机器学习:Selective Search for Object Recognition
今天介绍 IJCV 2013 年的一篇文章,Selective Search for Object Recognition,这个是后面著名的DL架构 R-CNN 的基础,后续介绍 R-CNN 的时候,会发现 R-CNN 和这篇文章里介绍的算法非常类似。
做模式识别的人都知道,目标识别与目标检测是两个不同的东西,目标检测比目标识别要难得多,目标识别可以看做是一个分类问题,给定一张测试图,我们只要判断这张图里有没有某一特定的物体,而目标检测,需要在这张图上标出物体的具体位置,这可以看做是一个回归问题,不仅需要判断有没有,而且还要判断在哪里。
我们知道,同一类物体,在不同的图像中,会有不同的尺度,不同的位置,甚至会有不同的形状,所以,目标检测是要解决这样一个问题:
- 如何在任意给定的一张图像中检测到某一物体,这种检测要克服尺度的变化,位置的变化以及形状的变化。
一种最直观的方案就是利用图像的分割,先把图像分割成一个个的区域,然后对分割之后的区域做判别,所以这篇文章最重要的贡献就是把一个回归问题转换成一个分类问题,结合了分割与搜索。
图像分割一直是图像处理领域非常基础却又非常重要的一个应用,简单来说,图像的分割就是一种聚类,把相似的像素聚到一起,这样就形成一个个不规则的区域。图像分割最大的难点就在于确定聚类的准则,因为不同的准则,最终得到的结果会不同。
图像分割的精准与否,又会影响到最终的检测结果,所以这篇文章利用了一个 Hierarchical Grouping 的策略对图像进行聚类分割,简单来说,就是先对图像做一个初步的分割,把图像先分割成很多细碎的小区域,然后利用一些准则,将这些小区域再合并成大区域。文章里面,考虑了区域的相似性,设计了四种判别准则,分别是颜色,纹理,尺寸以及填充度。
颜色相似性
为了统计颜色的相似性,这里还是要用到颜色直方图的概念,我们知道彩色图像有 R,G,B 三个通道,每个通道应该是 0−255 共 256 个灰阶,为了简化运算,文章将 256 个灰阶先合并成 25 个灰阶,所以每个颜色通道是 25 个灰阶,三个颜色通道一共 75 个灰阶,将这75个灰阶先做一个统计,然后做一个归一化,就是这个区域的颜色直方图。两个区域的颜色相似性,就是比较两个区域的颜色直方图,将值较小的进行累加,得到最终的相似度,如下所示:
Scolor(ri,rj)=∑nk=1min(cki,ckj)
颜色直方图的一个好处是当两个区域合并的时候,新合并的区域的颜色直方图可以很快速的计算得到:
Ct=Nri×Ci+Nrj×CjNri+Nrj
Nri,Nrj 表示区域 ri,rj 的像素个数,
纹理相似性
为了统计纹理的相似性,文章用了高斯滤波,对每个区域做一个高斯滤波,高斯滤波一共有 8 个方向,将滤波后的区域做一个直方图统计,合并成 10 个 灰阶,所以 8个方向的高斯滤波生成了 80个灰阶,三个通道一共是 240个灰阶,同样要做归一化,再利用类似的公式计算纹理相似性:
Stexture(ri,rj)=∑nk=1min(tki,tkj)
尺寸相似性
这个准则是为了让小区域先合并,尺寸相似性的计算如下:
Ssize(ri,rj)=1−Nri+NrjNimg
Nri,Nrj 表示区域 ri,rj 的像素个数,Nimg 表示整张图像的像素个数。
重叠度
这个准则衡量两个区域的交集,重叠的部分有多少,这个准则的计算如下:
Sfill(ri,rj)=1−NBBij−Nri−NrjNimg
NBBij 表示包围区域 ri,rj 的最小区域, 从这个表达式可以看出,如果两个区域靠的越近,则 Sfill 越大,说明这两个区域越应该被合并。
最终的相似度,是这四个准则的线性叠加:
S(ri,rj)=a1Scolor(ri,rj)+a2Stexture(ri,rj)+a3Ssize(ri,rj)+a4Sfill(ri,rj)
确定了相似性的度量准则,接下来,我们就是要对区域进行合并,具体的算法如下所示:

先利用一个分割算法,对图像进行初步的分割,得到一个分割区域的集合 R={r1,r2,...,rn},然后把所有的分割区域进行标记,接下来,对所有的区域两两之间计算相似性,所有的相似性度量可以组成一个集合 S。
接下来:
1) 从集合 S 中挑选相似性度量最大的一个 s(ri,rj)
2) 将区域 ri,rj 进行合并得到 rt
3) 将集合中含有 ri,rj 的的相似性度量都去除
4) 计算 rt 与其相邻区域的相似性,得到一个有关 rt 与其相邻区域的相似性度量集合 St
5) 将 St 与剩下的 S 合并
6) 将 R 与 rt 合并
如果 S 为非空集合,返回第一步,继续计算。
最后,可以提取出目标物体的一个矩形区域。
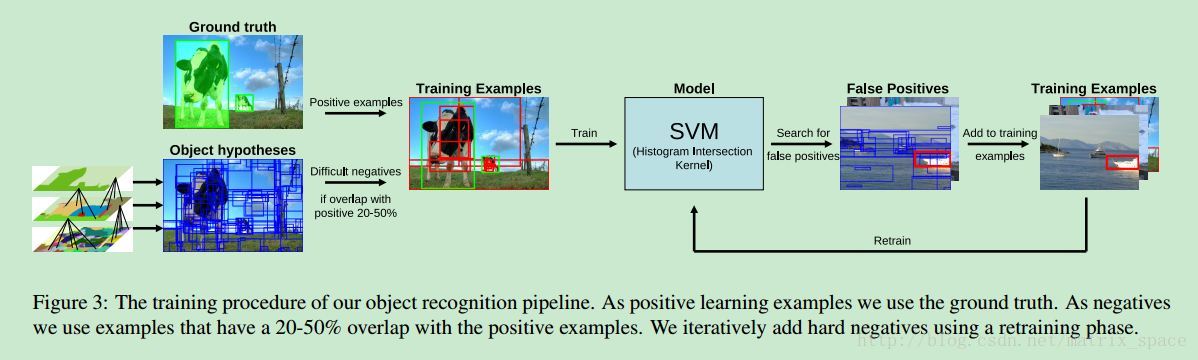
接下来,就是特征提取和训练了,这里用到的特征是 SIFT 加 BoW, 具体的流程如下所示:
机器学习:Selective Search for Object Recognition的更多相关文章
- 【计算机视觉】Selective Search for Object Recognition论文阅读3
Selective Search for Object Recoginition surgewong@gmail.com http://blog.csdn.net/surgewong 在前 ...
