关于Python编码问题小记
Python编码问题小记:
引子:
最近在复习redis,当我在获取redis的key的时候,redis 存储英文和汉字下面这个样子的,我知道汉字是用16进制的UTF-8编码了,然后突然很想搞清楚字符编码的知识,以及在Python中编码的转换,记下了这个随笔。
127.0.0.1:6379> get n5
"\xe5\xa7\x9a\xe6\xbb\xa8"
127.0.0.1:6379> get n1
"abc"
为什么要指定编码类型?
计算机本身只能识别 0 1 的组合,一堆01组合对我们来讲几乎看不懂,那么相当于中英文,我想看懂,有个中英文词典对照是不是就可以了 ,计算机也是一样。
ASCII码
每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个 状态对应一个符号,就是256个符号从00000000到11111111。上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
扩展ASCII码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号。
Unicode(统一码、万国码、单一码)
编码方式越来越多,如果我想用其他国的软件那么还可能出现俩种情况:
1. 字符编码没有。
2. 字符编码冲突了,人家在写这个程序的时候指定的字符集和咱们使用的字符集的位置不对。
这种情况下,打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。 可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536 注:此处说的的是最少2个字节,可能更多。就像它的名字都表示的,这是一种所有符号的编码。Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。当使用的字节增加了,那么造成的直接影响就是使用的空间就直接翻倍了!举例还说:同样是ABCD这些字符存储一篇相同的文章,使用ASCII码如果是1M的话,那么Unicode存储至少2M可能还会更多。为了解决个问题就出现了:UTF-8编码
UTF-8编码
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,它可以使用1~4个字节表示一个符号,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节,汉字用3个字节保存兼容ASCII编码的。这样显著的好处是,虽然在我们内存中的数据都是unicode,但当数据要保存到磁盘或者用于网络传输时,直接使用unicode就远不如utf8省空间啦! 这也是为什么utf8是我们的推荐编码方式。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
----------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Unicode与utf8的关系
Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)这也是UTF与Unicode的区别。
UTF-8如何节约硬盘流量的
这里借鉴的是: http://www.cnblogs.com/yuanchenqi/articles/5956943.html
s="I'm 苑昊"
你看到的unicode字符集是这样的编码表:
I 0049
' 0027
m 006d
0020
苑 82d1
昊 660a
每一个字符对应一个十六进制数字。
计算机只懂二进制,因此,严格按照unicode的方式(UCS-2),应该这样存储:
I 00000000 01001001
' 00000000 00100111
m 00000000 01101101
00000000 00100000
苑 10000010 11010001
昊 01100110 00001010
这个字符串总共占用了12个字节,但是对比中英文的二进制码,可以发现,英文前9位都是0!浪费啊,浪费硬盘,浪费流量。怎么办?UTF8:
I 01001001
' 00100111
m 01101101
00100000
苑 11101000 10001011 10010001
昊 11100110 10011000 10001010
utf8用了10个字节,对比unicode,少了两个,因为我们的程序英文会远多于中文,所以空间会提高很多!
