「Python实用秘技01」复杂zip文件的解压
本文完整示例代码及文件已上传至我的
Github仓库https://github.com/CNFeffery/PythonPracticalSkills
这是我的新系列文章「Python实用秘技」的第1期,本系列立足于笔者日常工作中使用Python辅助办公的心得体会,每一期为大家带来一个3分钟即可学会的简单小技巧。
作为系列第1期,我们即将学习的是:复杂zip文件的解压。

废话不多说,直接看问题,使用过Python中的标准库zipfile解压过zip格式压缩包的朋友们,可能遇到过,当压缩文件中的目录或文件名中包含中文等常见unicode字符时,典型如下面的例子:
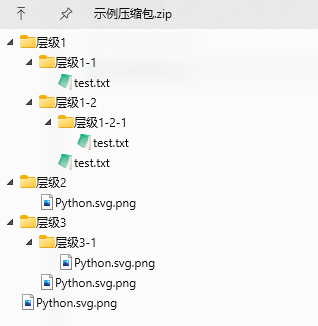
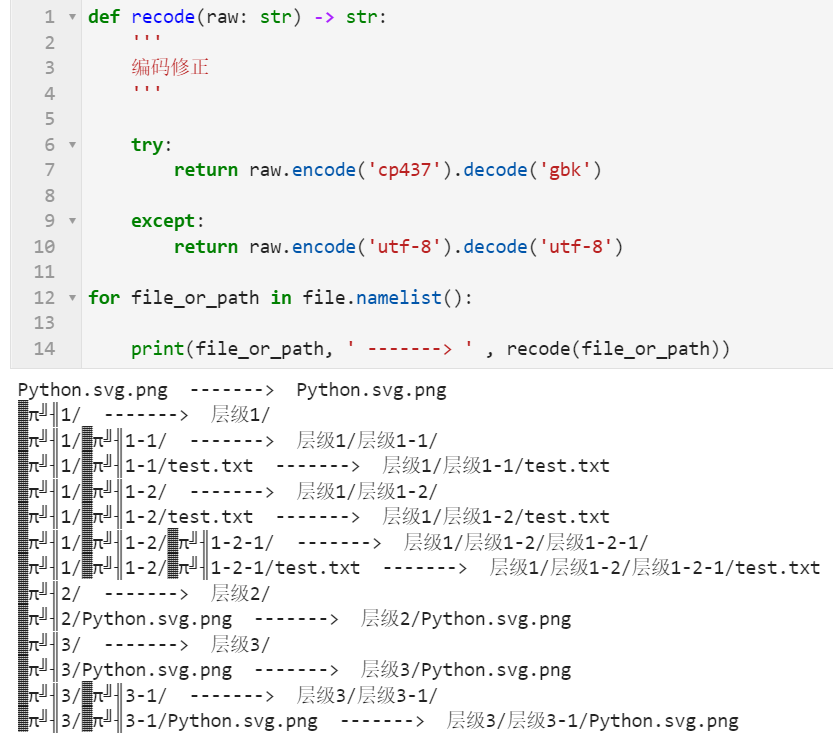
使用zipfile的extract()或extractall()方法直接解压时,产生的解压结果名充斥着乱码,这一点我们通过调用namelist()方法就可以看出来:
from zipfile import ZipFile
# 读入压缩包文件
file = ZipFile('示例压缩包.zip')
# 查看压缩包内目录、文件名称
file.namelist()

这是因为zipfile中针对压缩包内容的编码兼容性差,但我们可以通过下面的函数自行矫正:
def recode(raw: str) -> str:
'''
编码修正
'''
try:
return raw.encode('cp437').decode('gbk')
except:
return raw.encode('utf-8').decode('utf-8')
for file_or_path in file.namelist():
print(file_or_path, ' -------> ' , recode(file_or_path))
解决了文件名乱码的问题后,接下来我们就可以配合shutil与os标准库中的相关功能,实现将指定任意zip压缩包,完好地解压到指定的目录中,代码如下:
def zip_extract_all(src_zip_file: ZipFile, target_path: str) -> None:
# 遍历压缩包内所有内容
for file_or_path in file.namelist():
# 若当前节点是文件夹
if file_or_path.endswith('/'):
try:
# 基于当前文件夹节点创建多层文件夹
os.makedirs(os.path.join(target_path, recode(file_or_path)))
except FileExistsError:
# 若已存在则跳过创建过程
pass
# 否则视作文件进行写出
else:
# 利用shutil.copyfileobj,从压缩包io流中提取目标文件内容写出到目标路径
with open(os.path.join(target_path, recode(file_or_path)), 'wb') as z:
# 这里基于Zipfile.open()提取文件内容时需要使用原始的乱码文件名
shutil.copyfileobj(src_zip_file.open(file_or_path), z)
# 向已存在的指定文件夹完整解压当前读入的zip文件
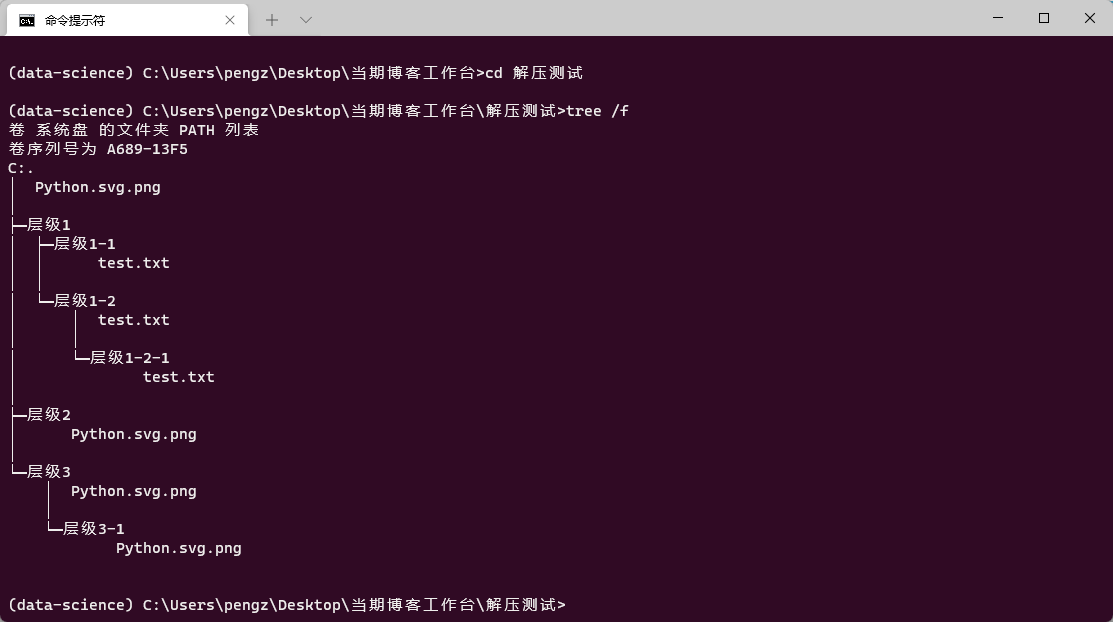
zip_extract_all(file, '解压测试')
可以看到,效果完美:
本期分享结束,咱们下回见~
「Python实用秘技01」复杂zip文件的解压的更多相关文章
- 「Python实用秘技04」为pdf文件批量添加文字水印
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第4期 ...
- 「Python实用秘技02」给Python函数定“闹钟”
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第2期 ...
- 「Python实用秘技03」导出项目的极简环境依赖
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第3期 ...
- 「Python实用秘技05」在Python中妙用短路机制
