并行化,这里记录学习笔记
MPI准备
概述
MPI(Message Passin Interface 消息传递接口)是一种消息传递编程模型,是一个库。
MPI是一种标准或规范的代表,并不特指某一个对它具体实现。
目的:服务于进程间通信
前置知识补充
消息传输:从一个处理器的内存拷贝到另一个处理器内存的方式。
在分布式存储系统中,数据通常以消息包的形式通过网络从一个处理器发送到另一个处理器。
消息包 = 消息头控制信息 + 消息体数据信息
举例
序号:进程的标识,唯一
进程组:一个MPI程序的全部进程集合的一个有序子集,进程组中每个进程都被赋予了再该组中唯一的序号(rank),用于在该组中标识该进程。
tong'xin'yu
环境部署
三台虚拟机均为CentOS8,一台作为控制节点,另外两台作为计算节点。
1.修改IP及主机名
1.三台主机已经修改在同一个网关
2.设置了静态ip
c105 192.168.10.105 控制节点
c106 192.168.10.106 计算节点
c107 192.168.10.107 计算节点
3.做好了主机名和ip地址的映射关系
2.关闭防火墙
为了mpi运行成功,尽可以能降低通信延迟和系统开销,关闭防火墙达到最高的效率
关闭firewalld
[ranan@c105 ~]$ sudo systemctl stop firewalld //关闭防火墙
[ranan@c105 ~]$ sudo systemctl disable firewalld //设置防火墙不自启
关闭selinux
1.暂时关闭
setenforce 0
2.永久性关闭selinux
编辑selinux的配置文件/etc/sysconfig/selinux ,把SELINUX设置成disabled,然后重启生效
[ranan@c105 ~]$ sudo vim /etc/sysconfig/selinux
[ranan@c105 ~]$ cat /etc/sysconfig/selinux
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of these three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
3.实现免密码SSH登录
4.配置MPI运行环境
三台主机都需要配置
上传包到/opt/software
[root@c105 software]# rz
rz waiting to receive.
zmodem trl+C ȡ
正在传输 mpich-3.1.3.tar.gz...
100% 11218 KB 11218 KB/ 00:00:01 0
[root@c105 software]# ll
总用量 11220
-rw-r--r--. 1 root root 11487313 11月 17 16:48 mpich-3.1.3.tar.gz
解压包到/opt/module/
[root@c105 software]#tar -xvzf mpich-3.1.3.tar.gz -C /opt/module/
执行配置操作,作用是对即将安装的软件进行配置,检查当前的环境是否满足要安装软件的依赖关系。参数:–prefix=PREFIX 表示把所有文件装在目录PREFIX下而不是默认目录下。本系统安装目录为/home/mpi。配置成功后,最后一行提示显示“Configuration completed”。
[ranan@c105 mpich-3.1.3]$sudo ./configure --prefix=/home/mpi

报错信息:Incompatible Fortran and C Object File Types!
解决办法:sudo yum install gcc gcc-gfortran
[ranan@c105 mpich-3.1.3]$ make
[ranan@c105 mpich-3.1.3]$ make install
注意点:
step1 ./configure
step2 make
step3 make install
配置环境变量/home/mpi
[ranan@c105 ~]$ vim ~/.bashrc
export PATH=/home/mpi/bin:$PATH //与原来使用:进行拼接
export INCLUDE=/home/mpi/include:$INCLUDE
export LD_LIBRARY_PATH=/home/mpi/lib:$LD_LIBRARY_PATH
[ranan@c105 ~]$ source .bashrc //更新环境配置
测试是否配置成功
which mpicc
5.测试
复制测试例子到/home/mpi目录下,修改/home/mpi文件权限
[root@c106 mpich-3.1.3]# cp -r examples /home/mpi
[root@c106 mpich-3.1.3]# chown -R ranan:ranan /home/mpi
单节点测试
现在是c106节点机
[ranan@c106 ~]$ cd /home/mpi/examples/
[ranan@c106 examples]$ m
Process 0 of 6 is on c106
Process 1 of 6 is on c106
Process 2 of 6 is on c106
Process 4 of 6 is on c106
Process 5 of 6 is on c106
Process 3 of 6 is on c106
pi is approximately 3.1415926544231239, Error is 0.0000000008333307
wall clock time = 0.019008
多节点测试
测试6个进程再不同权重的节点机上运行
[ranan@c106 examples]$ vim nodes
[ranan@c106 examples]$ cat nodes
c105:3
c106:2
c107:1
[ranan@c106 examples]$ mpirun -np 6 -f nodes ./cpi
Process 3 of 6 is on c106
Process 0 of 6 is on c105
Process 5 of 6 is on c107
Process 4 of 6 is on c106
Process 1 of 6 is on c105
Process 2 of 6 is on c105
pi is approximately 3.1415926544231243, Error is 0.0000000008333312
wall clock time = 0.005398
程序的执行
编译语句
c
gcc编译器
mpicc -O2(优化选项) -o(生成可持续文件) heeloworld(编译成的执行文件名) helloworld.c(被编译的源文件)
c++
gcc编译器
mpicxx -O2(优化选项) -o heeloworld helloworld.c
运行语句
mpi普通程序运行执行
mpirun(mpiexec) -np 产生的进程数 可执行文件
集群mpi上运行
集群作业调度系统特定参数 + 可执行文件
mpirun -np 产生的进程数 -f 集群配置文件 ./可执行文件
集群配置文件的格式
ip地址:进程个数
ip地址:进程个数
...