记住:一切都是为了节省你的硬盘和流量。
Python编码转换:
Python2 中的默认编码: ASCII
Python 2.6.6 (r266:84292, Aug 18 2016, 15:13:37)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-17)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
Python3中的默认编码: Unicode,告诉自己记住...Unicode是内存编码表示方案(是规范),而UTF是如何保存和传输Unicode的方案(是实现)。py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
Python 3.6.3 (default, Oct 20 2017, 17:56:37)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-17)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import sys
>>> sys.getdefaultencoding()
'utf-8'
说了那么多,那么如何转码呢,我们知道unicode包含了utf-8和gbk那么把他们都转成unicode,在转成我们需要的字符编码是不是就可以都能正常显示了呢,写个代码看看
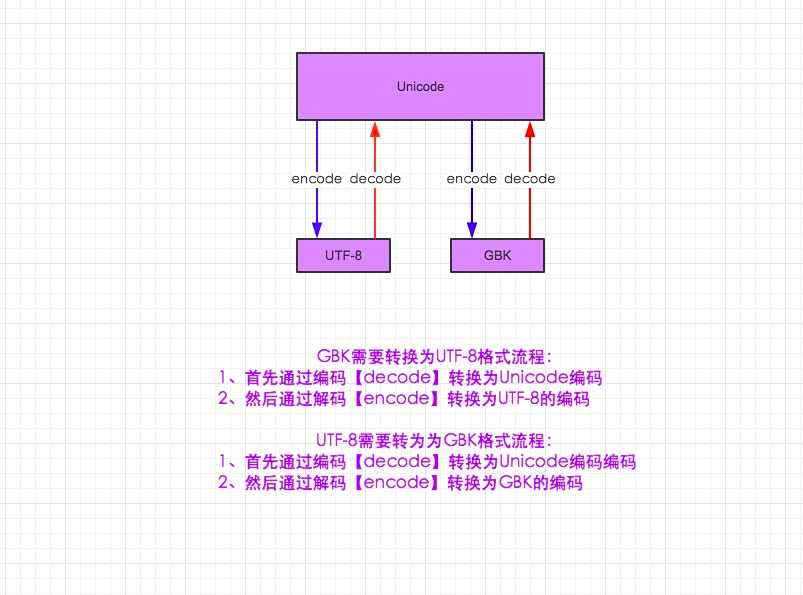
PY2转换:
#-*- coding:utf-8 -*-
import sys
print(sys.getdefaultencoding())
s = "汉字"
s_to_unicode = s.decode("utf-8")
print(s_to_unicode)
s_to_gbk = s_to_unicode.encode("gbk")
print(s_to_gbk)
gbk_to_utf8 = s_to_gbk.decode("gbk").encode("utf-8")
print(gbk_to_utf8)
终端(utf-8):
[root@Python01 ~]# python 2
ascii
汉字 汉字
终端(gbk)
[root@Python01 ~]# python 2
ascii
姹夊瓧
汉字
姹夊瓧
PY3转换:
python3默认就是unicode so ...
#-*- coding:utf-8 -*-
import sys
print(sys.getdefaultencoding())
s = "汉字"
s_to_unicode = s.encode('gbk')
print(s_to_unicode)
