使用numba加速python科学计算
技术背景
python作为一门编程语言,有非常大的生态优势,但是其执行效率一直被人诟病。纯粹的python代码跑起来速度会非常的缓慢,因此很多对性能要求比较高的python库,需要用C++或者Fortran来构造底层算法模块,再用python进行上层封装的方案。在前面写过的这篇博客中,介绍了使用f2py将fortran代码编译成动态链接库的方案,这可以认为是一种“事前编译”的手段。但是本文将要介绍一种即时编译(Just In Time,简称JIT)的手段,也就是在临近执行函数前,才对其进行编译。以下截图来自于参考链接4,讲述了关于常见的一些编译场景的区别:

用numba.jit加速求平方和
numba中大部分加速的函数都是通过装饰器(decorator)来实现的,关于python中decorator的使用方法和场景,在前面写过的这篇博客中有比较详细的介绍,让我们直接使用numba的装饰器来解决一些实际问题。这里的问题场景是,随便给定一个数列,在不用求和公式的情况下对这个数列的所有元素求平方和,即:
\]
我们已知类似于这种求和的形式,其实是有很大的优化空间的,相比于直接用一个for循环来求解的话。这里我们直接展示一下案例代码:
# test_jit.py
from numba import jit
import time
import matplotlib.pyplot as plt
def adder(max): # 普通的循环求解
s = 0
for i in range(max):
s += i ** 2
return s
@jit(nopython=True)
def jit_adder(max): # 使用即时编译求解
s = 0
for i in range(max):
s += i ** 2
return s
if __name__ == '__main__':
time_adder = []
time_jit_adder = []
x = list(range(1, 10000000, 500000))
for i in x:
time1 = time.time()
s = adder(i)
time2 = time.time()
s = jit_adder(i)
time3 = time.time()
time_adder.append(time2 - time1)
time_jit_adder.append(time3 - time2)
# 开始作图
fig, ax1 = plt.subplots()
color = 'black'
ax1.set_xlabel('Numbers')
ax1.set_ylabel('Time (s)', color=color)
ax1.plot(x[1:], time_adder[1:], color=color, label='python')
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx() # 第二个y-坐标轴
color = 'red'
ax2.set_ylabel('Time (s)', color=color)
ax2.plot(x[1:], time_jit_adder[1:], color=color, label='jit')
ax2.tick_params(axis='y', labelcolor=color)
plt.title('Running time difference via using jit')
fig.tight_layout()
plt.legend()
plt.savefig('jit.png')
运行该python文件,会在当前目录下产生一个双坐标轴的图像:
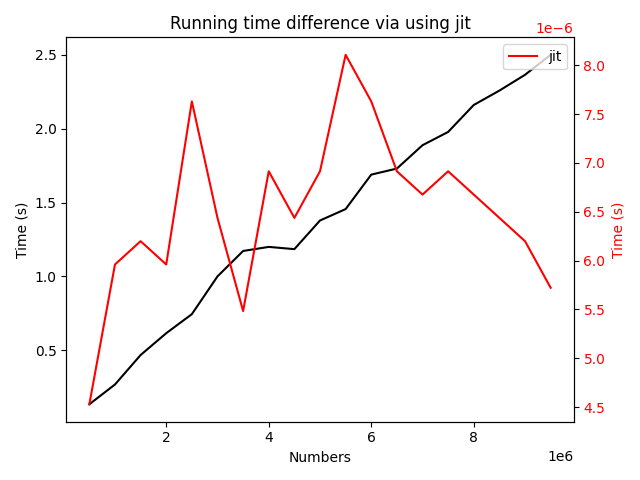
在这个计算结果中,使用了即时编译技术之后,求解的时间几乎被压缩到了微秒级别,而循环求和的方法却已经达到了秒级,加速倍数在\(10^5\)级别。
用numba.jit加速求双曲正切函数和
在上一个案例中,也许涉及到的计算过于的简单,导致了加速倍数超出了想象的情况。因此这里我们只替换所求解的函数,看看加速的倍数是否会发生变化。这里我们采用了双曲正切求和的函数:
\]
通过math来实现这个函数的计算,用以替换上一章节中求平方值的方法:
# test_jit.py
from numba import jit
import time
import matplotlib.pyplot as plt
