基于Bert的恶意软件多分类
基于Bert从Windows API序列做恶意软件的多分类
0x00 数据集
https://github.com/ocatak/malware_api_class
偶然间发现,该数据集共有8种恶意软件家族,数量情况如下表。
| Malware Family | Samples | Description |
|---|---|---|
| Spyware | 832 | enables a user to obtain covert information about another's computer activities by transmitting data covertly from their hard drive. |
| Downloader | 1001 | share the primary functionality of downloading content. |
| Trojan | 1001 | misleads users of its true intent. |
| Worms | 1001 | spreads copies of itself from computer to computer. |
| Adware | 379 | hides on your device and serves you advertisements. |
| Dropper | 891 | surreptitiously carries viruses, back doors and other malicious software so they can be executed on the compromised machine. |
| Virus | 1001 | designed to spread from host to host and has the ability to replicate itself. |
| Backdoor | 1001 | a technique in which a system security mechanism is bypassed undetectably to access a computer or its data. |
每个样本的内容都是由Cuckoo Sandbox基于Windows OS API生成的,数据集种共有340种API,样本内容示例如下:
ldrloaddll ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress regopenkeyexa regopenkeyexa regopenkeyexa ntopenkey ntqueryvaluekey ntclose ntopenkey ntqueryvaluekey ntclose ntclose ntqueryattributesfile ntqueryattributesfile ntqueryattributesfile ntqueryattributesfile loadstringa ntallocatevirtualmemory ntallocatevirtualmemory loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa loadstringa ldrgetdllhandle ldrgetprocedureaddress ldrgetdllhandle ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrgetprocedureaddress ldrloaddll ldrgetprocedureaddress ldrunloaddll findfirstfileexw copyfilea regcreatekeyexa regsetvalueexa regclosekey createprocessinternalw ntclose ntclose ntclose ntfreevirtualmemory ntterminateprocess ntterminateprocess ntclose ntclose ntclose ntclose ntclose ntclose ntclose ldrunloaddll ntopenkey ntqueryvaluekey ntclose ntclose ntclose ntclose ntterminateprocess
0x01 BERT
词嵌入模型有word2vec、glove、fasttext可用,最近在用BERT系列的模型,所以想用来尝试一下BERT在安全领域的NLP应用效果。
BERT的模型加载
第一步,下载模型。这里个人习惯用pytorch构建深度学习模型,所以这里下载的是torch版BERT预训练模型。BERT加载使用时需要三个文件,vocab.txt--用于对文本分词和构建输入,pytorch_model.bin和config.json--用于加载BERT预训练模型
# vocab 文件下载
'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt",
'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-vocab.txt",
'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased-vocab.txt",
'bert-large-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased-vocab.txt",
'bert-base-multilingual-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-uncased-vocab.txt",
'bert-base-multilingual-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased-vocab.txt",
'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt",
# 预训练模型参数下载
'bert-base-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased.tar.gz",
'bert-large-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased.tar.gz",
'bert-base-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-cased.tar.gz",
'bert-large-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-cased.tar.gz",
'bert-base-multilingual-uncased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-uncased.tar.gz",
'bert-base-multilingual-cased': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-multilingual-cased.tar.gz",
'bert-base-chinese': "https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese.tar.gz",
第二步,文本嵌入示例:
从文本到ids
from pytorch_pretrained_bert import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('./bert/vocab.txt')
bert = BertModel.from_pretrained('./bert/')
content = "this is an apple, this is a pen"
CLS = '[CLS]'
token = tokenizer.tokenize(content)
token = [CLS] + token
token_ids = tokenizer.convert_tokens_to_ids(token)
从ids到词嵌入、分类
bert模型输入参数要求
input_ids, token_type_ids=None, attention_mask=None, output_all_encoded_layers=True
intpu_ids,按bert的vocab分词后,切换到ids
token_type_ids,可选。就是 token 对应的句子id,值为0或1(0表示对应的token属于第一句,1表示属于第二句)。形状为(batch_size, sequence_length)。
[CLS] this is an apple ? [SEP] this is a pen . [SEP] 句子
0 0 0 0 0 0 0 1 1 1 1 1 1 token_type_ids
- attention_mask,对应input_ids中非padding的部分为1,padding的部分为0,用于加快计算速度
list_12_outs, pooled = bert(token_ids, output_all_encoded_layers=True)
由于output_all_encoded_layers=True,12层Transformer的结果全返回了,存在list_12_outs的列表中,列表中的每一个张量的大小都是[batch_size, sequence_length, hidden_size]
pooled是大小为[batch_size, hidden_size]的张量,也就是最后一层Transformer的输出结果的第一个单词[CLS]的hidden_states,蕴含了整个input句子的信息。
bert_embedding, pooled = bert(token_ids, output_all_encoded_layers=False)
当output_all_encoded_layers=False时,输出的第一个结果bert_embedding是大小为[batch_size, sequence_len, 768],其中768相当于embedding dim。
pooled还是对整句话的表示,可以该值作为分类结果
def __init__()
self.classifier = nn.Linear(1024, 2)
out = self.classifier(pooled)
return out
如果希望将bert结合更多模型,可以使用embedding的张量,继续添加各种层
是否需要训练bert的参数?