print(s_to_unicode.decode('gbk').encode('utf-8'))
终端
[root@Python01 ~]# python3 4
utf-8
b'\xba\xba\xd7\xd6'
b'\xe6\xb1\x89\xe5\xad\x97' #utf8
这就是为什么我们在python文件中,尤其是py2中想要中文显示就必须要声明#-*- coding:utf-8 -*-,是的,这就是因为如果py2解释器去执行一个utf8编码的文件,就会以默认地ASCII去解码utf8,一旦程序中有中文,自然就解码错误了,所以我们在文件开头位置声明 #coding:utf8,其实就是告诉解释器,你不要以默认的编码方式去解码这个文件,而是以utf8来解码。而py3的解释器因为默认utf8编码,所以就方便很多了。
借个图:PS 我觉得奥创在《复仇者联盟2》里开场很牛,结局有点Low...不过红魔(james spader)的演技真的太棒了。
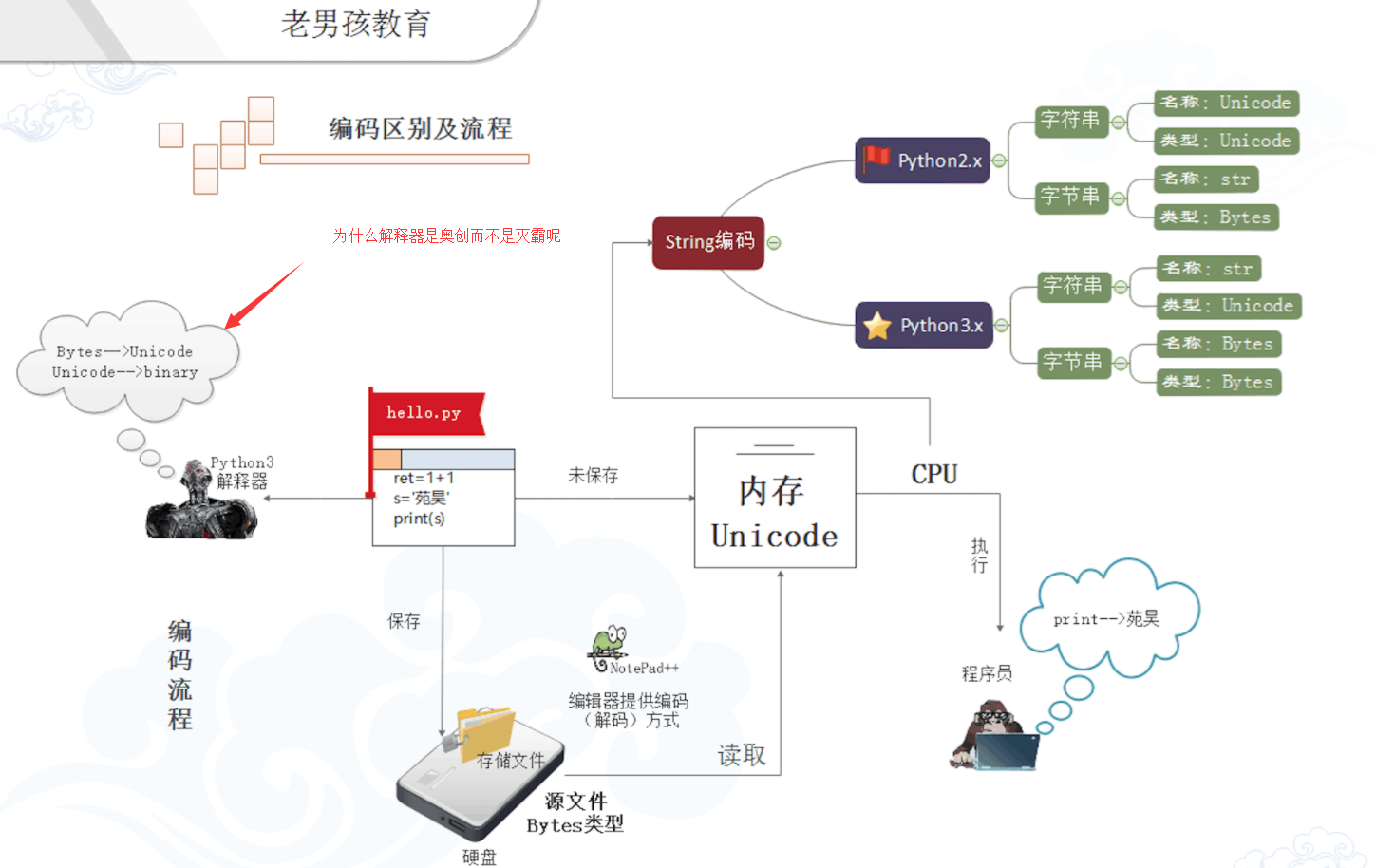
补充:
Python的工作过程
python 把代码读到内存 2、词法语法分析 3、放到编译器 ---> 生成字节码 4、执行字节码 --->生成机器码 CPU执行。
运行Python代码时,如果导入了其他的 .py 文件,那么,执行过程中会自动生成一个与其同名的 .pyc 文件,该文件就是Python解释器编译之后产生的字节码。ps:代码经过编译可以产生字节码;字节码通过反编译也可以得到代码。(任何字节码通过反编译都可以得到代码)。
参考资料:
http://www.cnblogs.com/luotianshuai/p/4931009.html
http://www.cnblogs.com/luotianshuai/articles/5735051.html
http://www.cnblogs.com/yuanchenqi/articles/5956943.html
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
https://www.zhihu.com/question/20650946
关于Python编码问题小记的更多相关文章
- python编码小记
Python编码小记 标签(空格分隔): 编程 python 1.list类型remove()操作 列表对象执行remove()函数后,会自动退出循环,所以如果想利用一个单独的for循环删除列表中多个 ...
- Python cx_Oracle 安装小记
因为我的个人网站 restran.net 已经启用,博客园的内容已经不再更新.请访问我的个人网站获取这篇文章的最新内容,Python cx_Oracle 安装小记 SQLAlchemy 是 Pytho ...