- Notes on 'Selective Search For Object Recognition'
UijlingsIJCV2013, Selective Search For Object Recognition code 算法思想 利用分割算法将图片细分成很多region, 或超像素. 在这个基 ...
- 论文笔记:Selective Search for Object Recognition
与 Selective Search 初次见面是在著名的物体检测论文 「Rich feature hierarchies for accurate object detection and seman ...
- 目标检测--Selective Search for Object Recognition(IJCV, 2013)
Selective Search for Object Recognition 作者: J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, A. ...
- Selective Search for Object Recognition
http://blog.csdn.net/charwing/article/details/27180421 Selective Search for Object Recognition 是J.R. ...
- [论文理解]Selective Search for Object Recognition
Selective Search for Object Recognition 简介 Selective Search是现在目标检测里面非常常用的方法,rcnn.frcnn等就是通过selective ...
- 【计算机视觉】Selective Search for Object Recognition论文阅读2
Selective Search for Object Recognition 是J.R.R. Uijlings发表在2012 IJCV上的一篇文章.主要介绍了选择性搜索(Selective Sear ...
- 【计算机视觉】Selective Search for Object Recognition论文阅读1
Selective Search for Object Recognition 作者: J. R. R. Uijlings, K. E. A. van de Sande, T. Gevers, A. ...
- Selective Search for Object Recognition 论文笔记【图片目标分割】
这篇笔记,仅仅是对选择性算法介绍一下原理性知识,不对公式进行推倒. 前言: 这篇论文介绍的是,如果快速的找到的可能是物体目标的区域,不像使用传统的滑动窗口来暴力进行区域识别.这里是使用算法从多个维度对 ...
随机推荐
- shell循环,判断介绍,以及实例
shell的循环主要有3种,for,while,until shell的分支判断主要有2种,if,case 一,for循环 #!/bin/bash for file in $(ls /tmp/test ...
- HTTP头解读
Http协议定义了很多与服务器交互的方法,最基本的有4种,分别是GET.POST.PUT.DELETE.一个URL地址用于描述一个网络上的资源, 而HTTP中的GET.POST.PUT. DELETE ...
- Linux安装indicator-china-weather
https://launchpad.net/indicator-china-weather sudo apt-get update sudo apt-get install python-appind ...
- OOA/OOD/OOP的区别
http://javajiao.iteye.com/blog/152956这是一个故事: "工程師修了一條隧道,隧道的一端就是美麗的風景,很多人會開車通過隧道.雖然隧道內已經有燈了,但是設計 ...
- 扩展MongoDB C# Driver的QueryBuilder
扩展MongoDB C# Driver的QueryBuilder 因为不想直接hardcode "ClassA.MemberA.MemberB" 这种字符串 .写了下面几个类,用于 ...
- firework压缩图片类似于GD库中压缩图片的思路
1.先建一张空白图片, 2.再把需要压缩的图片拖上去, 3.符合画布 4.调到需要的大小
- condarc文件
channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/ - https://mirrors.tuna.tsingh ...
- CGI FASTCGI php-fpm
CGI(Common Gateway Interface) CGI全称是“公共网关接口”(Common Gateway Interface),HTTP服务器与你的或其它机器上的程序进行“交谈”的一种工 ...
- ejabberd日志分析客户端登录流程
通过ejabberd的日志,整理了下客户端登录流程. 1. 通过TCP连接5222端口的流程: (1) 客户端向服务器发送stream流 <stream:stream to="nba. ...
- 3_Jsp标签_简单标签_防盗链和转义标签的实现
一概念 1防盗链 在HTTP协议中,有一个表头字段叫referer,采用URL的格式来表示从哪儿链接到当前的网页或文件,通过referer,网站可以检测目标网页访问的来源网页.有了referer跟踪来 ...