Django1.0和2.0中的rest_framework的序列化组件之超链接字段的处理
大家看到这个标题是不是有点懵逼,其实我就是想要一个这样的效果
比如我get一条书籍的数据,在一对多的字段中我们显示一个url,看起来是不是很绚!
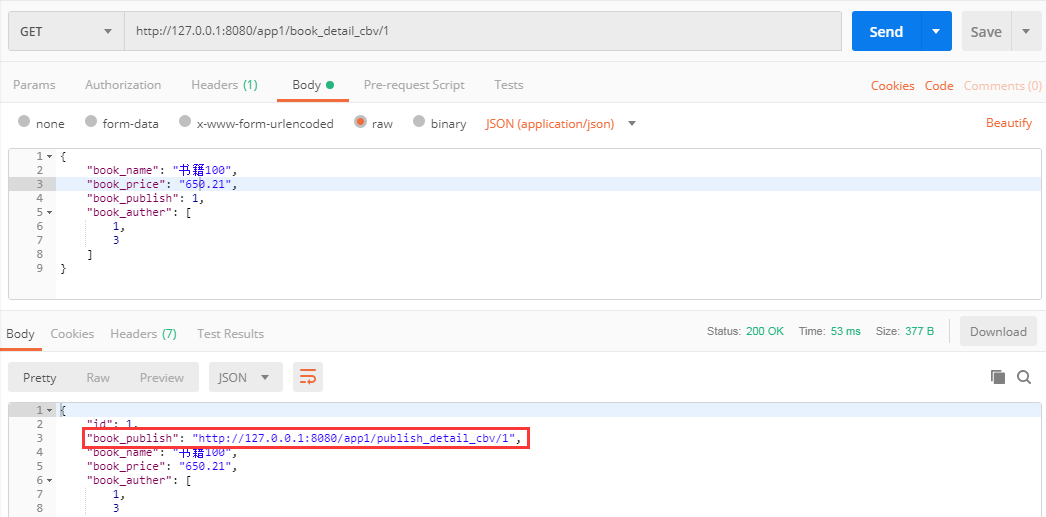
下面我们就来实现这么一个东西
首先我们一对多字段中的一表是 出版社表,因为我们这里要显示某个出版社的url,所以我们首先必须要为出版社的设计一个url
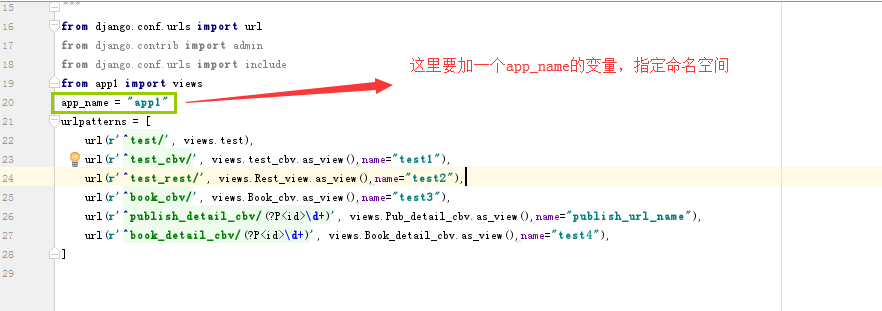
"""
from django.conf.urls import url
from django.contrib import admin
from django.conf.urls import include
from app1 import views
urlpatterns = [
url(r'^test/', views.test),
url(r'^test_cbv/', views.test_cbv.as_view(),name="test1"),
url(r'^test_rest/', views.Rest_view.as_view(),name="test2"),
url(r'^book_cbv/', views.Book_cbv.as_view(),name="test3"),
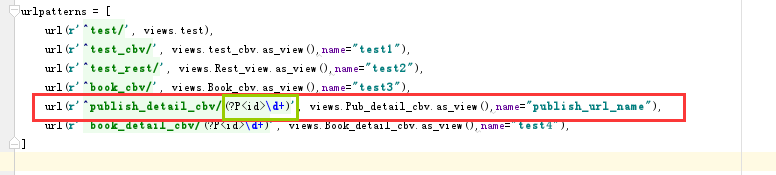
url(r'^publish_detail_cbv/(?P<id>\d+)', views.Pub_detail_cbv.as_view(),name="publish_url_name"),
url(r'^book_detail_cbv/(?P<id>\d+)', views.Book_detail_cbv.as_view(),name="test4"),
]
就是这样的一条

