python爬取实习僧招聘信息字体反爬
参考博客:http://www.cnblogs.com/eastonliu/p/9925652.html
实习僧招聘的网站采用了字体反爬,在页面上显示正常,查看源码关键信息乱码,如下图所示:
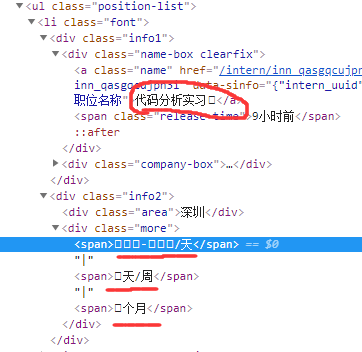
查看网页源码也是看不到关键信息:

查了一下是css3支持自定义字体,实习僧技术人员把一些字体换成了自定义的字体,浏览器上可以显示,后台就看不到了。
1.首先找到这些字体是在哪定义的。
右键查看网页源码,查找font-face,就会看到字体信息(加密的数据太多):

可以看到这些字体源是用了base64加密,用base64库进行解密,把解密后的字体文件保存到shixi.ttf中,下载一个字体软件FontCreator。链接:https://pan.baidu.com/s/1BPRhWYvOs6KFrgNQ4h7m_g 提取码:1fa4
1 def parse_ttf():
2 font_face = " 源码上的font-face"
3 b = base64.b64decode(font_face)
4 with open('shixi.ttf', 'wb') as f:
5 f.write(b)
用软件打开这个字体文件,可以右键-Captions-Codepoints选择排序方式:

可以看到这是网页替换的字体,例如:e588---1,ebbc---5.
2.接下来就是找到这些字体和源码中相应位置字符的对应关系。
ttf文件直接打不开,可以转换成xml文件打开或者用from fontTools.ttLib import TTFont 这个库打开。
1 def font_dict():
2 font = TTFont('shixi.ttf')
3 font.saveXML('shixi.xml')
打开shixi.xml,找到cmap,这里保存了编码和字体的对应关系。

接下来就是获取这种对应关系,code所示的就是网页上的源码形式,但是用getBestCmap()函数获取后又变成十进制的数了,所以需要用hex()函数将10进制整数转换成16进制,以字符串形式表示成原来的行是。
这里有一个坑,第一行的map没有用,如果不删除接下来没办法解析。
1 def font_dict():
2 font = TTFont('shixi.ttf')
3 font.saveXML('shixi.xml')
4 ccmap = font['cmap'].getBestCmap()
5 print("ccmap:\n",ccmap)
6 newmap = {}
7 for key,value in ccmap.items():
8 # value = int(re.search(r'(\d+)', ccmap[key]).group(1)) - 1
9 #转换成十六进制
10 key = hex(key)
11 value = value.replace('uni','')
12 a = 'u'+'0' * (4-len(value))+value
13 newmap[key] = a
14 print("newmap:\n",newmap)
15 #删除第一个没用的元素
16 newmap.pop('0x78')
17 #加上前缀u变成unicode....
18 for i,j in newmap.items():
19 newmap[i] = eval("u" + "\'\\" + j + "\'")
20 print("newmap:\n",newmap)
21
22 new_dict = {}
23 #根据网页上显示的字符样式改变键值对的显示
24 for key, value in newmap.items():
25 key_ = key.replace('0x', '&#x')
26 new_dict[key_] = value
27
28 return new_dict
这样就得到了网页代码和实际字符额对应关系,如下:
'0xe06b': '天', '0xe0ce': '个', '0xe0d2': 'p', '0xe0d4': 'K', '0xe109': 's'
3.替换网页上的编码,提取正确的信息。
下面是全部源码:
1 #coding=utf-8
2 #milo22233060@gmail.com
3 #2018/11/8 17:01
4 import requests
5 import re
6 from lxml import etree
7 import base64
8 import json
9 import pymysql
10 import time
11 from fontTools.ttLib import TTFont
12 def parse_ttf():
13 font_face = ""
14 b = base64.b64decode(font_face)
15 with open('shixi.ttf', 'wb') as f:
16 f.write(b)
17 #处理字体问题,返回字体对应的字典
18 def font_dict():
19 font = TTFont('shixi.ttf')
20 font.saveXML('shixi.xml')
21 ccmap = font['cmap'].getBestCmap()
22 print("ccmap:\n",ccmap)
23 newmap = {}
24 for key,value in ccmap.items():
25 # value = int(re.search(r'(\d+)', ccmap[key]).group(1)) - 1
26 #转换成十六进制
27 key = hex(key)
28 value = value.replace('uni','')
29 a = 'u'+'0' * (4-len(value))+value
30 newmap[key] = a
31 print("newmap:\n",newmap)
32 #删除第一个没用的元素
33 newmap.pop('0x78')
34 #加上前缀u变成unicode....
