037 SparkSQL ThriftServer服务的使用和程序中JDBC的连接
一:使用
1.实质
提供JDBC/ODBC连接的服务
服务运行方式是一个Spark的应用程序,只是这个应用程序支持JDBC/ODBC的连接,
所以:可以通过应用的4040页面来进行查看操作
2.启动服务

3.配置(已经被隐含)
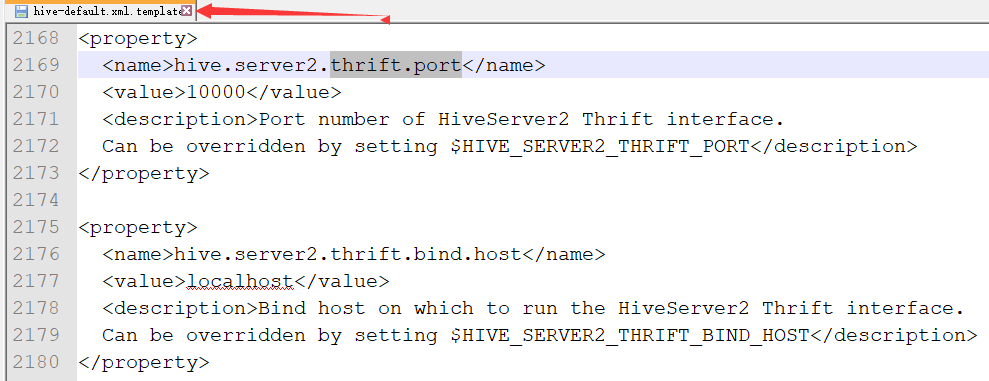
1. 配置thriftserver2的ip地址和端口号
修改hive-site.xml文件
hive.server2.thrift.port=10000
hive.server2.thrift.bind.host=localhost
2. 集成Hive环境(类似SparkSQL)
3. 启动服务
$ sbin/start-thriftserver.sh
$ sbin/stop-thriftserver.sh
4. 测试
二:测试
重要的是需要哪些服务的开启。
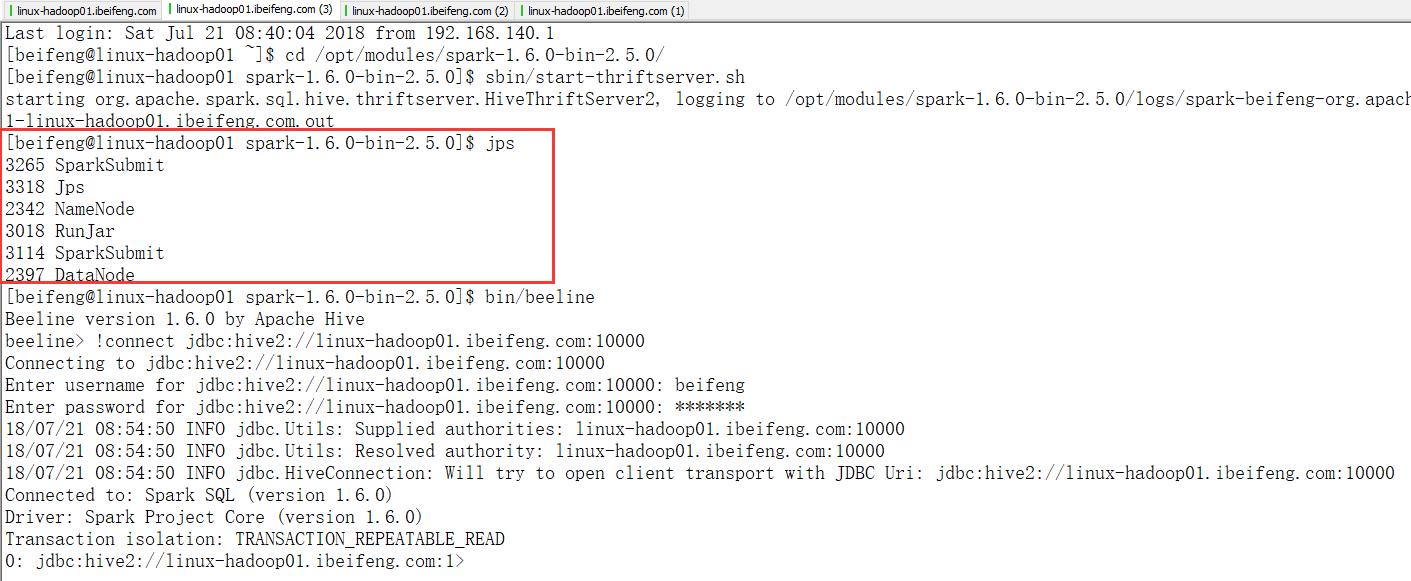
1.前提
首先是hadoop的两个服务要开启
然后是hive 的metastore
然后启动spark-shell,如果没有启动hive的metastore,则会在这一步报错,说找不到hive的9083端口。至于启动spark-shell,则是为了看4040端口上的JDBS/ODBC服务
然后启动hive thriftservice
2.测试
命令行测试,使用beeline脚本连接
上面的截图已经操作了。

3.界面(4040端口)

4.测试sql语句
测试一:

测试二:

