python re模块和collections

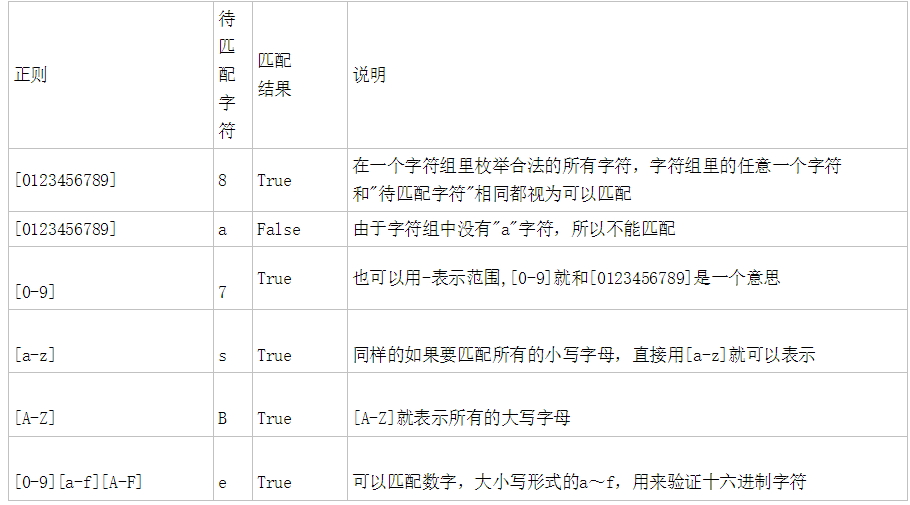

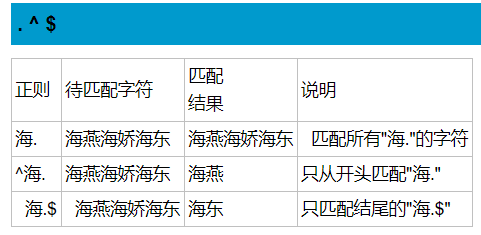

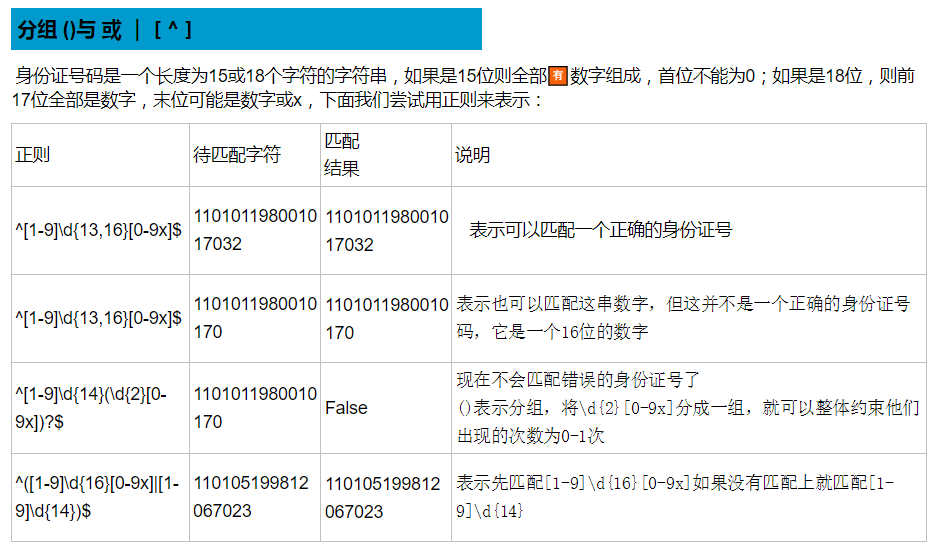


re模块下的常用方法
import re
ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : ['a', 'a']
ret = re.search('a', 'eva egon yuan').group()
print(ret) #结果 : 'a'
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以
# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
ret = re.match('a', 'abc').group() # 同search,不过尽在字符串开始处进行匹配
print(ret)
#结果 : 'a'
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割
print(ret) # ['', '', 'cd']
ret = re.sub('\d', 'H', 'eva3egon4yuan4', 1)#将数字替换成'H',参数1表示只替换1个
print(ret) #evaHegon4yuan4
ret = re.subn('\d', 'H', 'eva3egon4yuan4')#将数字替换成'H',返回元组(替换的结果,替换了多少次)
print(ret)
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123
import re
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
import requests import re
import json def getPage(url): response=requests.get(url)
return response.text def parsePage(s): com=re.compile('<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',re.S) ret=com.finditer(s)
for i in ret:
yield {
"id":i.group("id"),
"title":i.group("title"),
"rating_num":i.group("rating_num"),
"comment_num":i.group("comment_num"),
} def main(num): url='https://movie.douban.com/top250?start=%s&filter='%num
response_html=getPage(url)
ret=parsePage(response_html)
print(ret)
f=open("move_info7","a",encoding="utf8") for obj in ret:
print(obj)
data=json.dumps(obj,ensure_ascii=False)
f.write(data+"\n") if __name__ == '__main__':
count=0
for i in range(10):
main(count)
count+=25
爬虫练习
collections模块
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
>>> from collections import namedtuple
>>> Point = namedtuple('Point', ['x', 'y'])
>>> p = Point(1, 2)
>>> p.x
1
>>> p.y
2
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
from collections import deque
>>> q = deque(['a', 'b', 'c'])
>>> q.append('x')
>>> q.appendleft('y')
>>> q
deque(['y', 'a', 'b', 'c', 'x'])
3.Counter: 计数器,主要用来计数
c = Counter('abcdeabcdabcaba')
print c
输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
其他详细内容 http://www.cnblogs.com/Eva-J/articles/7291842.html
4.OrderedDict: 有序字典
>>> from collections import OrderedDict
>>> d = dict([('a', 1), ('b', 2), ('c', 3)])
>>> d # dict的Key是无序的
{'a': 1, 'c': 3, 'b': 2}
>>> od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
>>> od # OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
5.defaultdict: 带有默认值的字典
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
