关于Sql Server的一些知识点的定义总结
数据库完整性:是指数据库中数据在逻辑上的一致性、正确性、有效性和相容性
实体完整性(Entity Integrity 行完整性):实体完整性指表中行的完整性。主要用于保证操作的数据(记录)非空、唯一且不重复。即实体完整性要求每个关系(表)有且仅有一个主键,每一个主键值必须唯一,而且不允许为“空”(NULL)或重复。
域完整性(Domain Integrity 列完整性):是指数据库表中的列必须满足某种特定的数据类型或约束。其中约束又包括取值范围、精度等规定。表中的CHECK、FOREIGN KEY 约束和DEFAULT、 NOT NULL定义都属于域完整性的范畴。
参照完整性(Referential Integrity)属于表间规则:对于永久关系的相关表,在更新、插入或删除记录时,如果只改其一,就会影响数据的完整性。如删除父表的某记录后,子表的相应记录未删除,致使这些记录称为孤立记录。
参照完整性规则(Referential Integrity)要求:若属性组F是关系模式R1的主键,同时F也是关系模式R2的外键,则在R2的关系中,F的取值只允许两种可能:空值或等于R1关系中某个主键值。
Sql Server的存储结构,页、区、堆
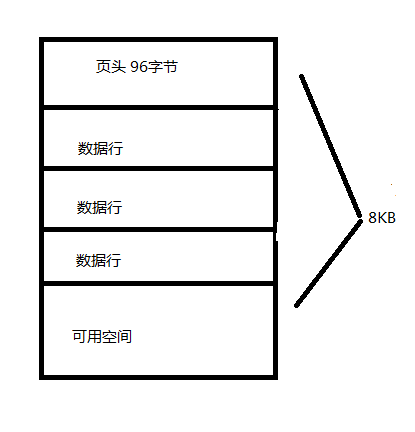
页:用于数据存储的连续的磁盘空间块,SQL Server中数据存储的基本单位是页,磁盘I/O操作在页级执行,页的大小为8KB。每页的开头是96字节的页头,用于存储有关页的系统信息,包括页码、页类型、页的可用空间以及拥有该页的对象的分配单元ID;其他便是存储数据的数据行与剩下可用空间,结构图如下(个人绘制)
区间:区是管理空间的基本单位,一个区是8个物理上连续的页(即64KB)的集合,所有页都存储在区中。SQL Server有两种类型的区:统一区和混合区。
堆:堆是指不含聚集索引的表,它的数据不按任何顺序进行存储。
联系一个堆中的数据的唯一结构是被称为索引分配映射(IAM)的一个位图页,当扫描对象时,SQl server使用IAM页来遍历该对象的数据。
堆表内的数据页和行没有任何特定的顺序,也不链接在一起。数据页之间唯一的逻辑连接是记录在 IAM 页内的信息
假设某订单明细表中有100万条数据,需要查询某个订单的明细数据,如下:
select * from T_EPZ_INOUT_ENTRY_DETAIL where entry_apply_id='31227000034000090169'