- (转载) 浅谈python编码处理
最近业务中需要用 Python 写一些脚本.尽管脚本的交互只是命令行 + 日志输出,但是为了让界面友好些,我还是决定用中文输出日志信息. 很快,我就遇到了异常: UnicodeEncodeError: ...
- Python 编码简单说
先说说什么是编码. 编码(encoding)就是把一个字符映射到计算机底层使用的二进制码.编码方案(encoding scheme)规定了字符串是如何编码的. python编码,其实就是对python ...
- Python之路3【知识点】白话Python编码和文件操作
Python文件头部模板 先说个小知识点:如何在创建文件的时候自动添加文件的头部信息! 通过:file--settings 每次都通过file--setings打开设置页面太麻烦了!可以通过:View ...
- python编码规范
python编码规范 文件及目录规范 文件保存为 utf-8 格式. 程序首行必须为编码声明:# -*- coding:utf-8 -*- 文件名全部小写. 代码风格 空格 设置用空格符替换TAB符. ...
- 【转】python编码的问题
摘要: 为了在源代码中支持非ASCII字符,必须在源文件的第一行或者第二行显示地指定编码格式: # coding=utf-8 或者是: #!/usr/bin/python # -*- coding: ...
- 【转】python编码规范
http://blog.csdn.net/willhuo/article/details/49300441 决定开始Python之路了,利用业余时间,争取更深入学习Python.编程语言不是艺术,而是 ...
- python 编码 UnicodeDecodeError
将一个py脚本从Centos转到win运行,出错如下: UnicodeDecodeError: 'gbk' codec can't decode byte 0xff in position 0: il ...
随机推荐
- HashMap,HashTable,concurrentHashMap,LinkedHashMap 区别
HashMap 不是线程安全的 HashTable,concurrentHashMap 是线程安全 HashTable 底层是所有方法都加有锁(synchronized) 所以操作起来效率会低 con ...
- UVA10054_The Necklace
很简单,求欧拉回路.并且输出. 只重点说一下要用栈来控制输出. 为啥,如图: 如果不用栈,那么1->2->3->1就回来了,接着又输出4->5,发现这根本连接不上去,所以如果用 ...
- ldap禁止匿名用户登录
此处默认ldap已经安装完成,安装文档传送门:https://www.cnblogs.com/crysmile/p/9470508.html openldap默认安装完成,是允许匿名用户登录的,因此需 ...
- 整理:python的二维数组操作
Python中初始化一个5 x 3每项为0的数组,最好方法是: multilist = [[0 for col in range(5)] for row in range(3)] 如果初始化一个二维数 ...
- [NOI2016]旷野大计算
Subtask0 造计算机神题.给一个忠告:珍爱生命,远离旷野大计算...... 代码在这里:戳我 Subtask1 给定\(a,b\):求\(-2a-2b\). 熟悉操作环境:\([-(a+b)]& ...
- [CF1110E]Magic Stones
题目大意:有一个长度为$n(n\leqslant10^5)$的数列$c$,问是否可以经过若干次变换变成数列$t$,一次变换为$c'_i=c_{i+1}+c_{i-1}-c_i$ 题解:思考一次变换的本 ...
- LEP所需环境
一.LEP所需环境 Python 3.6 Flask Docker 二.Python安装 LEP必须在Python3.6环境下运行,如果是在Python2.7下运行会报以下错误! Python3.6的 ...
- java之初学线程
线程 学习线程相关的笔记,前面写过关于很多线程的使用,有兴趣的可以去了解下 线程 概念理解 并发 : 指两个或多个事件在同一个时间段内发生(交替执行). 并行 : 指两个或多个事件在同一时刻发生(同时 ...
- bzoj4427【Nwerc2015】Cleaning Pipes清理管道
题目描述 Linköping有一个相当复杂的水资源运输系统.在Linköping周围的出水点有一些水井.这些水通过管道输送到其它地点.每条管道是从某一个水井到城市的某个位置的直线管道. 所有管道在地下 ...
- config之安全(用户认证)
config server 端: 配置账号密码: 那么config client如何连接带有认证的config server呢? 假设两个同时使用,属性的优先级比uri的优先级高.