MPI编程
C语言中的头文件 #include "mpi.h"
4个基本函数
MPI_Init(int *argc,char ***argv)
完成MPI程序初始化工作,通过获取main函数的参数,让每一个MPI程序都能获取到main函数
MPI_Comm_rank(MPI_Comm comm,int *rank)
用于获取调用进程在给定的通信域中的进程标识号。默认一个最大通信域word。
通信域中的序号是有序的
假设一个通信域中有p个进程,编号为0到p-1,利用进程的序号来决定负责计算数据集的哪一个部分。
MPI_Comm_size(MPI_Comm comm,int *size)
返回给定的通信域中所包含的进程总数
MPI_Finalize(void)
MPI程序的最后一个调用,清除全部MPI环境
MPI点对点通信函数
MPI的通信机制是在一对进程之间传递数据,称为点对点通信
MPI提供的点对点通信数据传输有两种机制
- 阻塞:等消息从本地发出之后,才进行执行后续的语句
- 非阻塞:不需要等待,实现通信与计算的重叠
非阻塞MPI_Send/MPI_Recv
MPI_Send用于发送方
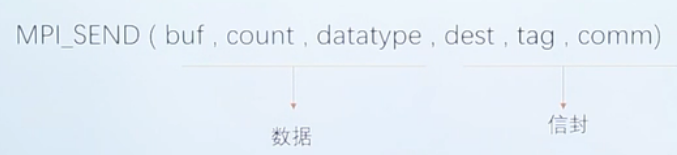
MPI_Send(void*buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm)
- buf 发送的数据缓存区的起始地址
- count 需要发送数据的个数
- datatype 需要发送的数据类型
- dest 目的进程的标识号
- tag 消息标志为tag
- comm 进程所在的域
MPI_Recv用于接收方
MPI_Recv(void*buf,int count,MPI_Datatype datatype,int source,int tag,MPI_Comm comm,MPI_Status *status)
从comm通信域中标识号为source的进程,接受消息标记为tag,消息数据类型为datatype,个数为count的消息并存储在buf缓冲区中,并将该过程的状态信息写入status中
在C语言中,status是一个结构体,包含了MPI_SOURCE(数据来源进程标识号),MPI_TAG(消息标记),MPI_ERROR
在Fortran语言中,status是一个整型的数组
阻塞MPI_Isend
Isend
int MPI_Isend(void*buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm,MPI_Request *request)
Irecv
int MPI_Irecv(void*buf,int count,MPI_Datatype datatype,int dest,int tag,MPI_Comm comm,MPI_Request *request)
MPI集合通信函数

1-n/n-1
集合通信还包括一个同步操作Barrier,所有进程都到达后才继续执行
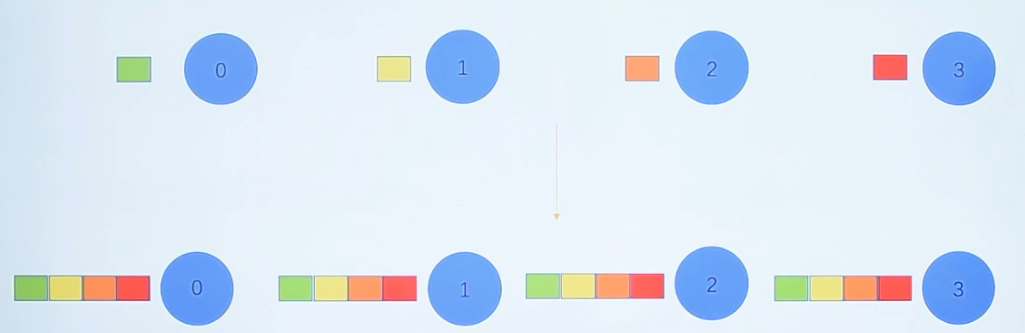