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第5期 ...
- 「Python实用秘技06」逐行监听Python程序的内存消耗
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第6期 ...
- 「Python实用秘技07」pandas中鲜为人知的隐藏排序技巧
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第7期 ...
- 「Python实用秘技08」一行代码解析地址信息
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第8期 ...
- 「Python实用秘技09」更好用的函数运算缓存
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第9期 ...
- 「Python实用秘技10」深度比较Python对象间差异
本文完整示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/PythonPracticalSkills 这是我的系列文章「Python实用秘技」的第10 ...
随机推荐
- FZU ICPC 2020 寒假训练 5 —— 排序
P1177 [模板]快速排序 题目描述 利用快速排序算法将读入的 N 个数从小到大排序后输出.快速排序是信息学竞赛的必备算法之一.对于快速排序不是很了解的同学可以自行上网查询相关资料,掌握后独立完成. ...
- 菜鸡的Java笔记 第十一 - java 封装性
1.1封装的基础实现. 封装是把过程和数据包围起来,对数据的访问只能通过已定义的接口.面向对象计算始于这个基本概念,即现实世界可以被描绘成一系列完全自治.封装的对象,这些对象通过一个受保 ...
- 什么。你还没有搞懂Spring事务增强器 ,一篇文章让你彻底搞懂Spring事务,虽然很长但是干货满满
上一篇文章主要讲解了事务的Advisor是如何注册进Spring容器的,也讲解了Spring是如何将有配置事务的类配置上事务的,也讲解了Advisor,pointcut验证流程:但是还未提到的那个Ad ...
- [loj3526]修改DNA
如果$a[x..y]$和$b[x..y]$的某种字符数量不同,显然无解 考虑一个$[x,y]$的排列$p[x..y]$,使得$\forall x\le i\le y,a_{i}=b_{p_{i}}$, ...
- [atARC121D]1 or 2
对于大小为1的集合,我们可以在其中加入0 因此,枚举0的个数,那么问题即可以看作要求每一个集合大小为2 (特别的,我们允许存在$\{0,0\}$,因为这样删除这两个0显然只会减小极差) 显然此时贪心将 ...
- banner.txt
Spring Boot Version: ${spring-boot.version} __----~~~~~~~~~~~------___ . . ~~//====...... __--~ ~~ - ...
- Codeforces 891E - Lust(生成函数)
Codeforces 题面传送门 & 洛谷题面传送门 NaCly_Fish:<简单>的生成函数题 然鹅我连第一步都没 observe 出来 首先注意到如果我们按题意模拟那肯定是不方 ...
- Atcoder Grand Contest 020 E - Encoding Subsets(记忆化搜索+复杂度分析)
Atcoder 题面传送门 & 洛谷题面传送门 首先先考虑如果没有什么子集的限制怎样计算方案数.明显就是一个区间 \(dp\),这个恰好一年前就做过类似的题目了.我们设 \(f_{l,r}\) ...
- LeeCode刷题笔记
(本来想在LeeCode题目页面上做注释的,结果没找到位置,只好来这里了) 字符串部分: 14.最长公共前缀:编写一个函数来查找字符串数组中的最长公共前缀. 示例 1: 输入: ["flow ...
- 毕业设计之zabbix集合
lnmp环境请查看https://www.cnblogs.com/betterquan/p/12285956.html 但是!!!注意php的编译: https://www.zabbix.com/do ...