冻结所有参数
for param in self.bert.parameters():
param.requires_grad_(False)
如果直接使用pooled结果进行分类,建议将Bert里除了pooler层之外参数冻结,从实验效果来看,会更好
for name, param in self.bert.named_parameters():
if name.startswith('pooler'):
continue
else:
param.requires_grad_(False)
0x02 数据预处理
训练集和测试集比例为8:2,并且严格对每一类恶意软件都采取8:2的比例。另外,BERT支持一次最多输入512个token,所以对样本中连续的API替换为一个,这样处理后,样本的API序列还是很长,所以决定使用样本的1020个个token,并将其切分为2*510的两段,每段前后各加上[CLS]和[SEP],这样恰好成为两段512长度的tokens。
def load_data(max_sequnce, data_file, label_file):
CLS, SEP, PAD = 101, 102, 0 # tokenizer.convert_tokens_to_ids(['[CLS]','[SEP]', '[PAD]']) 分别是对应的id
api_list = open(data_file, 'r', encoding='utf-8').readlines()
lab_list = open(label_file, 'r', encoding='utf-8').readlines()
# 用这个dict存储每一类数据和其mask,然后8:2分割 Trojan:[(ids, mask), (ids, mask)]
collected_by_label = {
"Trojan": [],
"Backdoor": [],
"Downloader":[],
"Worms": [],
"Spyware": [],
"Adware": [],
"Dropper": [],
"Virus": []
}
train_input_ids = []
train_input_mak = []
train_input_lab = []
test_input_ids = []
test_input_mak = []
test_input_lab = []
for index in tqdm(range(len(lab_list))):
last_api = ''
simple_api = []
label = lab_list[index].strip() # 去掉末尾的\n
api = api_list[index].strip().replace('\t', ' ').replace('\s', ' ').replace('\xa0', ' ')
while ' ' in api:
api = api.replace(' ', ' ')
for i in api.split(' '):
if i != last_api:
simple_api.append(i)
last_api = i
# api -> ids
ids = []
for j in simple_api:
ids += api_index[j]
if len(ids) > max_sequnce-4: # 由于是1024,所以要加两次cls、sep
ids = ids[:(max_sequnce-4)]
ids = [CLS] + ids[:510] + [SEP] + [CLS] + ids[510:] + [SEP]
mask = [1]*len(ids)
elif len(ids)> 510:
ids = [CLS] + ids[:510] + [SEP] + [CLS] + ids[510:] + [SEP]
mask = [1]*len(ids)
else:
ids = [CLS] + ids + [SEP]
mask = [1]*len(ids)
if len(ids) <= max_sequnce:
ids = ids + [PAD]*(max_sequnce-len(ids))
mask = mask + [0]*(max_sequnce-len(mask))
collected_by_label[label].append((ids, mask))
# 8:2切分数据集以及合并train、test
for label, data in tqdm(collected_by_label.items()):
label = label_index[label] # "Trojan" -> [0,0,0,0,0,0,0,1]
train = data[:len(data)//10*8]
test = data[len(data)//10*8:]
for ids, mask in train:
train_input_ids.append(ids)
train_input_mak.append(mask)
train_input_lab.append(label)
for ids, mask in test:
test_input_ids.append(ids)
test_input_mak.append(mask)
test_input_lab.append(label)
train_input_ids = torch.tensor(train_input_ids, dtype=torch.int64)
train_input_mak = torch.tensor(train_input_mak, dtype=torch.int64)
train_input_lab = torch.tensor(train_input_lab, dtype=torch.int64)
test_input_ids = torch.tensor(test_input_ids, dtype=torch.int64)
test_input_mak = torch.tensor(test_input_mak, dtype=torch.int64)
test_input_lab = torch.tensor(test_input_lab, dtype=torch.int64)
return train_input_ids,train_input_mak,train_input_lab,test_input_ids,test_input_mak,test_input_lab
