57.storm拓扑结构调整
几个概念
Topology(拓扑):Spout、Bolt组成的一个完整的流程结构;
Stream Grouping:流分组、数据的分发方式;
Spout:直译 水龙头,也就是 消息源 的意思;
Bolt:螺栓、处理器。很形象,水从上面的那个“水龙头”流出来,经过第一个螺栓,经过第二个螺栓,经过第三第四个螺栓...
Worker:工作进程
Executor:执行器、task的线程;
Task:具体执行的任务;
Configuration:配置。
实际操作
回顾
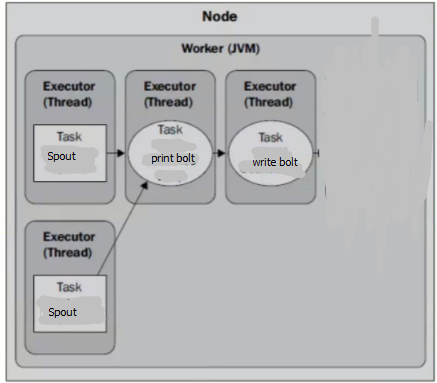
在上上节(55节),本地模式跑起来的,只有一个JVM(虽然分配了两个,cfg.setNumWorkers(2); 但是在本地跑的时候只可能启动一个JVM),那么拓扑的执行情况应该是下面这样的,一个worker下有几个Executor,每个Executor分别对应一个Spout或者Bolt(图片中的bolt和Spout名称和代码不一致,请对号入座):

结构调整
如果我们把带码稍作改动(只需要改Topology)
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.topology.TopologyBuilder;
import bhz.bolt.PrintBolt;
import bhz.bolt.WriteBolt;
import bhz.spout.PWSpout; public class PWTopology2 { public static void main(String[] args) throws Exception { Config cfg = new Config();
cfg.setNumWorkers(2);//设置使用俩个工作进程
cfg.setDebug(false);
TopologyBuilder builder = new TopologyBuilder();
//设置sqout的并行度和任务数(产生2个执行器和俩个任务)
builder.setSpout("spout", new PWSpout(), 2);//.setNumTasks(2);
//设置bolt的并行度和任务数:(产生2个执行器和4个任务)
builder.setBolt("print-bolt", new PrintBolt(), 2).shuffleGrouping("spout").setNumTasks(4);
//设置bolt的并行度和任务数:(产生6个执行器和6个任务)
builder.setBolt("write-bolt", new WriteBolt(), 6).shuffleGrouping("print-bolt"); //1 本地模式
// LocalCluster cluster = new LocalCluster();
// cluster.submitTopology("top2", cfg, builder.createTopology());
// Thread.sleep(10000);
// cluster.killTopology("top2");
// cluster.shutdown(); //2 集群模式
StormSubmitter.submitTopology("top2", cfg, builder.createTopology()); }
}
1.谈谈本地为什么会生成那么多文件
如果我们以本地模式启动,那么运行结果将会是这样的,temp文件夹里有6个文件
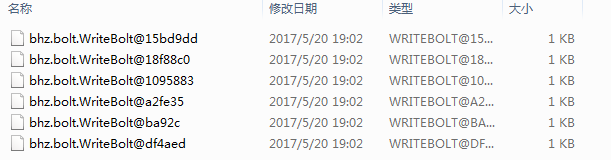
那么为什么会产生6个文件呢?注意代码的第22行

这里设置6个执行器来执行WriteBolt,默认每个执行器是一个task,也就是有6个task;再来看看WriteBolt是怎么形成文件的:

可以看出,每个线程都会在099_test下形成一个文件。
2.spout部分的拓扑结构调整
假如,我们只修改这一行代码

那么在只有一个JVM的情况下,整体拓扑结构应该类似这样的:
3.如果完全修改成上面的代码,并且可以启动多个JVM的话,呢么拓扑结构应该是下面这样的(图片中的bolt和Spout名称和代码不一致,请对号入座):
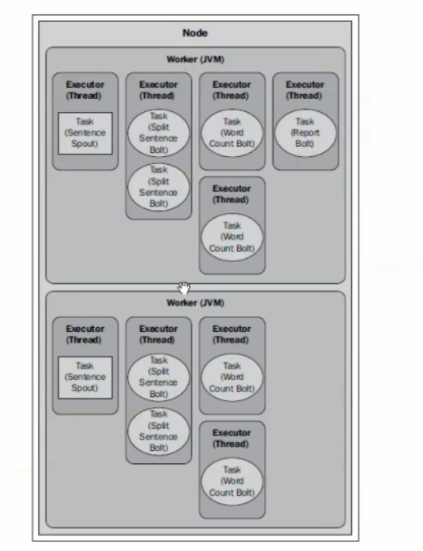
针对上面的这种拓扑结构的总结:

遇到一点问题,storm supervisor & 启动报错java.lang.RuntimeException: java.io.EOFException:
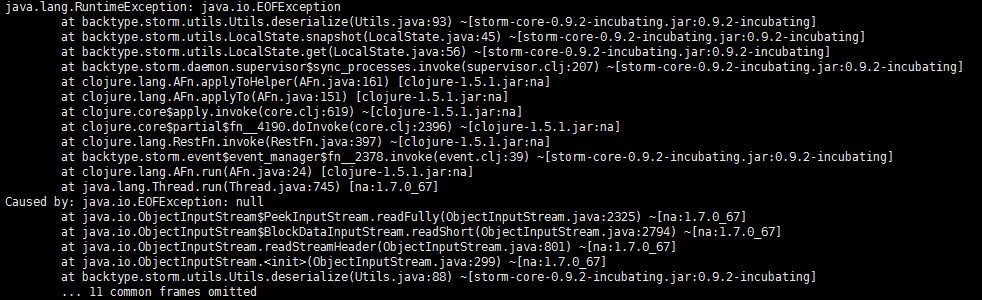
解决办法:删除storm.yaml中配置的storm.local.dir指向的目录中的supervisor和workers两个目录,再次启动即可。
57.storm拓扑结构调整的更多相关文章
- [转载] 使用 Twitter Storm 处理实时的大数据
转载自http://www.ibm.com/developerworks/cn/opensource/os-twitterstorm/ 流式处理大数据简介 Storm 是一个开源的.大数据处理系统,与 ...
- Storm入门之第二章
1.准备开始 本章创建一个Storm工程和第一个Storm拓扑结构. 需要提供JER版本在1.6以上,下载地址http://www.java .com/downloads/. 2.操作模式 Storm ...
- Storm日志分析调研及其实时架构
1.Storm第一个Demo 2.Windows下基于eclipse的Storm应用开发与调试 3.Storm实例+mysql数据库保存 4.Storm原理介绍 5. flume+kafka+stor ...
- storm安装笔记以及提交拓扑任务
Storm -- Distributed and fault-tolerant realtime computation 这是一个分布式的.容错的实时计算系统 把Storm依赖组件的版本贴出来供各位参 ...
- 【原】Storm配置
Storm入门教程 1. Storm基础 Storm Storm主要特点 Storm基本概念 Storm调度器 Storm配置 Guaranteeing Message Processing(消息处理 ...
- Apache Storm简介
Apache Storm简介 Storm是一个分布式的,可靠的,容错的数据流处理系统.Storm集群的输入流由一个被称作spout的组件管理,spout把数据传递给bolt, bolt要么把数据保存到 ...
- Storm入门之第一章
Storm入门之第一章 1.名词 spout龙卷,读取原始数据为bolt提供数据 bolt雷电,从spout或者其他的bolt接收数据,并处理数据,处理结果可作为其他bolt的数据源或最终结果 nim ...
- 2018.5.12 storm数据源kafka堆积
问题现象: storm代码依赖4个源数据topic,2018.5.12上午8点左右开始收到告警短信,源头的4个topic数据严重堆积. 排查: 1.查看stormUI, storm拓扑结构如下: 看现 ...
- Storm是什么
Why use Storm? Apache Storm是一个免费的开源的分布式实时计算系统.Storm使得可靠的实时处理无边界的数据量变得很容易,就如同Hadoop做批处理那样.Storm很简单,可以 ...
随机推荐
- Java泛型总结——吃透泛型开发
什么是泛型 泛型是jdk5引入的类型机制,就是将类型参数化,它是早在1999年就制定的jsr14的实现. 泛型机制将类型转换时的类型检查从运行时提前到了编译时,使用泛型编写的代码比杂乱的使用objec ...
- boost--function
1.简介 function是一个模板类,它就像一个包装了函数指针或函数对象的容器(只有一个元素).可以把它想象成一个泛化的函数指针,而且他非常适合代替函数指针,存储用于回调的函数.如下定义了一个能够容 ...
- AngularJS的$location基本用法和注意事项
一.配置config app.config([ '$locationProvider', function($locationProvider) { $locationProvider.html5Mo ...
- ueditor+word粘贴上传
公司做的项目要用到文本上传功能. 网上找了很久,大部分都有一些不成熟的问题,终于让我找到了一个成熟的项目. 下面就来看看: 1.打开工程: 对于文档的上传我们需要知道这个项目是否符合我们的初衷. 运行 ...
- (转)mysql command line client打不开(闪一下消失)的解决办法
转自:http://www.2cto.com/database/201209/153858.html 网上搜索到的解决办法: 1.找到mysql安装目录下的bin目录路径. 2.打开cmd,进入到bi ...
- _编程语言_C_C++_数据结构_struct
Struct 语句,访问成员使用 点结构. Example: #include <iostream> #include <cstring> using namespace st ...
- web-day12
第12章WEB12-JSP&EL&JSTL篇 今日任务 商品信息的显示 教学导航 教学目标 掌握JSP的基本的使用 掌握EL的表达式的用法 掌握JSTL的常用标签的使用 教学方法 案例 ...
- TBB的学习
1. TBB简介 TBB ( Thread Building Blocks, 线程构建模块) 是Intel公司开发的并行编程开发的工具.它支持Windows,OS X, Linux平台,支持的编译器有 ...
- js加减运算·传参
<!DOCTYPE html><html> <head> <meta charset="utf-8" /> <title> ...
- jQuery插件初级练习1答案
html: <script> $(".btn").click(function(){ $.color($("#box"),"blue&qu ...