35 for i,j in newmap.items():
36 newmap[i] = eval("u" + "\'\\" + j + "\'")
37 print("newmap:\n",newmap)
38
39 new_dict = {}
40 #根据网页上显示的字符样式改变键值对的显示
41 for key, value in newmap.items():
42 key_ = key.replace('0x', '&#x')
43 new_dict[key_] = value
44
45 return new_dict
46
47 #开始爬取,替换字体
48 def crawl(url,new_dict):
49 headers = {
50 'User_Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36",
51 }
52 response = requests.get(url, headers=headers)
53 # print(response.text)
54 html = response.text
55 # print(new_dict)
56 #测试这个font-face是不是对的
57
58 for key,value in new_dict.items():
59 if key in html:
60 html = html.replace(key,value)
61 # print('yes')
62 else:
63 pass
64 # print('no')
65 # print(html)
66 html = etree.HTML(html)
67 result = html.xpath("//ul[@class='position-list']//li")
68
69 #获取职位名称,地址,公司名称,薪水,链接
70 result_data = []
71 for element in result:
72 data = {}
73 try:
74 link = 'https://www.shixiseng.com'+element.xpath(".//div[1]//div[1]//a/@href")[0]
75 position_name = element.xpath(".//div[1]//div[1]//a/text()")[0]
76 company_name = element.xpath(".//div[1]//div[2]//a/text()")[0]
77 location = element.xpath(".//div[2]//div[1]/text()")[0]
78 salary = element.xpath(".//div[2]//div[2]//span[1]/text()")[0]
79 week = element.xpath(".//div[2]//div[2]//span[2]/text()")[0]
80 month = element.xpath(".//div[2]//div[2]//span[3]/text()")[0]
81 except:
82 print('wrong!')
83 print(position_name,location,company_name,salary,link,week,month)
84 data['position_name'] = position_name
85 data['company_name'] = company_name
86 data['location'] = location
87 data['salary'] = salary
88 data['week'] = week
89 data['month'] = month
90 data['link'] = link
91 result_data.append(data)
92 print(result_data)
93 return result_data
94 if __name__ == '__main__':
95 url = 'https://www.shixiseng.com/interns?k=Python&p='
96 parse_ttf()
97 data = font_dict()
98 print(data)
99 result = []
100 for i in range(2):
101 result.extend(crawl(url+str(i+1),data))
102 print(result)
font-face会经常变化,这就需要及时更新这个数据。
欢迎指正。
python爬取实习僧招聘信息字体反爬的更多相关文章
- 用python抓取智联招聘信息并存入excel
用python抓取智联招聘信息并存入excel tags:python 智联招聘导出excel 引言:前一阵子是人们俗称的金三银四,跳槽的小朋友很多,我觉得每个人都应该给自己做一下规划,根据自己的进步 ...
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- python之scrapy爬取某集团招聘信息以及招聘详情
1.定义爬取的字段items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See do ...
- python之crawlscrapy爬取某集团招聘信息以及招聘详情
针对这种招聘信息,使用crawlscrapy很适合. 1.settings.py # -*- coding: utf-8 -*- # Scrapy settings for gosuncn proje ...
