SVM实现邮件分类
首先学习一下svm分类的使用。
主要有以下步骤:
- Loading and Visualizing Dataj
- Training Linear SVM
- Implementing Gaussian Kernel
- Training SVM with RBF Kernel
- 选择最优的C, sigma参数
- 画出边界线
线性keneral实现
C = 1;
model = svmTrain(X, y, C, @linearKernel, 1e-3, 20);
visualizeBoundaryLinear(X, y, model);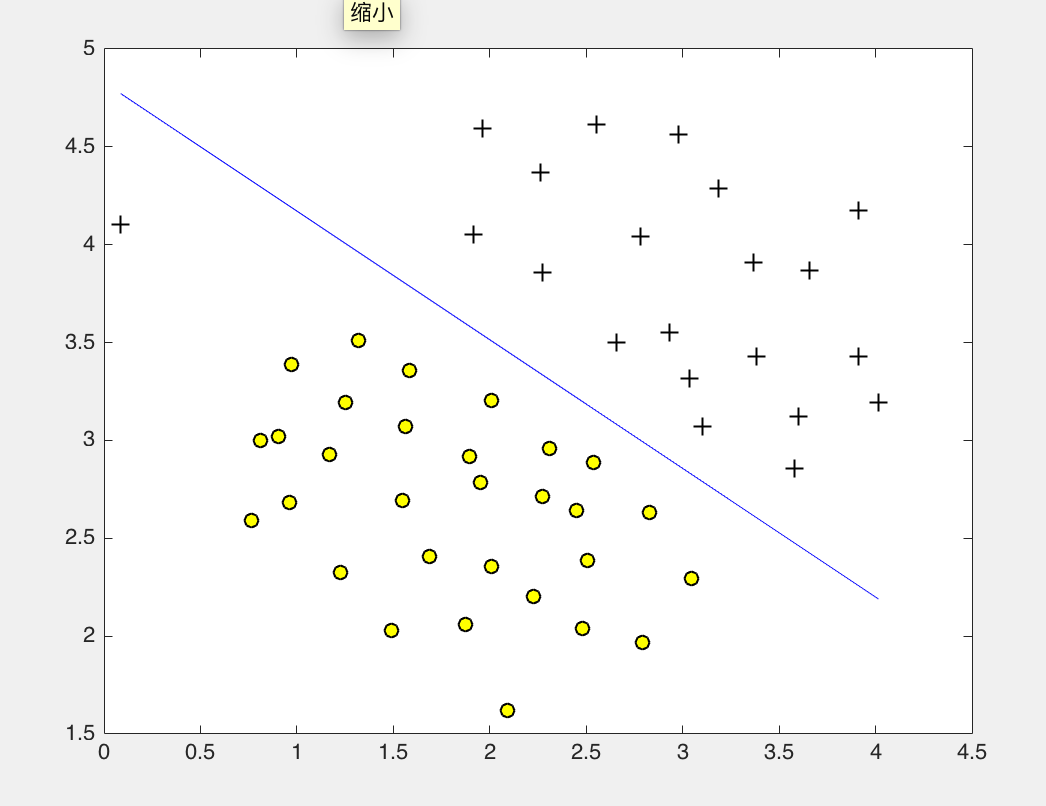
高斯keneral实现
function sim = gaussianKernel(x1, x2, sigma)
x1 = x1(:); x2 = x2(:);
sim = 0;
sim = exp( - (x1-x2)'* (x1-x2) / (2 * sigma *sigma ) );
end
load('ex6data2.mat');
% SVM Parameters
C = 1; sigma = 0.1;
% We set the tolerance and max_passes lower here so that the code will run
% faster. However, in practice, you will want to run the training to
% convergence.