MPI_Bcast(void *buffer,int count,MPI_Datatype datatype,int root,MPI_Comm comm)
从指定的一个根进程中把相同的数据广播发送给组中的所有其他进程
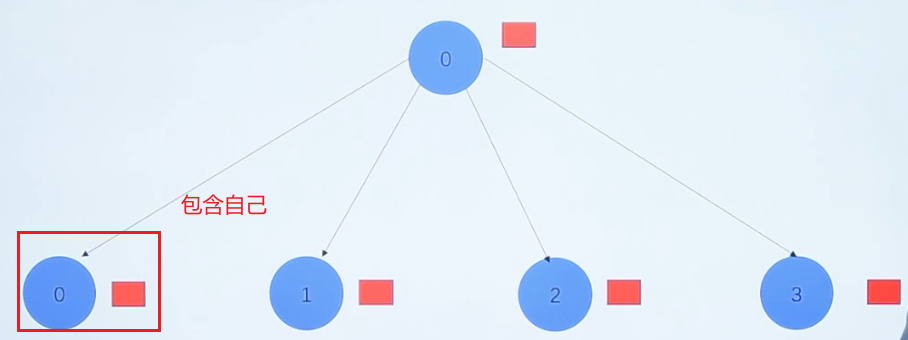
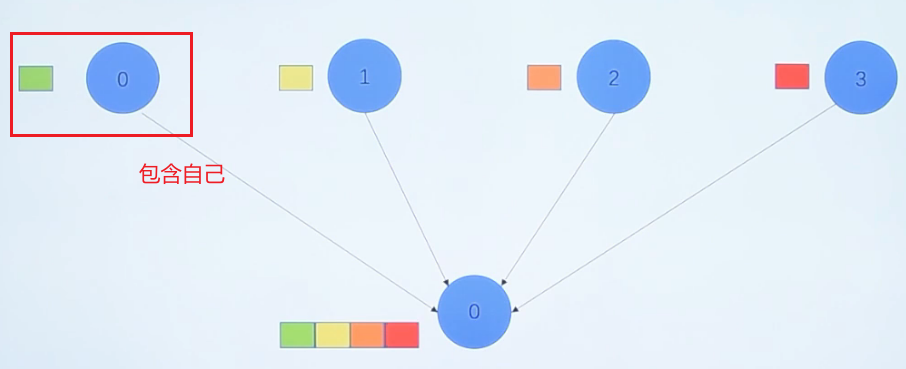
MPI_Scatter(void send_data,int send_count,MPI_Datatype send_datatype,void recv_data,int recv count,MPI_Datatype recv_datatype,int root,MPI_Comm communicator)
把指定的根进程中的数据分散发送给组中的所有进程(包括自己)
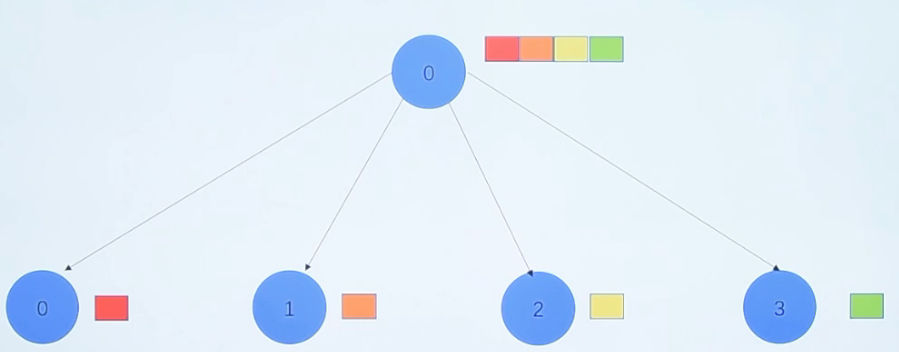
MPI_Gather(void *sendbuf,int sent_count,MPI_Datatype send_datatype,void *recv_data,int recv_count,MPI_Datatype recv_datatype,int root,MPI_Comm communicator)
在组中指定一个进程收集组中进程发来的消息,这个函数操作与MPI_Scatter函数操作相反
所有进程调用该函数,把指定位置的数据发送给根进程的指定位置
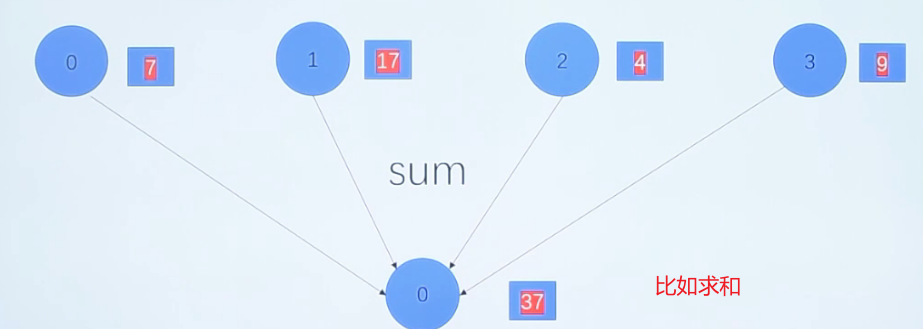
MPI_Reduce(void *send_data,void *recv_data,int count,MPI_Datatype datatype,MPI_Op op, int root,MPI_Comm communicator)
在组内所有的进程中,执行一个规约操作(算术等),并把结果存放在指定的一个进程中
举例

n-n

常用函数
计时函数
double MPI_Wtime(void)
功能:返回某一时刻到调用时刻经历的时间(s)
案例
double start_time,end_time,total_time; //初始化
start_time = MPI_Wtime();
//需要计时的部分
end_time = MPI_Wtime();
total_time = end_time - start_time
Printf("It looks %f seconds\n",total_time);
获得本进程的机器名函数
int MPI_Get_processor_name(char name,intresultlen)
name为返回的机器名字符串,resultlen为返回的机器名长度
//MPI_MAX_PROCESSOR_NAME代表MPI中允许机器名字的最大长度
int resultlen;
char processor_name[MPI_MAX_PROCESSOR_NAME];