- node.js 89行爬虫爬取智联招聘信息
写在前面的话, .......写个P,直接上效果图.附上源码地址 github/lonhon ok,正文开始,先列出用到的和require的东西: node.js,这个是必须的 request,然发 ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- python爬虫爬取腾讯招聘信息 (静态爬虫)
环境: windows7,python3.4 代码:(亲测可正常执行) import requests from bs4 import BeautifulSoup from math import c ...
- python之scrapy爬取某集团招聘信息
1.创建工程 scrapy startproject gosuncn 2.创建项目 cd gosuncn scrapy genspider gaoxinxing gosuncn.zhiye.com 3 ...
- Python爬虫入门教程 64-100 反爬教科书级别的网站-汽车之家,字体反爬之二
说说这个网站 汽车之家,反爬神一般的存在,字体反爬的鼻祖网站,这个网站的开发团队,一定擅长前端吧,2019年4月19日开始写这篇博客,不保证这个代码可以存活到月底,希望后来爬虫coder,继续和汽车之 ...
随机推荐
- python 格式化输出详解(占位符:%、format、f表达式)——上篇 理论篇
0 - 占位符介绍 要实现字符串的拼接,使用占位符是的一种高效.常用的方式. 举个例子,下面是不使用占位符的一种写法,直接使用加号拼接字符串 name = "Li hua" age ...
- python爬取豆瓣电影第一页数据and使用with open() as读写文件
# _*_ coding : utf-8 _*_ # @Time : 2021/11/2 9:58 # @Author : 秋泊酱 # @File : 获取豆瓣电影第一页 # @Project : 爬 ...
- linux python2.6.6升级到python2.7
升级 python 2.6.6 系统到 2.7.10 版本 CentOS 6 系统默认 Python 版本是:2.6.6 平时在使用中遇到很多的库要求是 2.7.x 版本的库,比如使用 ConfigP ...
- [hdu7033]Typing Contest
为了避免浮点运算,不妨将$f_{i}$乘上$C=10^{2}$,问题即求$\max_{S\subseteq [1,n]}\frac{\sum_{i\in S}(C^{2}-(\sum_{j ...
- Android系统编程入门系列之硬件交互——多媒体摄像头
多媒体系列硬件 多媒体包括图片.动画.音频.视频,这些多媒体素材的采集(输入)主要依靠摄像头和麦克风等硬件设备转化为基础数据,而他们的播放渲染(输出),则需要依靠具有相关功能的编解码软件.当然随着硬件 ...
- BZOJ 3729 - Gty的游戏(Staircase 博弈+时间轴分块)
题面传送门 介于自己以前既没有写过 Staircase-Nim 的题解,也没写过时间轴分块的题解,所以现在就来写一篇吧(fog 首先考虑最极端的情况,如果图是一条链,并且链的一个端点是 \(1\),那 ...
- Codeforces 848C Goodbye Souvenir(CDQ 分治)
题面传送门 考虑记录每个点的前驱 \(pre_x\),显然答案为 \(\sum\limits_{i=l}^{r} i-pre_i (pre_i \geq l)\) 我们建立一个平面直角坐标系,\(x\ ...
- Codeforces 848D - Shake It!(DP)
Codeforces 题面传送门 & 洛谷题面传送门 hot tea 一道. 首先我们考虑这个奇奇怪怪的最小割有什么等价的表达.不难发现,如果我们选择了 \(S\to T\) 这条边并加入了一 ...
- Codeforces 1461F - Mathematical Expression(分类讨论+找性质+dp)
现场 1 小时 44 分钟过掉此题,祭之 大力分类讨论. 如果 \(|s|=1\),那么显然所有位置都只能填上这个字符,因为你只能这么填. scanf("%d",&n);m ...
- Codeforces 1158F - Density of subarrays(dp,神仙题)
Codeforces 题目传送门 & 洛谷题目传送门 人生中第一道 *3500(显然不是自己独立 AC 的),不过还是祭一下罢 神仙 D1F 首先考虑对于给定的序列 \(a_1,a_2,\do ...