import math
def adder(max):
s = 0
for i in range(max):
s += math.tanh(i ** 2)
return s
@jit(nopython=True)
def jit_adder(max):
s = 0
for i in range(max):
s += math.tanh(i ** 2)
return s
if __name__ == '__main__':
time_adder = []
time_jit_adder = []
x = list(range(1, 10000000, 500000))
for i in x:
time1 = time.time()
s = adder(i)
time2 = time.time()
s = jit_adder(i)
time3 = time.time()
time_adder.append(time2 - time1)
time_jit_adder.append(time3 - time2)
fig, ax1 = plt.subplots()
color = 'black'
ax1.set_xlabel('Numbers')
ax1.set_ylabel('Time (s)', color=color)
ax1.plot(x[1:], time_adder[1:], color=color, label='python')
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx()
color = 'red'
ax2.set_ylabel('Time (s)', color=color)
ax2.plot(x[1:], time_jit_adder[1:], color=color, label='jit')
ax2.tick_params(axis='y', labelcolor=color)
plt.title('Running time difference via using jit')
fig.tight_layout()
plt.legend()
plt.savefig('jit.png')
最终得到的时间对比图结果如下所示:
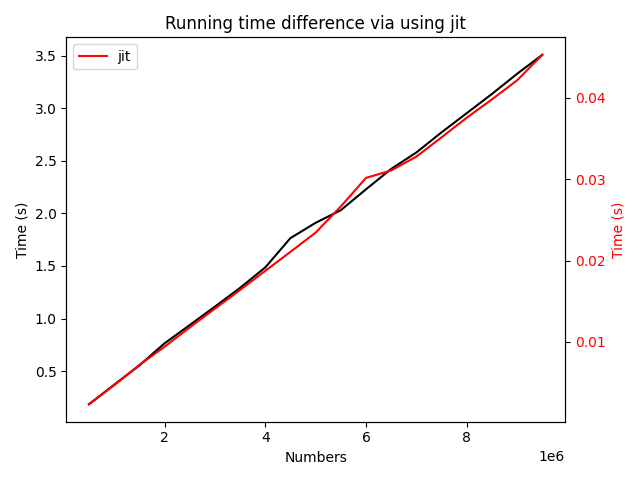
需要提醒的是,黑色的曲线所对应的坐标轴是左边黑色标识的坐标轴,而红色的曲线所对应的坐标轴是右边红色标识的坐标轴。因此,这个图给我们的提示信息是,使用即时编译技术之后,加速的倍率大约为\(10^2\)。这个加速倍率相对来说更加可以接受,因为C++等语言比python直接计算的速度在特定场景下大概就是要快上几百倍。
用numba.vectorize执行向量化计算
关于向量化计算的原理和方法,在这篇文章中有比较好的描述,这里放上部分截图说明:
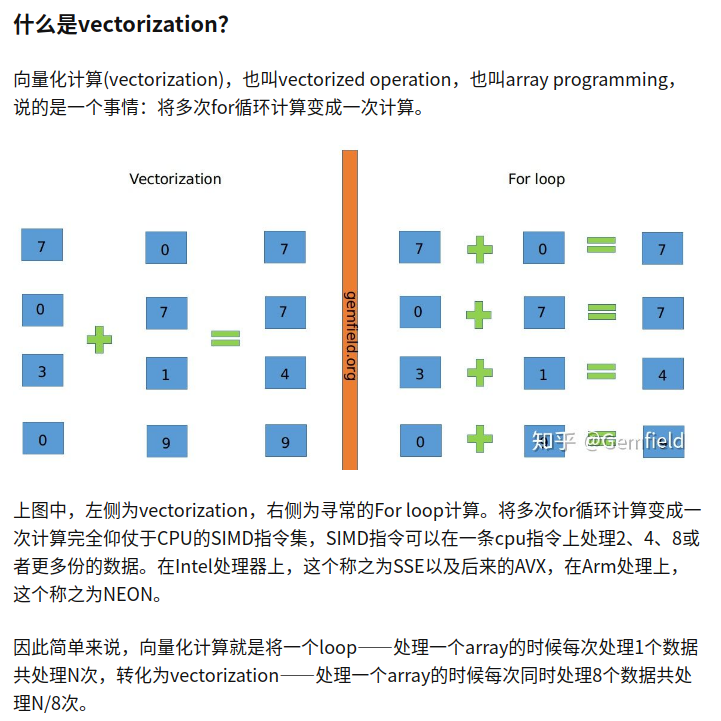

总结为,向量化计算的方法本质上也是一种并行化计算的方法,并行化技术的可行性是来源于SIMD技术,在指令集的层面对数据进行并行化的处理。在numpy的库中是自带支持SIMD的向量化计算的,因此速度非常的高,比如numpy.dot函数就是通过向量化计算来实现的。但是numpy能够执行的任务仅仅局限在numpy自身所支持的有限的函数上,因此如果是需要一个不同的函数,那么就需要用到numba的向量化计算模块了。
# test_vectorize.py
from numba import vectorize
import numpy as np
import time
import matplotlib.pyplot as plt
def ddot(max):
s = 0
np.random.seed(1)
a1 = np.random.randn(max)
np.random.seed(2)
a2 = np.random.randn(max)
for i in range(max):
s += a1[i] * a2[i]
return s
@vectorize
def jit_ddot(max):
s = 0
np.random.seed(1)
a1 = np.random.randn(max)
np.random.seed(2)
a2 = np.random.randn(max)
for i in range(max):
s += a1[i] * a2[i]
return s
def numpy_ddot(max):