然后我们为出版社设计modelserializer类,所有的字段都使用默认的形式
class pubmodelserializer(serializers.ModelSerializer):
class Meta:
model = models.Publish
fields = "__all__"
然后我们写cbv中的c,也就是视图类
class Pub_detail_cbv(APIView):
def get(self,request,id):
obj = models.Publish.objects.filter(id=id).first() # bs = pubmodelserializer(obj,many=False,context={'request': request})
bs = pubmodelserializer(obj, many=False)
return Response(bs.data) def put(self,request,id):
obj = models.Publish.objects.filter(id=id)
bs = pubmodelserializer(obj,data=request.data)
if bs.is_valid():
bs.save() return Response(bs.data)
else:
return Response(bs.errors)
这样,基本框架就完成了,我们开始来实现超链接
首先要为每条url设计别名
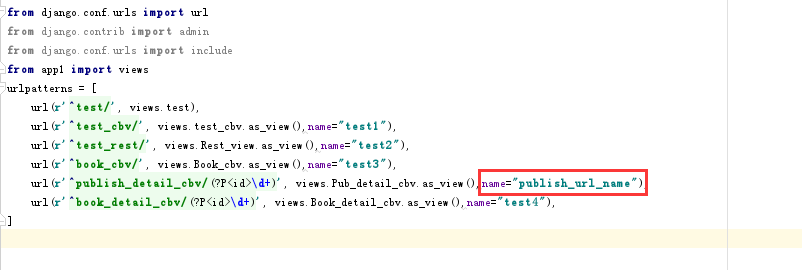
因为我们要对书籍表中的某个字段做超链接处理,所以需要到书籍表的modelserializer类中为超链接字段做特殊的处理
超链接字段使用使用HyperLinkedIdentityField这个类

这个必须要有3个参数,后面会具体的分析
class bookmodelserializer(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = "__all__" book_publish = serializers.HyperlinkedIdentityField(
view_name="publish_url_name",
lookup_field="book_publish_id",
lookup_url_kwarg="id" )
就是我截图框红的这里,下面我们来具体解释下
view_name就是这个字段我们想显示的url的别名
lookup_field字段是一个我们自定义的值,因为我们这里的类是对model对象做序列化处理,所以每个model对象都一个序列化的实例,而这个字段就是这个实例的出版社的id
lookup_url_kwarg字段就是我们的url参数,比如我们这里写的是id,那么lookup_filed这个参数对应的值就会赋值给url中命名变量为id这个变量
这里我们在看下url,因为我们的url中这里要显示的id,所以我们在lookup_fileld就要获取对应的出版社的id,所以这里大家是否清楚了,lookup_fileld要获取什么值,完全取决于我们在url中变量想要什么值;这里为什么还要指定url中的变量的名称呢?因为url中的变量可不止一个,所以必须要指定变量的名称;这里不能使用位置参数,必须使用命名参数

下面我们通过postman发送一个get请求测试一下
发现会报错

这个报错要这样解决
在视图类中序列化一个modelserializer对象的时候要这么写,其实这也是一个固定的写法,在所以实例化model对象或者queryset中均这样写就好了
class Book_detail_cbv(APIView):
def get(self,request,id):
obj = models.Book.objects.filter(id=id).first() bs = bookmodelserializer(obj,many=False,context={'request': request})
# bs = bookmodelserializer(obj, many=False,)
return Response(bs.data)