MPI_Get_processor_name(processor_name,&resultlen);//resultlen存放长度
cout"当前运行的机器" <<processor_name<<endl;
测试案例
send
home/mpi/example/send_test.cpp
#include <stdio.h>
#include <iostream>
#include "mpi"
using namespace std;
/*从0号进程发送信息,其他进程接受信息*/
int main(int argc,char ** argv)
{
int rank;//记录进程标识号
int size;//记录通讯域中的进程个数
int senddata,recvdata;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Status status;
recvdata=0;
if(rank==0){ //发送数据的进程
for(int i=1;i<size;i++){
senddata=i+1000;
MPI_Send(&senddata,1,MPI_INT,i,i,MPI_COMM_WORLD);
}
}
if(rank!=0){ //接受数据的进程
MPI_Recv(&recvdata,1,MPI_INT,0,rank,MPI_COMM_WORLD,&status);
cout << "进程 " << rank <<"从 "<< status.MPI_SOURCE <<"接收信息,tag="<<status.MPI_TAG <<" and data=" <<recvdata<<endl;
}
MPI_Finalize();
return 0;
}
编译运行
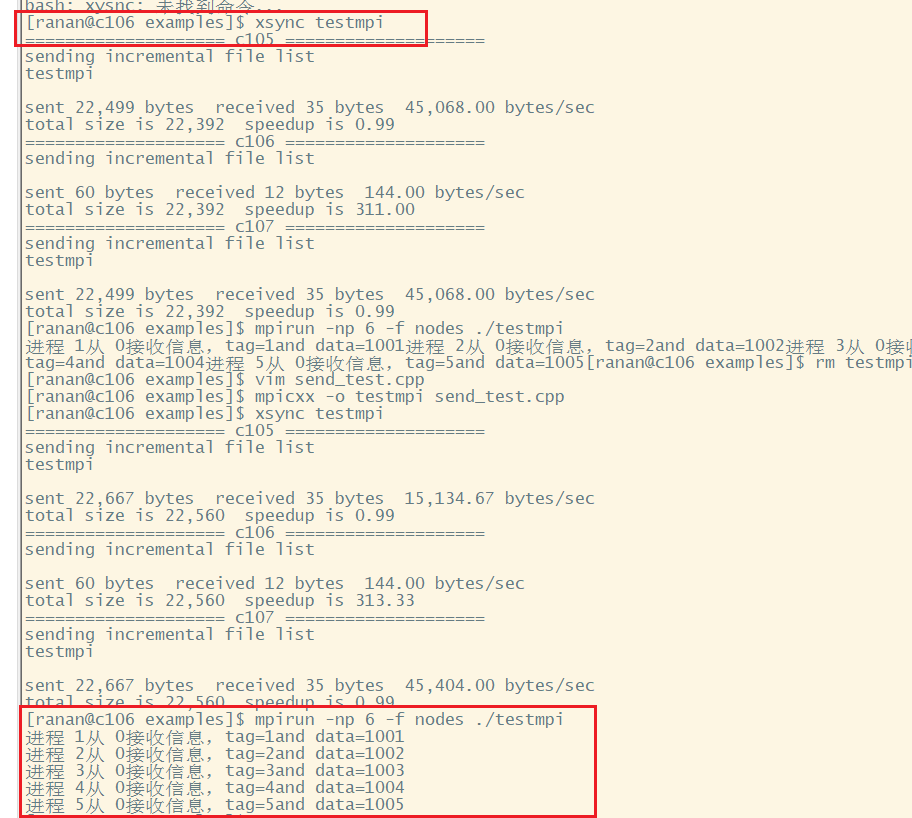
[ranan@c106 examples]$ mpicxx -o testmpi send_test.cpp
[ranan@c106 examples]$ xsync testmpi //把执行程序分发给c105 c107
[ranan@c106 examples]$ mpirun -np 6 -f nodes ./testmpi
MPI_Scatter 与 MPI_Gather
#include "stdio.h"
#include "mpi.h"
#include "stdlib.h"
#include <iostream>
#include <vector>
using namespace std;
const int N=2; //每个进程接受两个数据
int main(int argc,char ** argv){
int size,rank; //size记录总进程数,rank记录当前进程的标识号
int *send; //每个进程的发送缓存区
int *recv; //每个进程的接受缓存区
int *result; //接受其他进程发送过来的数据
int send_data[N]; //其他进程发送的数据;
int i=0;
int j=0;
int resultlen; //记录机器名的长度