python re模块和collections的更多相关文章
- Python 常用模块(1) -- collections模块,time模块,random模块,os模块,sys模块
主要内容: 一. 模块的简单认识 二. collections模块 三. time时间模块 四. random模块 五. os模块 六. sys模块 一. 模块的简单认识 模块: 模块就是把装有特定功 ...
- python常见模块之collections模块
一.模块简介 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdict.namedtu ...
- Python中模块之collections系列
collection系列功能介绍 1. 常用的集中类 1. Counter(计数器) 计数器的常用方法如下: 创建一个字典计数器 格式:collections.Counter(obj) 例如:prin ...
- Python标准模块--collections
1.模块简介 collections包含了一些特殊的容器,针对Python内置的容器,例如list.dict.set和tuple,提供了另一种选择: namedtuple,可以创建包含名称的tuple ...
- python常用模块(1):collections模块和re模块(正则表达式详解)
从今天开始我们就要开始学习python的模块,今天先介绍两个常用模块collections和re模块.还有非常重要的正则表达式,今天学习的正则表达式需要记忆的东西非常多,希望大家可以认真记忆.按常理来 ...
- Python常用数据结构之collections模块
Python数据结构常用模块:collections.heapq.operator.itertools collections collections是日常工作中的重点.高频模块,常用类型由: 计数器 ...
- python基础 ---time,datetime,collections)--时间模块&collections 模块
python中的time和datetime模块是时间方面的模块 time模块中时间表现的格式主要有三种: 1.timestamp:时间戳,时间戳表示的是从1970年1月1日00:00:00开始按秒计算 ...
- python的常用模块之collections模块
python的常用模块之collections模块 python全栈开发,模块,collections 认识模块 什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文 ...
- python常用模块collections os random sys
Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句. 模块让你能够有逻辑地组织你的 Python 代码段. 把相关的代码 ...
随机推荐
- JSON数据的处理中的特殊字符
JSON现在是很常见的处理数据的方式了.但由于自己使用的是反射获取数据,必须自己处理特殊字符,但总是发现有一些看不见的字符在前台 var obj = jQuery.parseJSON(msg);会转换 ...
- java对文件操作之实用
创建文件 package com.pre; import java.io.File; public class WJ { public static void main(String[] args) ...
- [转]一致性hash算法 - consistent hashing
consistent hashing 算法早在 1997 年就在论文 Consistent hashing and random trees 中被提出,目前在 cache 系统中应用越来越广泛: 1 ...
- mysql之 openark-kit online ddl
MySQL工具集openark-kit (官方网站 http://code.openark.org/forge/openark-kit),内部包含很多小工具,在5.6之前用于实现online ddl操 ...
- svn already lock解决方法
svn在pull的时候,出现svn already lock 错误.只需要在Cleanup里面勾选Break locks
- 配置Hanlp自然语言处理进阶
中文分词 中文分词中有众多分词工具,如结巴.hanlp.盘古分词器.庖丁解牛分词等:其中庖丁解牛分词仅仅支持java,分词是HanLP最基础的功能,HanLP实现了许多种分词算法,每个分词器都支持特定 ...
- Hystrix 常用属性配置
配置参数 默认值 说明 命令-执行属性配置 hystrix.command.default.execution.isolation.strategy THREAD 配置隔离策略,有效值 THREAD, ...
- windows下vscode修复c++找不到头文件
因为原博客太长将部分内容分开 vscode找不到头文件的问题是由于windows下vscode默认的编译器是微软的MSVC(vs使用的编译器)的头文件路径 如果你没有安装vs肯定会因为找不到头文件而报 ...
- C++进阶--编译器自动生成的类函数
//############################################################################ /* 在C++ 03标准下 在没有显式定义 ...
- http系列(一)
一.关于Url URI由URL和URN组成,URI即统一资源标识符,URL即统一资源定位符,URN即统一资源名称. 现在最常用的是URL. 二.http请求/响应报文 请求报文:请求行.请求头部.空行 ...