如果在堆表中进行查询,SQL Server通过扫描 IAM 页对堆表进行全表扫描,对entry_apply_id比较100万次,如果以entry_apply_id字段建立索引,则因为索引键值数据都必定以B-Tree有顺序的摆放,所以可采用二分查找找数据。也就是2的N次方大于记录数,就可以找到该条数据。而2的20次方大于100万,因此最多找寻20次就可以找到该条记录。20次与100万次的比较,你可以轻松感受出性能的差异。
由此引出索引的概念
索引分为聚集索引与非聚集索引
聚集索引 :聚集索引是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度
非聚集索引:非聚集索引是一种索引,该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同
聚集索引与非聚集索引的形象比喻
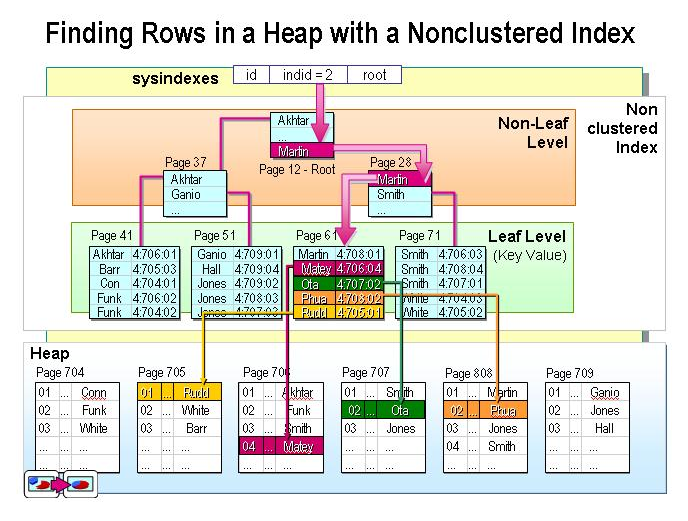
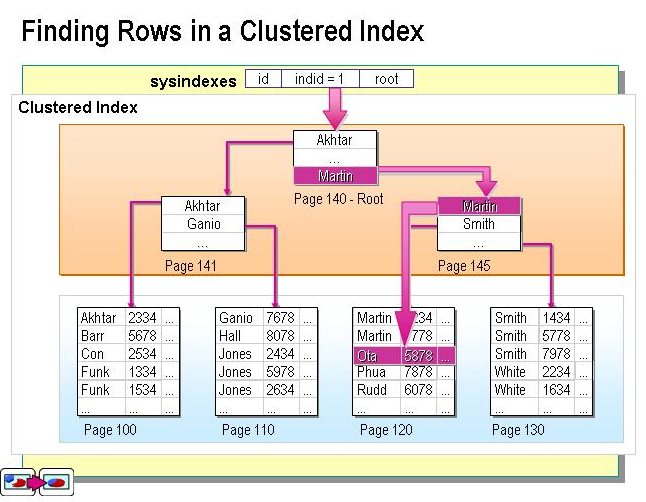
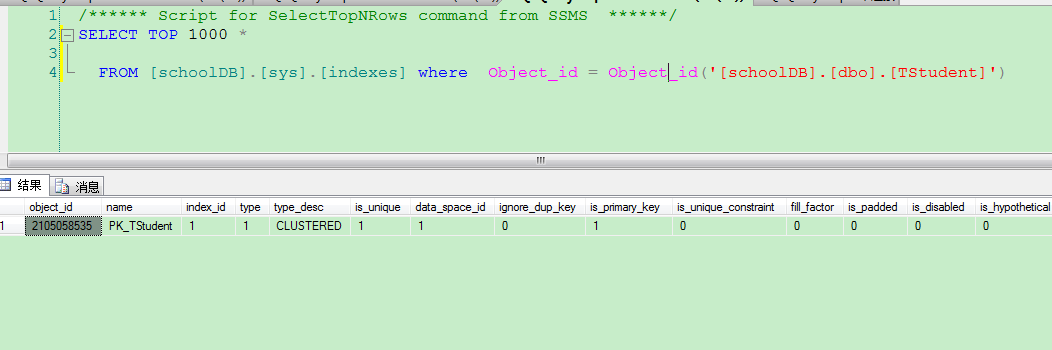
dbcc showcontig(Tstudent,non_sname) --Tstudent表明,PK_TStudent索引名 ,查询页分裂情况 dbcc indexdefrag(schoolDB,Tstudent,non_sname)--索引整理 create nonclustered index non_sname on TStudent(sname) with drop_existing,fillfactor = 50--重建索引,并且制定填充因子 dbcc show_statistics(tstudent,non_sname)--查看索引统计 update statistics schooldb.dbo.tstudent --人工更新表中所有索引的统计 update statistics schooldb.dbo.tstudent non_sname --人工更新表中non_sname索引统计
关于Sql Server的一些知识点的定义总结的更多相关文章
- sql server查询可编程对象定义的方式对比以及整合
本文目录列表: 1.sql server查看可编程对象定义的方式对比 2.整合实现所有可编程对象定义的查看功能的存储dbo.usp_helptext2 3.dbo.helptext2的选择性测试 4. ...
- SQL Server数据库的存储过程中定义的临时表,真的有必要显式删除临时表(drop table #tableName)吗?