0x03 模型框架和代码
(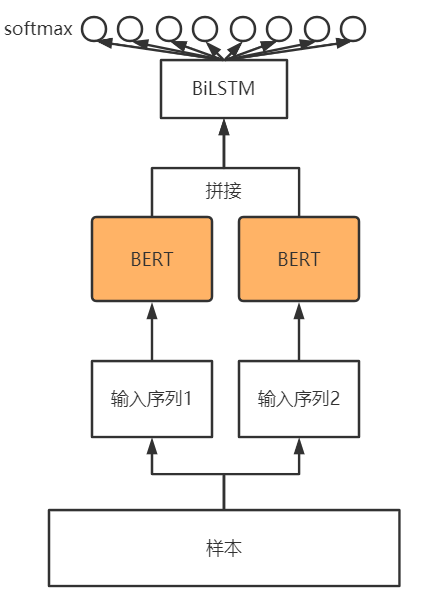
模型框架如图所示,两个长度为512的输入序列分别使用BERT做embedding,BERT的输出将被拼接在一起(torch.cat函数),拼接的函数将会输入BiLSTM层,最后输入全连接的softmax层。softmax层有八个神经元,对应8种分类。实际模型中在BiLSTM层后添加了Highway层,Highway层可以更好的向BiLSTM层反馈梯度。
模型定义代码
class Highway(nn.Module):
def __init__(self, input_dim, num_layers=1):
super(Highway, self).__init__()
self._layers = nn.ModuleList([nn.Linear(input_dim, input_dim * 2) for _ in range(num_layers)])
for layer in self._layers:
layer.bias[input_dim:].data.fill_(1)
def forward(self, inputs):
current_inputs = inputs
for layer in self._layers:
linear_part = current_inputs
projected_inputs = layer(current_inputs)
nonlinear_part, gate = projected_inputs.chunk(2, dim=-1)
nonlinear_part = torch.relu(nonlinear_part)
gate = torch.sigmoid(gate)
current_inputs = gate * linear_part + (1 - gate) * nonlinear_part
return current_inputs
class Bert_HBiLSTM(nn.Module):
"""
Bert_HBiLSTM
"""
def __init__(self, config):
super(Bert_HBiLSTM, self).__init__()
self.bert = config.bert
self.config = config
for name, param in self.bert.named_parameters():
param.requires_grad_(False)
self.lstm = nn.LSTM(config.embedding_dim, config.hidden_dim, num_layers=config.num_layers, batch_first=True,
bidirectional=True)
self.drop = nn.Dropout(config.drop_rate)
self.highway = Highway(config.hidden_dim * 2, 1)
self.hidden2one = nn.Linear(config.hidden_dim*2, 1)
self.relu = nn.ReLU()
self.sequence2numclass = nn.Linear(config.max_sequnce, config.num_class)
def forward(self, word_input, input_mask):
word_input_last = word_input[:, 512:]
word_input = word_input[:, :512]
input_mask_last = input_mask[:, 512:]
input_mask = input_mask[:, :512]
word_input, _ = self.bert(word_input, attention_mask=input_mask, output_all_encoded_layers=False)
word_input_last, _ = self.bert(word_input_last, attention_mask=input_mask_last, output_all_encoded_layers=False)
input_mask.requires_grad = False
input_mask_last.requires_grad = False
word_input = word_input * (input_mask.unsqueeze(-1).float())
word_input_last = word_input_last * (input_mask_last.unsqueeze(-1).float())
cat_input = torch.cat([word_input, word_input_last], dim=1)
# bert->bilstm->highway
lstm_out, _ = self.lstm(cat_input)
output = self.highway(lstm_out)
output = self.drop(output)
# hidden_dim*2 -> 1 -> sequense
output = self.hidden2one(output)
output = output.squeeze(-1)
output = self.sequence2numclass(output)
output = F.log_softmax(output, dim=1)
return output
完整代码和数据可在github获取https://github.com/bitterzzZZ/Bert-malware-classification
基于Bert的恶意软件多分类的更多相关文章
- 基于Bert的文本情感分类
详细代码已上传到github: click me Abstract: Sentiment classification is the process of analyzing and reaso ...
- 基于BERT预训练的中文命名实体识别TensorFlow实现
BERT-BiLSMT-CRF-NERTensorflow solution of NER task Using BiLSTM-CRF model with Google BERT Fine-tuni ...