np.random.seed(1)
a1 = np.random.randn(max)
np.random.seed(2)
a2 = np.random.randn(max)
return np.dot(a1, a2)
if __name__ == '__main__':
time_ddot = []
time_jit_ddot = []
time_numpy_ddot = []
x = list(range(1, 1000000, 50000))
for i in x:
time1 = time.time()
s = ddot(i)
time2 = time.time()
s = jit_ddot(i)
time3 = time.time()
s = numpy_ddot(i)
time4 = time.time()
time_ddot.append(time2 - time1)
time_jit_ddot.append(time3 - time2)
time_numpy_ddot.append(time4 - time3)
fig, ax1 = plt.subplots()
color = 'black'
ax1.set_xlabel('Numbers')
ax1.set_ylabel('Time (s)', color=color)
ax1.plot(x[1:], time_ddot[1:], color=color, label='python')
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ax1.twinx()
color = 'red'
ax2.set_ylabel('Time (s)', color=color)
ax2.plot(x[1:], time_jit_ddot[1:], color=color, label='jit')
ax2.plot(x[1:], time_numpy_ddot[1:], 's', color=color, label='numpy')
ax2.tick_params(axis='y', labelcolor=color)
plt.title('Running time difference via using jit')
fig.tight_layout()
plt.legend()
plt.savefig('jit.png')
运行结果如下:
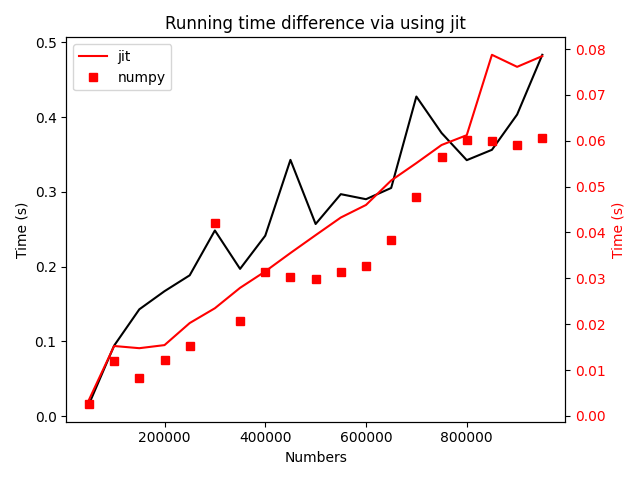
可以看到虽然相比与numpy的同样的向量化计算方法,numba速度略慢一些,但是都比纯粹的python代码性能要高两个量级。这里也给我们一个启发,如果追求极致的性能,最好是尽可能的使用numpy中已有的函数。当然,在一些数学函数的计算上,numpy的速度比math还是要慢上一些的,这里我们就不展开介绍了。
总结概要
本文介绍了numba的两个装饰器的原理与测试案例,以及python中两坐标轴绘图的案例。其中基于即时编译技术jit的装饰器,能够对代码中的for循环产生较大的编译优化,可以配合并行技术使用。而基于SIMD的向量化计算技术,也能够在向量的计算中,如向量间的乘加运算等场景中,实现巨大的加速效果。这都是非常底层的优化技术,但是要分场景使用,numba这个强力的工具并不能保证在所有的计算场景下都能够产生如此的加速效果。
版权声明
本文首发链接为:https://www.cnblogs.com/dechinphy/p/numba.html
作者ID:DechinPhy
更多原著文章请参考:https://www.cnblogs.com/dechinphy/
参考链接
- https://zhuanlan.zhihu.com/p/78882641
- https://blog.csdn.net/yuanzhoulvpi/article/details/105307338
- https://zhuanlan.zhihu.com/p/68805601
- https://zhuanlan.zhihu.com/p/193035135
- https://zhuanlan.zhihu.com/p/72953129
使用numba加速python科学计算的更多相关文章
- 使用numba加速python程序
前面说过使用Cython来加速python程序的运行速度,但是相对来说程序改动较大,这次就说一种简单的方式来加速python计算速度的方法,就是使用numba库来进行,numba库可以使用JIT技术即 ...