model= svmTrain(X, y, C, @(x1, x2) gaussianKernel(x1, x2, sigma));
visualizeBoundary(X, y, model);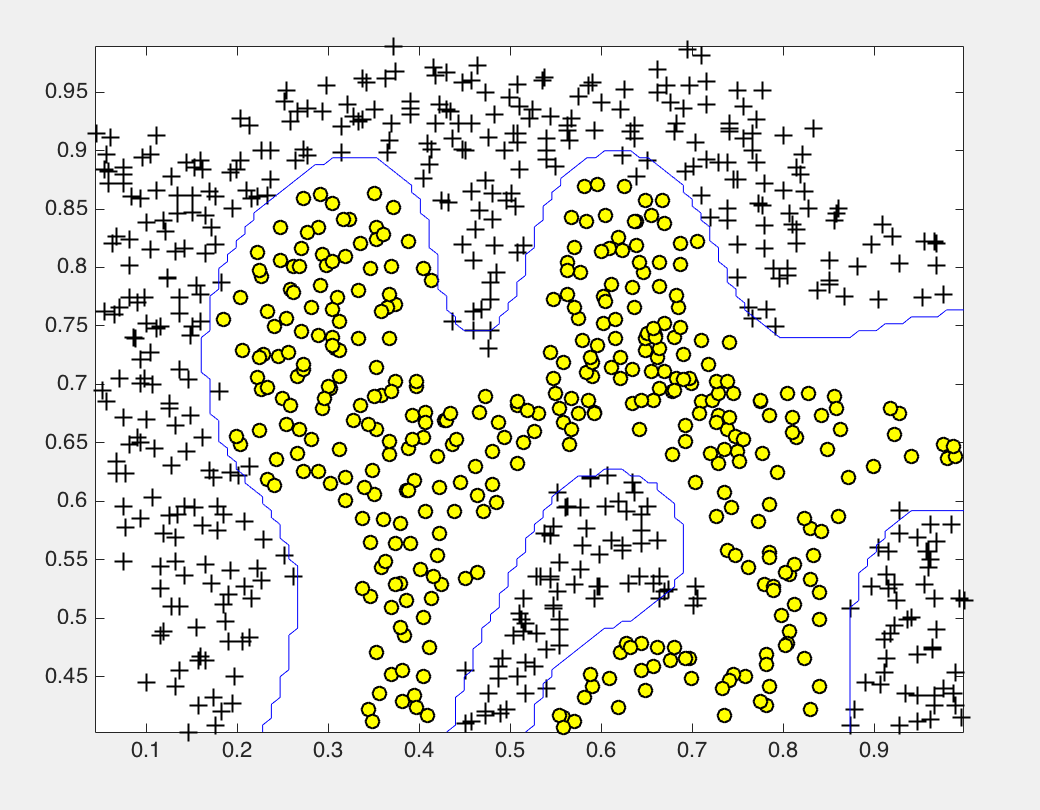
选择合适的参数
function [C, sigma] = dataset3Params(X, y, Xval, yval)
C = 1;
sigma = 0.3;
C_vec = [0.01 0.03 0.1 0.3 1 3 10 30]';
sigma_vec = [0.01 0.03 0.1 0.3 1 3 10 30]';
error_val = zeros(length(C_vec),length(sigma_vec));
error_train = zeros(length(C_vec),length(sigma_vec));
for i = 1:length(C_vec)
for j = 1:length(sigma_vec)
model= svmTrain(X, y, C_vec(i), @(x1, x2) gaussianKernel(x1, x2, sigma_vec(j)));
predictions = svmPredict(model, Xval);
error_val(i,j) = mean(double(predictions ~= yval));
end
end
% figure
% error_val
% surf(C_vec,sigma_vec,error_val) % 画出三维图找最低点
[minval,ind] = min(error_val(:)); % 0.03
[I,J] = ind2sub([size(error_val,1) size(error_val,2)],ind);
C = C_vec(I) % 1
sigma = sigma_vec(J) % 0.100
% [I,J]=find(error_val == min(error_val(:)) ); % 另一种方式找最小元素位子
% C = C_vec(I) % 1
% sigma = sigma_vec(J) % 0.100
end
[C, sigma] = dataset3Params(X, y, Xval, yval);
% Train the SVM
model= svmTrain(X, y, C, @(x1, x2) gaussianKernel(x1, x2, sigma));
visualizeBoundary(X, y, model);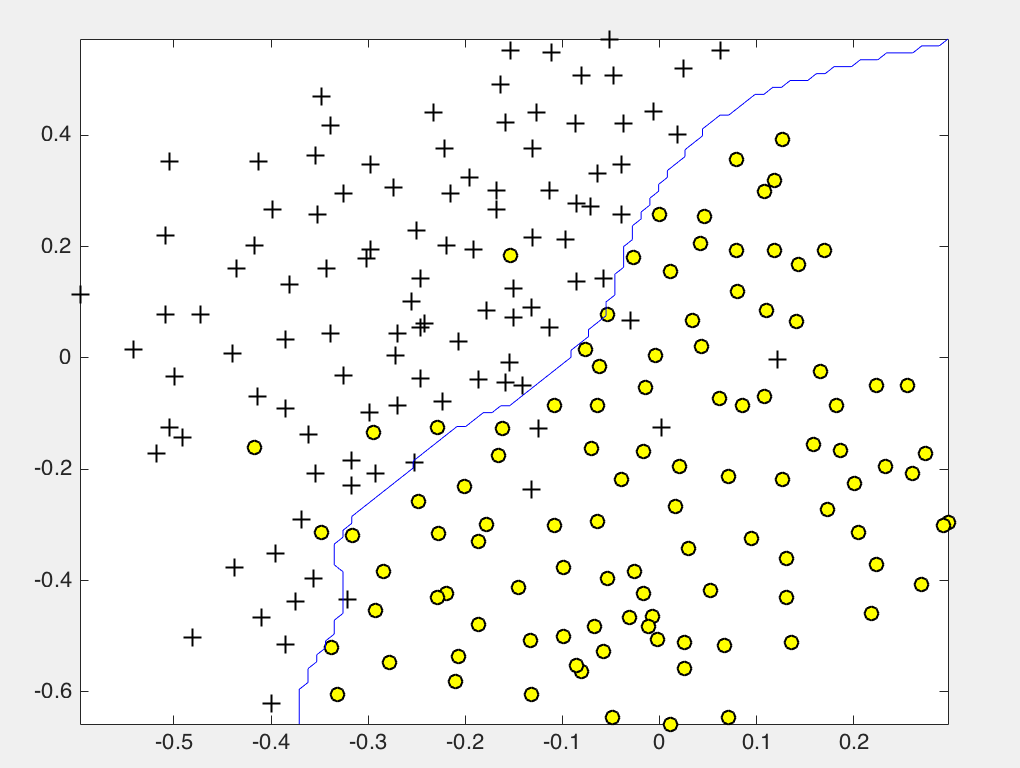
邮件分类
主要步骤如下:
- 邮件数据归一化处理
- 特征提取
- Train Linear SVM for Spam Classification
- Test Spam Classification
- Top Predictors of Spam
- 测试自己的email
归一化处理
In processEmail.m, we have implemented the following email prepro- cessing and normalization steps:
- Lower-casing: The entire email is converted into lower case, so that captialization is ignored (e.g., IndIcaTE is treated the same as Indicate).
- Stripping HTML: All HTML tags are removed from the emails. Many emails often come with HTML formatting; we remove all the HTML tags, so that only the content remains.
- Normalizing URLs: All URLs are replaced with the text “httpaddr”.
- Normalizing Email Addresses: All email addresses are replaced
with the text “emailaddr”. - Normalizing Numbers: All numbers are replaced with the text
“number”. - Normalizing Dollars: All dollar signs ($) are replaced with the text
“dollar”. - Word Stemming: Words are reduced to their stemmed form. For ex- ample, “discount”, “discounts”, “discounted” and “discounting” are all replaced with “discount”. Sometimes, the Stemmer actually strips off additional characters from the end, so “include”, “includes”, “included”, and “including” are all replaced with “includ”.
- Removal of non-words: Non-words and punctuation have been re- moved. All white spaces (tabs, newlines, spaces) have all been trimmed to a single space character.
处理之后效果如下:

Vocabulary List
我们取垃圾邮件中最常见的单词放入单词表中。
Our vocabulary list was selected by choosing all words which occur at least a 100 times in the spam corpus, resulting in a list of 1899 words. In practice, a vocabulary list with about 10,000 to 50,000 words is often used.