然后我们在测试一下
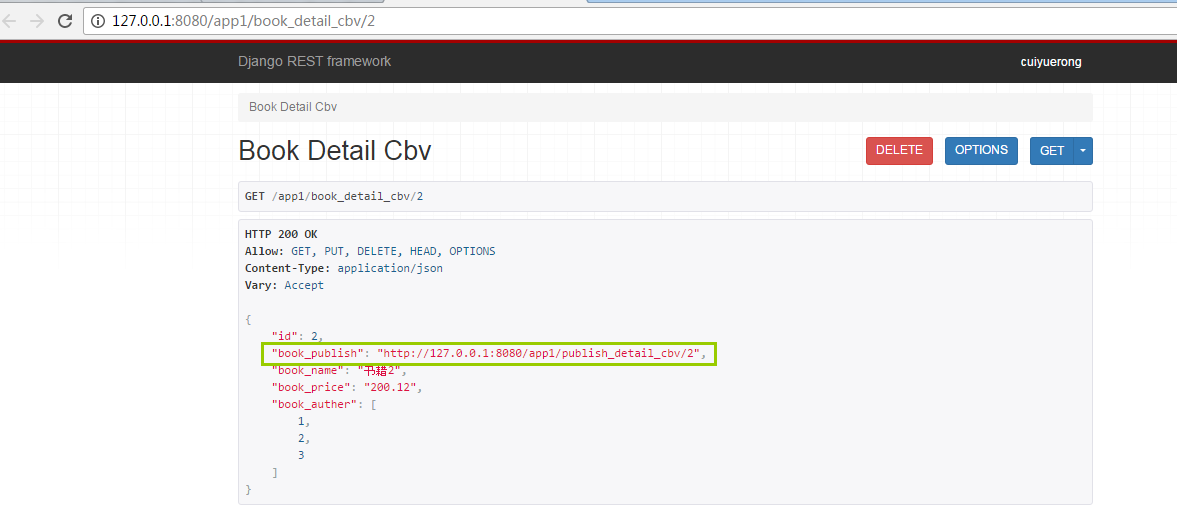
上面是django1.0版本的处理
===============================================================================================================
在djaong2.0中,稍微有一点不同,就是django2.0中对于二级路由的命令别名和django1.0有些改动,这里稍微做一下回忆
首先在工程的url文件中需要按照下面的格式来写