char processor_name[MPI_MAX_PROCESSOR_NAME]; //运行的机器名
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD,&rank); //获得当前进程号
MPI_Comm_size(MPI_COMM_WORLD,&size); //获得总进程数,假设4个
MPI_Get_processor_name(processor_name,&resultlen);
recv = (int*) malloc(N*sizeof(int));
for(;i<N;i++){
recv[i] = 0; //原始的数据
}
//开始准备发送的数据
if(rank==0){
send = (int*) malloc(size*N*sizeof(int));
result = (int*) malloc(size*N*sizeof(int));
for(;j<N*size;j++){
send[j]=j+6; //6,7,8,9,10,11,12,13 ,大于等于10返回1,小于10返回0
}
}
//开始进行任务分发
MPI_Scatter(send,N,MPI_INT,recv,N,MPI_INT,0,MPI_COMM_WORLD); //0号进程分发
//输出分发结果
cout << "-----------------------"<<endl;
cout << "进程号"<<rank<<"当前运行的机器" <<processor_name<<endl;
for(i=0;i<N;i++){
cout << "传输后的recv["<<i<<"] = " <<recv[i]<<endl;
//数据处理
send_data[i] = (recv[i]>=10)?1:0;
cout << "当前值:" <<recv[i]<<",对应的send_data = "<< send_data[i] <<endl;
}
cout << "-----------------------"<<endl;
MPI_Gather(send_data,N,MPI_INT,result,N,MPI_INT,0,MPI_COMM_WORLD); //0号进程接受
//MPI_Barrier调用函数时进程将处于等待状态,直到通信子中所有进程 都调用了该函数后才继续执行。
MPI_Barrier(MPI_COMM_WORLD); //等待所有进程传送数据结束。
//输出汇聚的结果
if(rank==0){
for(j=0;j<N*size;j++){
cout << "result["<<j<<"]="<<result[j]<<endl;
}
}
MPI_Finalize();
return 0;
}

MPI 学习笔记的更多相关文章
- MPI学习笔记(二):矩阵相乘的两种实现方法
mpi矩阵乘法(C=αAB+βC) 最近领导让把之前安装的软件lapack.blas里的dgemm运算提取出来独立作为一套程序,然后把这段程序改为并行的,并测试一下进程规模扩展到128时的并行效率. ...