将我们邮件中有的单词在单词表中的id存储在word_indices中
for i=1:length(vocabList)
if( strcmp(vocabList{i}, str) )
word_indices = [word_indices;i];
end
endExtracting Features from Emails
然后查找我们的邮件中的单词在单词表中的位置,有则置1,无则跳过。
You should look up the word in the vocabulary list vocabList and find if the word exists in the vocabulary list. If the word exists, you should add the index of the word into the word indices variable. If the word does not exist, and is therefore not in the vocabulary, you can skip the word.
function x = emailFeatures(word_indices)
% Total number of words in the dictionary
n = 1899;
% You need to return the following variables correctly.
x = zeros(n, 1);
x(word_indices) = 1;
endTraining SVM for Spam Classification
load('spamTrain.mat');
fprintf('\nTraining Linear SVM (Spam Classification)\n')
fprintf('(this may take 1 to 2 minutes) ...\n')
C = 0.1;
model = svmTrain(X, y, C, @linearKernel);
p = svmPredict(model, X);
fprintf('Training Accuracy: %f\n', mean(double(p == y)) * 100);
%% =================== Part 4: Test Spam Classification ================
load('spamTest.mat');
fprintf('\nEvaluating the trained Linear SVM on a test set ...\n')
p = svmPredict(model, Xtest);
fprintf('Test Accuracy: %f\n', mean(double(p == ytest)) * 100);After loading the dataset, ex6 spam.m will proceed to train a SVM to classify between spam (y = 1) and non-spam (y = 0) emails. Once the training completes, you should see that the classifier gets a training accuracy of about 99.8% and a test accuracy of about 98.5%.
Top Predictors for Spam
找出最易被判断为垃圾邮件的单词。
[weight, idx] = sort(model.w, 'descend');
vocabList = getVocabList();
fprintf('\nTop predictors of spam: \n');
for i = 1:15
fprintf(' %-15s (%f) \n', vocabList{idx(i)}, weight(i));
end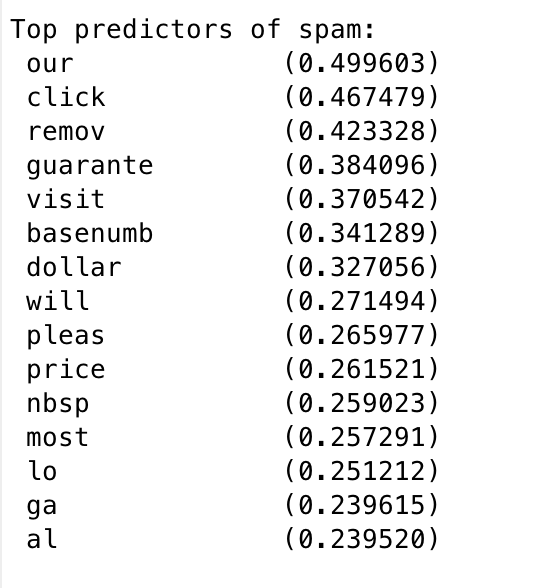
Try your own emails
filename = 'spamSample1.txt';
% Read and predict
file_contents = readFile(filename);
word_indices = processEmail(file_contents);
x = emailFeatures(word_indices);
p = svmPredict(model, x);
fprintf('\nProcessed %s\n\nSpam Classification: %d\n', filename, p);
fprintf('(1 indicates spam, 0 indicates not spam)\n\n');可以看出我们的邮件判断准确率大概在98%左右。
SVM实现邮件分类的更多相关文章
- 基于SKLearn的SVM模型垃圾邮件分类——代码实现及优化
一. 前言 由于最近有一个邮件分类的工作需要完成,研究了一下基于SVM的垃圾邮件分类模型.参照这位作者的思路(https://blog.csdn.net/qq_40186809/article/det ...
- Bert模型实现垃圾邮件分类
近日,对近些年在NLP领域很火的BERT模型进行了学习,并进行实践.今天在这里做一下笔记. 本篇博客包含下列内容: BERT模型简介 概览 BERT模型结构 BERT项目学习及代码走读 项目基本特性介 ...
- Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理
Atitit 贝叶斯算法的原理以及垃圾邮件分类的原理 1.1. 最开始的垃圾邮件判断方法,使用contain包含判断,只能一个关键词,而且100%概率判断1 1.2. 元件部件串联定律1 1.3. 垃 ...