本文出处:http://www.cnblogs.com/wy123/p/6704619.html 问题背景 在写SQL Server存储过程中,如果存储过程中定义了临时表,有些人习惯在存储过程结束的时 ...
- Sql Server数据库小知识点总结
把我在开发时候遇到的一点小知识持续更新在这里~ 1.where条件时常变 where UserID='1' 这里的UserID呢,它的值是经常在变化的,有时候要查2,有时候要查3的,有时候要查全部人! ...
- 调试SQL Server的存储过程及用户定义函数
分类: 数据库管理 2005-06-03 13:57 9837人阅读 评论(5) 收藏 举报 sql server存储vb.net服务器sql语言 1.在查询分析器中调试 查询分析器中调试的步骤如下: ...
- sql server 常用小知识点
1. sql server的语法:中文要加 N select * from eVA_EMPBoard where name = N'施纪平' 而oracle的不用 2.
- sql server DDL语句 建立数据库 定义表 修改字段等
一.数据库:1.建立数据库 create database 数据库名;use 数据库名; create database exp1;use exp1; mysql同样 2.删除数据库 drop dat ...
- 关于SQL server的一些知识点
关于怎么打开xp_cmdshell的方法: exec sp_configure 'show advanced option',1reconfiguregoexec sp_configure 'xp_c ...
- Sql server中根据object的定义查找object
SELECT OBJECT_NAME(object_id) FROM sys.sql_modulesWHERE definition LIKE '%keyword to search%' 或者 SEL ...
- SQL Server安全(6/11):执行上下文与代码签名(Execution Context and Code Signing)
在保密你的服务器和数据,防备当前复杂的攻击,SQL Server有你需要的一切.但在你能有效使用这些安全功能前,你需要理解你面对的威胁和一些基本的安全概念.这篇文章提供了基础,因此你可以对SQL Se ...
随机推荐
- java基础基础总结----- System
常用的方法: 细节分析:
- P3932 浮游大陆的68号岛
P3932 浮游大陆的68号岛 妖精仓库的储物点可以看做在一个数轴上.每一个储物点会有一些东西,同时他们之间存在距离. 每次他们会选出一个小妖精,然后剩下的人找到区间[l,r]储物点的所有东西,清点完 ...
- 蓝桥杯 算法提高 9-3摩尔斯电码 _c++ Map容器用法
//****|*|*-**|*-**|--- #include <iostream> #include <map> #include <vector> #inclu ...
- zsh与oh-my-zsh是什么
zsh是bash的增强版,其实zsh和bash是两个不同的概念.zsh更加强大. 通常zsh配置起来非常麻烦,且相当的复杂,所以oh-my-zsh是为了简化zsh的配置而开发的,因此oh-my-zsh ...
- Raid 磁盘阵列
raid 原理与区别 raid0至少2块硬盘.吞吐量大,性能好,同时读写,但损坏一个就完蛋 raid1至少2块硬盘.相当镜像,一个存储,一个备份.安全性比较高.但是性能比0弱 raid5至少3块硬盘. ...
- 无法执行该操作,因为链接服务器 "xxxxx" 的 OLE DB 访问接口 "SQLNCLI" 无法启动分布式事务
在存储过程中使用事务,并且使用链接服务器时,报类似下面的错误 链接服务器"****"的 OLE DB 访问接口 "SQLNCLI10" 返回了消息 " ...
- Paint Fence
There is a fence with n posts, each post can be painted with one of the k colors.You have to paint a ...
- Android网络框架之Retrofit + RxJava + OkHttp 变化的时代
1.什么是Retrofit框架? 它是Square公司开发的现在非常流行的网络框架,所以我们在导入它的包的时候都可以看到这个公司的名字,目前的版本是2. 特点: 性能好,处理快,使用简单,Retrof ...
- Python发送邮件:smtplib、sendmail
本地Ubuntu 18.04,本地Python 3.6.5, 阿里云Ubuntu 16.04,阿里云Python 3.5.2, smtplib,sendmail 8.15.2, 今天,打算实现通过电子 ...
- java.util.concurrent.RejectedExecutionException
java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@59f1ca76 rejec ...