- MPI学习笔记(三):矩阵相乘的分块并行(行列划分法)
mpi矩阵乘法:C=αAB+βC 一.主从模式的行列划分并行法 1.实现方法 将可用于计算的进程数comm_sz分解为a*b,然后将矩阵A全体行划分为a个部分,将矩阵B全体列划分为b个部分,从而将整个 ...
- boost 学习笔记 0: 安装环境
boost 学习笔记 0: 安装环境 最完整的教程 http://einverne.github.io/post/2015/12/boost-learning-note-0.html Linux 自动 ...
- 《软件调试的艺术》学习笔记——GDB使用技巧摘要
<软件调试的艺术>学习笔记——GDB使用技巧摘要 <软件调试的艺术>,因为名是The Art of Debugging with GDB, DDD, and Eclipse. ...
- js学习笔记:webpack基础入门(一)
之前听说过webpack,今天想正式的接触一下,先跟着webpack的官方用户指南走: 在这里有: 如何安装webpack 如何使用webpack 如何使用loader 如何使用webpack的开发者 ...
- PHP-自定义模板-学习笔记
1. 开始 这几天,看了李炎恢老师的<PHP第二季度视频>中的“章节7:创建TPL自定义模板”,做一个学习笔记,通过绘制架构图.UML类图和思维导图,来对加深理解. 2. 整体架构图 ...
- PHP-会员登录与注册例子解析-学习笔记
1.开始 最近开始学习李炎恢老师的<PHP第二季度视频>中的“章节5:使用OOP注册会员”,做一个学习笔记,通过绘制基本页面流程和UML类图,来对加深理解. 2.基本页面流程 3.通过UM ...
- 2014年暑假c#学习笔记目录
2014年暑假c#学习笔记 一.C#编程基础 1. c#编程基础之枚举 2. c#编程基础之函数可变参数 3. c#编程基础之字符串基础 4. c#编程基础之字符串函数 5.c#编程基础之ref.ou ...
- JAVA GUI编程学习笔记目录
2014年暑假JAVA GUI编程学习笔记目录 1.JAVA之GUI编程概述 2.JAVA之GUI编程布局 3.JAVA之GUI编程Frame窗口 4.JAVA之GUI编程事件监听机制 5.JAVA之 ...
随机推荐
- 修炼Servlet
修炼Servlet 一.Servlet简单认识 1.Servlet是什么 Java Servlet 是运行在 Web 服务器或应用服务器上的程序,它是作为来自 Web 浏览器或其他 HTTP 客户端的 ...
- 基于live555开发嵌入式linux系统的rtsp直播服务
最近要搞一个直播服务,车机本身是个前后双路的Dvr,前路1080P 25fps,后路720P 50fps,现在要连接手机app预览实时画面,且支持前后摄像头画面切换. 如果要做直播,这个分辨率和帧率是 ...
- simulate_screencap
#!/bin/bashadb shell screencap -p /sdcard/screen.pngadb pull /sdcard/screen.png ./adb shell rm /sdca ...
- hdu 2058 The sum problem(简单因式分解,,)
Problem Description Given a sequence 1,2,3,......N, your job is to calculate all the possible sub-se ...
- 近期业务大量突增微服务性能优化总结-3.针对 x86 云环境改进异步日志等待策略
最近,业务增长的很迅猛,对于我们后台这块也是一个不小的挑战,这次遇到的核心业务接口的性能瓶颈,并不是单独的一个问题导致的,而是几个问题揉在一起:我们解决一个之后,发上线,之后发现还有另一个的性能瓶颈问 ...
- vim 打开文件的常用操作
一.如果在终端中开没有打开vim,可以: 横向分割显示: $ vim -o filename1 filename2 纵向分割显示: $ vim -O filename1 filename2 二.如果已 ...
- Lambda-让人又爱又恨的“->"
写在前边 聊到Java8新特性,我们第一反应想到的肯定是Lambda表达式和函数式接口的出现.要说ta到底有没有在一定程度上"优化"了代码的简洁性呢?抑或是ta在一定程度上给程序员 ...
- namespace之cgroup
Linux Namespace,但是Namespace解决的问题主要是环境隔离的问题,这只是虚拟化中最最基础的一步,我们还需要解决对计算机资源使用上的隔离.也就是说,虽然你通过Namespace把我J ...
- ES6基础知识(Reflect)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- ajax的post请求获取kfc官网数据
# _*_ coding : utf-8 _*_# @Time : 2021/11/2 13:45# @Author : 秋泊酱 # 1页 # http://www.kfc.com.cn/kfccda ...