- 五分钟搭建一个基于BERT的NER模型
BERT 简介 BERT是2018年google 提出来的预训练的语言模型,并且它打破很多NLP领域的任务记录,其提出在nlp的领域具有重要意义.预训练的(pre-train)的语言模型通过无监督的学 ...
- NLP之基于BERT的预测掩码标记和句间关系判断
BERT @ 目录 BERT 程序步骤 程序步骤 设置基本变量值,数据预处理 构建输入样本 在样本集中随机选取a和b两个句子 把ab两个句子合并为1个模型输入句,在句首加入分类符CLS,在ab中间和句 ...
- 基于Spark Mllib的文本分类
基于Spark Mllib的文本分类 文本分类是一个典型的机器学习问题,其主要目标是通过对已有语料库文本数据训练得到分类模型,进而对新文本进行类别标签的预测.这在很多领域都有现实的应用场景,如新闻网站 ...
- matlab 基于 libsvm工具箱的svm分类遇到的问题与解决
最近在做基于无线感知的身份识别这个工作,在后期数据处理阶段,需要使用二分类的方法进行训练模型.本身使用matlab做,所以看了一下网上很多都是使用libsvm这个工具箱,就去下载了,既然用到了想着就把 ...
- 基于bert的命名实体识别,pytorch实现,支持中文/英文【源学计划】
声明:为了帮助初学者快速入门和上手,开始源学计划,即通过源代码进行学习.该计划收取少量费用,提供有质量保证的源码,以及详细的使用说明. 第一个项目是基于bert的命名实体识别(name entity ...
- 基于bert训练自己的分词系统
前言 在中文分词领域,已经有着很多优秀的工具,例如: jieba分词 SnowNLP 北京大学PKUse 清华大学THULAC HanLP FoolNLTK 哈工大LTP 斯坦福分词器CoreNLP ...
- NLP之基于TextCNN的文本情感分类
TextCNN @ 目录 TextCNN 1.理论 1.1 基础概念 最大汇聚(池化)层: 1.2 textCNN模型结构 2.实验 2.1 实验步骤 2.2 算法模型 1.理论 1.1 基础概念 在 ...
随机推荐
- Mac终端学习C笔记
Mac终端自带Clang,是一个C语言.C++.Objective-C语言的轻量级编译器,也可以进行c程序编译.具体Clang和gcc区别不做详细介绍. 终端自动vi编辑器. 终端命令笔记: gcc ...
- CF1454B Unique Bid Auction 题解
Content 给定一个长度为 \(n\) 的数列 \(\{a_i\}_{i=1}^n\),请找出在数列中仅出现一次的最小的数的位置. 数据范围:\(t\) 组询问,\(1\leqslant t\le ...
- java 常用类库:String ; StringBuilder和StringBuffer类
1. String 1.String对象是不可变的 String类的value属性是用来存放字符串里面的值的.这个属性是被final修饰的.final修饰的变量不能够被第二次赋值,所以字符串是不可变的 ...
- JAVA获取当前日期的下周一到下周日的所有日期集合
/** * 获取当前日期的下周一到下周日的所有日期集合 * @return */ public static List getNextWeekDateList(){ Calendar cal1 = C ...
- Dapr项目应用探索
背景介绍 前面文章对Dapr的基本信息进行了学习,接下来尝试将Dapr应用相关应用中. 接下来一步步实现应用dapr功能. 一.预期效果 如上图应用Dapr点包含: a) 报表服务绑定统一数据源服务: ...
- 【LeetCode】624. Maximum Distance in Arrays 解题报告(C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 大根堆+小根堆 保存已有的最大最小 日期 题目地址:h ...
- 【LeetCode】400. Nth Digit 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- 【LeetCode】933. Number of Recent Calls 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 二分查找 队列 相似题目 参考资料 日期 题目地址: ...
- 【机器学*】k*邻算法-03
心得体会: 需要思考如何将现实对象转化为特征向量,设置特征向量时记住鸭子定律1 鸭子定律1 如果走路像鸭子.说话像鸭子.长得像鸭子.啄食也像鸭子,那它肯定就是一只鸭子 事物的外在特征就是事物本质的表现 ...
- Linux中架构中的备份服务器搭建(rsync)
本期内容概要 Linux中的备份方式 架构中备份服务器搭建(rsync) 内容详细 1.备份方式 1. cp : 本机复制(只能作用在本机) 2. scp : 远程复制 两种模式: 推 : 本地上传到 ...