三:程序
1.结构
2.添加依赖包

3.程序
package com.scala.it
import java.sql.DriverManager
object ThriftserverDemo {
def main(args: Array[String]):Unit= {
//add driver
val driver="org.apache.hive.jdbc.HiveDriver"
Class.forName(driver)
//get connection
val (url,username,userpasswd)=("jdbc:hive2://linux-hadoop01.ibeifeng.com:10000","beifeng","beifeng")
val connection=DriverManager.getConnection(url,username,userpasswd)
//get statement
connection.prepareStatement("use hadoop09").execute()
val sql="select * from student"
val statement=connection.prepareStatement(sql)
//get result
val rs=statement.executeQuery()
while(rs.next()){
println(s"${rs.getInt(1)}:${rs.getString(2)}")
}
//close
rs.close()
statement.close()
connection.close()
}
}
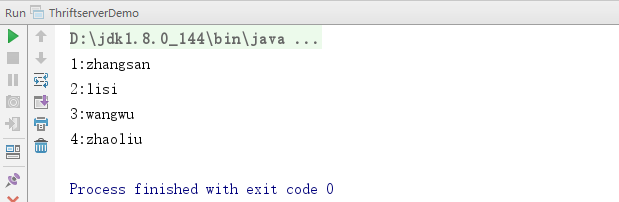
4.运行结果
037 SparkSQL ThriftServer服务的使用和程序中JDBC的连接的更多相关文章
- SparkSQL ThriftServer服务的使用和程序中JDBC的连接
SparkSQL ThriftServer服务的使用和程序中JDBC的连接 此时要注意版本问题,我第一次用的是hive2.1.1的,因为要用sparksql的hive服务,但是sparksql默认的是 ...
- 如何在服务(Service)程序中显示对话框
原文:http://www.vckbase.com/index.php/wv/94 服务程序(Service)一般是不能和用户进行交互的,所以他一般是不能显示窗口的.要和用户进行交互(如显示窗口),我 ...
- java程序中的ibatis连接mySql的基本实例
属性文件:SqlMap.properties driver=com.mysql.jdbc.Driver url=jdbc:mysql://localhost:3306/ibatis username= ...
- (转)ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务 的解决方法
早上同事用PL/SQL连接虚拟机中的Oracle数据库,发现又报了"ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务"错误,帮其解决后,发现很多人遇到过这样的问 ...
- 远程控制篇:在DELPHI程序中拨号上网
用MODEM拨号上网,仍是大多数个人网民选择上网的方式.如果能在我们的应用程序中启动拨号连接(如IE浏览器程序中的自动拨号功能),无疑将会方便我们的软件用户(不用再切换应用程序,运行拨号网络),提高我 ...
- 3.hive的thriftserver服务
1.ThiftServer介绍 正常的hive仅允许使用HiveQL执行查询.更新等操作,并且该方式比较笨拙单一.幸好Hive提供了轻客户端的实现,通过HiveServer或者HiveServer2, ...
- 关于Oracle报“ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务”错误
关于Oracle报“ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务”错误原因:listener.ora中没有指定监听服务器名. 如下是解决思路: 尝试1.通过重启服务的方式启动数 ...
- Oracle几个基础配置问题:ORA-12154: TNS: 无法解析指定的连接标识符、ORA-12514: TNS: 监听程序当前无法识别连接描述符中请求的服务、ORA-12516 TNS监听程序找不到符合协议堆栈要求的可用处理程序
问题1:ORA-12154: TNS: 无法解析指定的连接标识符 在一台服务器上部署了Oracle客户端,使用IP/SID的方式访问,老是报ORA-12154错误,而使用tnsnames访问却没有问题 ...
- ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务 的解决方法
今天用PL/SQL连接虚拟机中的Oracle数据库,发现报了“ORA-12514 TNS 监听程序当前无法识别连接描述符中请求服务”错误,也许你也遇到过,原因如下: oracle安装成功后,一直未停止 ...
随机推荐
- 【转】vi 写完文件保存时才发现是 readonly
在MAC上编辑apache配置文件,老是忘记sudo…… readonly的文件保存时提示 add ! to override, 但这仅是对root来说的啊! 百毒了一下竟然还有解决方案!! :w ! ...
- mybatis ${}与#{}的区别
#{}可以直接获取方法的参数: ${}从方法的参数中利用get方法来获取参数的属性值:
- root和alias的区别
先来看看官方说明: root 的用法: location /request_path/image/ { root /local_path/; } 当客户端请求 /request_path/image/ ...
- 【转】Android 编程下的代码混淆
什么是代码混淆 代码混淆(Obfuscated code)亦称花指令,是将计算机程序的代码,转换成一种功能上等价,但是难于阅读和理解的形式的行为.代码混淆可以用于程序源代码,也可以用于程序编译而成的中 ...
- 数据量越发庞大怎么办?新一代数据处理利器Greenplum来助攻
作者:李树桓 个推数据研发工程师 前言:近年来,互联网的快速发展积累了海量大数据,而在这些大数据的处理上,不同技术栈所具备的性能也有所不同,如何快速有效地处理这些庞大的数据仓,成为很多运营者为之苦恼的 ...
- 弹指之间 -- Slow Soul
CHAPTER 16 慢灵魂乐 Slow Soul (8Beat) Slow Soul每小节内几乎都是以8分音符弹奏,又称之为8Beat节奏,80左右的速度最能表现此节奏特色. 示例曲目: 拥抱
- Java基础-二进制以及字符编码简介
Java基础-二进制以及字符编码简介 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必计算机毕业的小伙伴或是从事IT的技术人员都知道数据存储都是以二进制的数字存储到硬盘的.从事开 ...
- js实现表单提交submit(),onsubmit
通常表单的提交有两种方式,一是直接通过html的form提交,代码如下: <form action="" method="" id="forms ...
- Dubbo学习笔记9:Dubbo服务提供方启动流程源码分析
首先我们通过一个时序图,直观看下Dubbo服务提供方启动的流程: 在<Dubbo整体框架分析>一文中我们提到,服务提供方需要使用ServiceConfig API发布服务,具体是调用代码( ...
- WebViewJavascriptBridge测试示例
android或ios:app与html5通信解决方案 下面只是前端示例代码,后端代码请参考: git https://github.com/marcuswestin/WebViewJavascrip ...