- CNN实现垃圾邮件分类(行大小不一致要补全)
以下是利用卷积神经网络对某一个句子的处理结构图 我们从上图可知,将一句话转化成一个矩阵.我们看到该句话有6个单词和一个标点符号,所以我们可以将该矩阵设置为7行,对于列的话每个单词可以用什么样的数值表示 ...
- Python之机器学习-朴素贝叶斯(垃圾邮件分类)
目录 朴素贝叶斯(垃圾邮件分类) 邮箱训练集下载地址 模块导入 文本预处理 遍历邮件 训练模型 测试模型 朴素贝叶斯(垃圾邮件分类) 邮箱训练集下载地址 邮箱训练集可以加我微信:nickchen121 ...
- 利用朴素贝叶斯(Navie Bayes)进行垃圾邮件分类
贝叶斯公式描写叙述的是一组条件概率之间相互转化的关系. 在机器学习中.贝叶斯公式能够应用在分类问题上. 这篇文章是基于自己的学习所整理.并利用一个垃圾邮件分类的样例来加深对于理论的理解. 这里我们来解 ...
- 垃圾邮件分类实战(SVM)
1. 数据集说明 trec06c是一个公开的垃圾邮件语料库,由国际文本检索会议提供,分为英文数据集(trec06p)和中文数据集(trec06c),其中所含的邮件均来源于真实邮件保留了邮件的原有格式和 ...
- 8.SVM用于多分类
从前面SVM学习中可以看出来,SVM是一种典型的两类分类器.而现实中要解决的问题,往往是多类的问题.如何由两类分类器得到多类分类器,就是一个值得研究的问题. 以文本分类为例,现成的方法有很多,其中一劳 ...
- SVM实现多分类的三种方案
SVM本身是一个二值分类器 SVM算法最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器. 目前,构造SVM多类分类器的方法主要有两类 (1)直接法,直接在目标函数上进行修改,将 ...
随机推荐
- Java--笔记(7)
61.几种常见排序法的比较 排序法 平均时间 最差情形 稳定度 额外空间 冒泡 O(n2) O(n2) 稳定 O(1) 交换 O(n2) O(n2) 不稳定 O(1) 选择 O ...
- sendEmail
原文:http://blog.chinaunix.net/uid-16844903-id-308853.html 功能: 发邮件的客户端 官网地址: http://caspian.dotconf.ne ...
- mac下需要安装旧 Java SE 6 才能打开程序解决办法
今天我在mac系统下面安装myeclipse2014(myeclipse-pro-2014-GA-offline-installer-macosx.dmg)的时候,发现显示错误: 您需要安装旧 Jav ...
- LinuxMint 18 编译cm13.0 笔记
1.安装依赖文件 sudo apt--dev libesd0-dev git-core gnupg flex bison gperf build-essential zip curl zlib1g-d ...
- SpringMVC常用注解的用法
1. @PathVariable 当使用@RequestMapping URI template 样式映射时, 即 someUrl/{paramId}, 这时的paramId可通过 @Pathvari ...
- cxf 调用 webservice服务时传递 服务器验证需要的用户名密码
cxf通过wsdl2java生成客户端调用webservice时,如果服务器端需要通过用户名和密码验证,则客户端必须传递验证所必须的用户名和密码,刚开始想通过url传递用户名和密码,于是在wsdl文件 ...
- 机器学习中的相似性度量(Similarity Measurement)
机器学习中的相似性度量(Similarity Measurement) 在做分类时常常需要估算不同样本之间的相似性度量(Similarity Measurement),这时通常采用的方法就是计算样本间 ...
- Bash 4.4 中新增的 ${parameter@operator} 语法
Bash 4.4 中新增了一种 ${...} 语法,长这样:${parameter@operator}.根据不同的 operator,它展开后的值可能是 parameter 这个参数的值经过某种转换后 ...
- 关于 Word Splitting 和 IFS 的三个细节
在 Bash manual 里叫 Word Splitting,在 Posix 规范里叫 Field Splitting,这两者指的是同一个东西,我把它翻译成“分词”,下面我就说三点很多人都忽略掉(或 ...
- php5 数据类型
一.PHP主要有一下几种数据类型 String(字符串), Integer(整型), Float(浮点型), Boolean(布尔型), Array(数组), Object(对象), NULL(空值) ...