然后在对应app的url中要这么写
最后在超链接类中view_name要这样指定url的别名

其他均和在django1.0中保持一致
附上在django2.0中的所有的代码
序列化处理的代码
from rest_framework import serializers
from app1 import models
from rest_framework.views import APIView
from rest_framework.response import Response
from django.urls import reverse
class bookmodelserializers(serializers.ModelSerializer):
class Meta:
model = models.Book
fields = "__all__"
#
# book_publish = serializers.CharField(source="book_publish.publish_name")
book_publish = serializers.HyperlinkedIdentityField(
view_name= "app1:pub_detail",
lookup_field="book_publish_id",
lookup_url_kwarg="pid"
) def create(self, validated_data):
print("validated_data",validated_data,"==============================") class pubmodelserializers(serializers.ModelSerializer):
class Meta:
model = models.Publish
fields = "__all__"
视图类的代码
from django.shortcuts import render
from django.shortcuts import HttpResponse
from django.shortcuts import redirect
from django import views # Create your views here. class Test(views.View):
def get(self,request):
print(request,type(request))
return HttpResponse("ok") def post(self):
pass from rest_framework import serializers
from app1 import models
from rest_framework.views import APIView
from rest_framework.response import Response from app1.serializer import * class Book_modelserializer_cbv(APIView):
def get(self,request): queryset_list = models.Book.objects.all()
ret = bookmodelserializers(queryset_list,many=True)
print(dir(ret),type(ret))
return Response(ret.data) def post(self,request): ret = bookmodelserializers(data=request.data)
print("request.data",request.data,"==============================")
if ret.is_valid():
ret.save()
return Response(ret.data)
else:
return Response(ret.errors) class Book_Detail_modelserializer_cbv(APIView):
def get(self,request,bid):
obj = models.Book.objects.filter(id=bid).first() ret = bookmodelserializers(obj,many=False,context={'request': request})
return Response(ret.data) def put(self,request,bid):
obj = models.Book.objects.get(id=bid)
bs = bookmodelserializers(obj,data=request.data)
if bs.is_valid():
bs.save()
return Response(bs.data)
else:
return Response(bs.errors) def delete(self,request,bid):
models.Book.objects.get(id=bid).delete()
return HttpResponse("删除成功") from django.urls import reverse class Pub_Detail_modelserializer_cbv(APIView):
def get(self,request,pid):
obj = models.Publish.objects.filter(id=pid).first() ret = pubmodelserializers(obj,many=False,context={'request': request})
s = reverse("app1:pub_detail",kwargs={"pid":int(pid)}) return Response(ret.data) def put(self,request,pid):
obj = models.Publish.objects.get(id=pid)
bs = pubmodelserializers(obj,data=request.data,)
if bs.is_valid():
bs.save()
return Response(bs.data)
else:
return Response(bs.errors) def delete(self,request,pid):
models.Publish.objects.get(id=pid).delete()
return HttpResponse("删除成功")
Django1.0和2.0中的rest_framework的序列化组件之超链接字段的处理的更多相关文章
- rest_framework之序列化组件
什么是rest_framework序列化? 在写前后端不分离的项目时: 我们有form组件帮我们去做数据校验 我们有模板语法,从数据库取出的queryset对象不需要人为去转格式 当我们写前后端分离项 ...
- Django的rest_framework的序列化组件之序列化多表字段的方法
首先,因为我们安装了restframework,所以我们需要在django的settings中引入restframework INSTALLED_APPS = [ 'django.contrib.ad ...
- django rest_framework Serializers 序列化组件
为什么要用序列化组件 当我们做前后端分离的项目~~我们前后端交互一般都选择JSON数据格式,JSON是一个轻量级的数据交互格式. 那么我们给前端数据的时候都要转成json格式,那就需要对我们从数据库拿 ...
- Django的rest_framework的序列化组件之serializers.ModelSerializer介绍
这里的介绍的serializers.ModelSerializer就和我们之前学习的modelform一样 serializers.ModelSerializer如下几个功能 1.序列化queryse ...
- DRF 序列化组件 模型层中参数补充
一. DRF序列化 django自带有序列化组件,但是相比rest_framework的序列化较差,所以这就不提django自带的序列化组件了. 首先rest_framework的序列化组件使用同fr ...
- vc6.0运用mysql数据库中的编码所导致的乱码问题(接收和输出的编码必须要一致)
[编译中遇见的问题] ①在用vc 6.0去调用MySQL中的数据时,出现中文乱码 ②不明白mysql中的码制 [开始解决问题] ①打开mysql控制台 ...
- OpenGL2.0及以上版本中glm,glut,glew,glfw,mesa等部件的关系
OpenGL2.0及以上版本中gl,glut,glew,glfw,mesa等部件的关系 一.OpenGL OpenGL函数库相关的API有核心库(gl),实用库(glu),辅助库(aux).实用工具库 ...
- android4.0浏览器在eclipse中编译的步骤
工程源码: 注意: 如果下载已经修过的源码,只要进行3.4.8步骤就应该可以了. eclipse版本:adt-bundle-windows (Android Developer Tools Build ...
- 从0,1,2...n中统计0,1,2...9各出现了多少次【SWUN1597】
题目就是说给你一个N.计算一下从0,1,2,3,4,5,,,,,,n-1,n中计算出0,1,2,3,,,,7,8,9分别出现了多少次... #include<cstdio> #includ ...
随机推荐
- MySQL主从同步机制及同步中的问题处理
http://www.drupal001.com/2012/03/mysql-master-slave-troubles/ http://www.jb51.net/article/33052.htm
- List去重问题引出来的hashCode和equals方法
一.List 里面是基本类型的去重问题 import java.util.ArrayList; import java.util.HashSet; import java.util.List; imp ...
- Block 语法
Block,代码块,^符号是block的语法标记. 比如说,一个block的参数列表是一个UIView,返回值是个CGFloat,block名称是testBlock 可以定义为 CGFloat (^ ...
- css:关于position和float
在CSS中,我们是通过定位属性position来进行定位的,具体它有如下几个属性值.常见的属性有如下几个: absolute 生成绝对定位的元素,相对于static定位以外的第一个父元素进行定位.元 ...
- 关于maven中的快照版本(snapshot)与正式版本(release)解析。
Maven中建立的依赖管理方式基本已成为Java语言依赖管理的事实标准,Maven的替代者Gradle也基本沿用了Maven的依赖管理机制.在Maven依赖管理中,唯一标识一个依赖项是由该依赖项的三个 ...
- ReactiveX 学习笔记(19)使用 RxSwift + RxCocoa 进行 GUI 编程
课题 程序界面由3个文本编辑框和1个文本标签组成. 要求文本标签实时显示3个文本编辑框所输入的数字之和. 文本编辑框输入的不是合法数字时,将其值视为0. 3个文本编辑框的初值分别为1,2,3. 创建工 ...
- List of numerical libraries,Top Numerical Libraries For C#
Top Numerical Libraries For C# AlgLib (http://alglib.net) ALGLIB is a numerical analysis and data pr ...
- WinForm textbox 全选
原地址:忘了 textBox1.KeyPress += anyTextBox_KeyPress; private void anyTextBox_KeyPress(object sender, Sys ...
- Applese走迷宫-bfs
链接:https://ac.nowcoder.com/acm/contest/330/C来源:牛客网 题目描述 精通程序设计的 Applese 双写了一个游戏. 在这个游戏中,它被困在了一个 n×mn ...
- 指向字符串的指针和char类型的数组
指针数组的效率比二维字符数组的效率高 指针数组不能修改字符串字面量,而二维字符数组中的内容可以更改