- windows下安装python科学计算环境,numpy scipy scikit ,matplotlib等
安装matplotlib: pip install matplotlib 背景: 目的:要用Python下的DBSCAN聚类算法. scikit-learn 是一个基于SciPy和Numpy的开源机器 ...
- Python科学计算(二)windows下开发环境搭建(当用pip安装出现Unable to find vcvarsall.bat)
用于科学计算Python语言真的是amazing! 方法一:直接安装集成好的软件 刚开始使用numpy.scipy这些模块的时候,图个方便直接使用了一个叫做Enthought的软件.Enthought ...
- 目前比较流行的Python科学计算发行版
经常有身边的学友问到用什么Python发行版比较好? 其实目前比较流行的Python科学计算发行版,主要有这么几个: Python(x,y) GUI基于PyQt,曾经是功能最全也是最强大的,而且是Wi ...
- Python科学计算之Pandas
Reference: http://mp.weixin.qq.com/s?src=3×tamp=1474979163&ver=1&signature=wnZn1UtW ...
- Python 科学计算-介绍
Python 科学计算 作者 J.R. Johansson (robert@riken.jp) http://dml.riken.jp/~rob/ 最新版本的 IPython notebook 课程文 ...
- Python科学计算库
Python科学计算库 一.numpy库和matplotlib库的学习 (1)numpy库介绍:科学计算包,支持N维数组运算.处理大型矩阵.成熟的广播函数库.矢量运算.线性代数.傅里叶变换.随机数生成 ...
- Python科学计算基础包-Numpy
一.Numpy概念 Numpy(Numerical Python的简称)是Python科学计算的基础包.它提供了以下功能: 快速高效的多维数组对象ndarray. 用于对数组执行元素级计算以及直接对数 ...
- Python科学计算PDF
Python科学计算(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1VYs9BamMhCnu4rfN6TG5bg 提取码:2zzk 复制这段内容后打开百度网盘手机A ...
随机推荐
- [译]我是如何将GTA在线模式的加载时间缩短70%的
[译]我是如何将GTA在线模式的加载时间缩短70%的 译注: 最近在网上发现了一篇有意思的文章, 一个国外大神受不了GTA5在线模式的加载时间, 一怒之下反汇编了GTA5的源码, 并最终发现了问题的原 ...
- 【转载】java类加载时机与过程
1 开门见山 以前曾经看到过一个java的面试题,当时觉得此题很简单,可是自己把代码运行起来,可是结果并不是自己想象的那样.题目如下: class SingleTon { private stati ...
- rsyslog日志总结
rsyslog日志总结 一 rsyslog介绍 syslogd被rsyslog取代 将日志写入数据库 可以利用模块和插件控制输入输出 rsyslog程序管理本地和远程日志 安装软件 根据需求修改配置文 ...
- AI人脸匹对
人脸匹对 技术 调用到百度的AI接口,layui的图片上传,栅格化布局 核心代码 纯py代码运行 # encoding:utf-8 from aip import AipFace import bas ...
- CMDB项目要点总结之中控机
1.基于paramiko对远程主机执行命令操作 秘钥形式 private_key = paramiko.RSAKey.from_private_key_file('c:/Users/用户名/.ssh/ ...
- 2019 GDUT Rating Contest II : Problem C. Rest Stops
题面: C. Rest Stops Input file: standard input Output file: standard output Time limit: 1 second Memory ...
- MySQL按天备份二进制日志
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:guozhen.zhang import MySQLdbimport timeimp ...
- CSS中的块级元素,行内元素,行内块元素
博客转载于:https://blog.csdn.net/swebin/article/details/90405950 块级元素 block 块级元素,该元素呈现块状,所以他有自己的宽度和高度,也就是 ...
- SpEL表达式注入
一.内容简介 Spring Expression Language(简称SpEL)是一种强大的表达式语言,支持在运行时查询和操作对象图.语言语法类似于Unified EL,但提供了额外的功能,特别是方 ...
- Android控件 之 TextClock & AnalogClock(模拟时钟)
TextClock •简介 关于时间的文本显示,Android 提供了 DigitalClock 和 TextClock. DigitalClock是Android第1版本发布,功能很简单,只显示时间 ...