【转】到底什么时候应该用MQ
原文地址:http://zhuanlan.51cto.com/art/201704/536407.htm
一、缘起
一切脱离业务的架构设计与新技术引入都是耍流氓。
引入一个技术之前,首先应该解答的问题是,这个技术解决什么问题。
就像微服务分层架构之前,应该首先回答,为什么要引入微服务,微服务究竟解决什么问题(详见《互联网架构为什么要做微服务?》)。
最近分享了几篇MQ相关的文章:
- 《MQ如何实现延时消息》
- 《MQ如何实现消息必达》
- 《MQ如何实现幂等性》
不少网友询问,究竟什么时候使用MQ,MQ究竟适合什么场景,故有了此文。
二、MQ是干嘛的
消息总线(Message Queue),后文称MQ,是一种跨进程的通信机制,用于上下游传递消息。
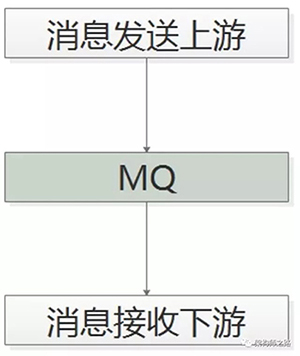
在互联网架构中,MQ是一种非常常见的上下游“逻辑解耦+物理解耦”的消息通信服务。
使用了MQ之后,消息发送上游只需要依赖MQ,逻辑上和物理上都不用依赖其他服务。
三、什么时候不使用消息总线

既然MQ是互联网分层架构中的解耦利器,那所有通讯都使用MQ岂不是很好?这是一个严重的误区,调用与被调用的关系,是无法被MQ取代的。
MQ的不足是:
- 系统更复杂,多了一个MQ组件
- 消息传递路径更长,延时会增加
- 消息可靠性和重复性互为矛盾,消息不丢不重难以同时保证
- 上游无法知道下游的执行结果,这一点是很致命的
举个栗子:用户登录场景,登录页面调用passport服务,passport服务的执行结果直接影响登录结果,此处的“登录页面”与“passport服务”就必须使用调用关系,而不能使用MQ通信。
无论如何,记住这个结论:调用方实时依赖执行结果的业务场景,请使用调用,而不是MQ。
四、什么时候使用MQ
【典型场景一:数据驱动的任务依赖】
什么是任务依赖,举个栗子,互联网公司经常在凌晨进行一些数据统计任务,这些任务之间有一定的依赖关系,比如:
- task3需要使用task2的输出作为输入
- task2需要使用task1的输出作为输入
这样的话,tast1, task2, task3之间就有任务依赖关系,必须task1先执行,再task2执行,载task3执行。
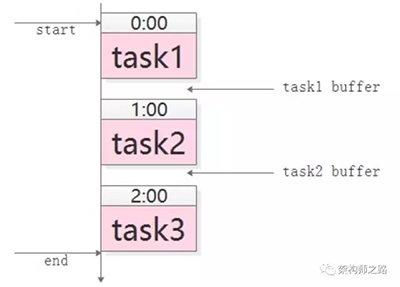
对于这类需求,常见的实现方式是,使用cron人工排执行时间表:
- task1,0:00执行,经验执行时间为50分钟
- task2,1:00执行(为task1预留10分钟buffer),经验执行时间也是50分钟
- task3,2:00执行(为task2预留10分钟buffer)
这种方法的坏处是:
- 如果有一个任务执行时间超过了预留buffer的时间,将会得到错误的结果,因为后置任务不清楚前置任务是否执行成功,此时要手动重跑任务,还有可能要调整排班表
- 总任务的执行时间很长,总是要预留很多buffer,如果前置任务提前完成,后置任务不会提前开始
- 如果一个任务被多个任务依赖,这个任务将会称为关键路径,排班表很难体现依赖关系,容易出错
- 如果有一个任务的执行时间要调整,将会有多个任务的执行时间要调整
无论如何,采用“cron排班表”的方法,各任务耦合,谁用过谁痛谁知道(采用此法的请评论留言)
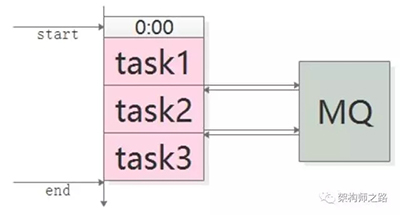
优化方案是,采用MQ解耦:
- task1准时开始,结束后发一个“task1 done”的消息
- task2订阅“task1 done”的消息,收到消息后第一时间启动执行,结束后发一个“task2 done”的消息
- task3同理
采用MQ的优点是:
- 不需要预留buffer,上游任务执行完,下游任务总会在第一时间被执行
- 依赖多个任务,被多个任务依赖都很好处理,只需要订阅相关消息即可
- 有任务执行时间变化,下游任务都不需要调整执行时间
需要特别说明的是,MQ只用来传递上游任务执行完成的消息,并不用于传递真正的输入输出数据。
【典型场景二:上游不关心执行结果】
上游需要关注执行结果时要用“调用”,上游不关注执行结果时,就可以使用MQ了。
举个栗子,58同城的很多下游需要关注“用户发布帖子”这个事件,比如招聘用户发布帖子后,招聘业务要奖励58豆,房产用户发布帖子后,房产业务要送2个置顶,二手用户发布帖子后,二手业务要修改用户统计数据。
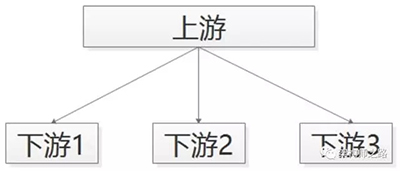
对于这类需求,常见的实现方式是,使用调用关系:
帖子发布服务执行完成之后,调用下游招聘业务、房产业务、二手业务,来完成消息的通知,但事实上,这个通知是否正常正确的执行,帖子发布服务根本不关注。
这种方法的坏处是:
- 帖子发布流程的执行时间增加了
- 下游服务当机,可能导致帖子发布服务受影响,上下游逻辑+物理依赖严重
- 每当增加一个需要知道“帖子发布成功”信息的下游,修改代码的是帖子发布服务,这一点是最恶心的,属于架构设计中典型的依赖倒转,谁用过谁痛谁知道(采用此法的请评论留言)
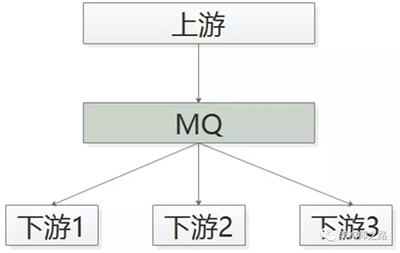
优化方案是,采用MQ解耦:
- 帖子发布成功后,向MQ发一个消息
- 哪个下游关注“帖子发布成功”的消息,主动去MQ订阅
采用MQ的优点是:
- 上游执行时间短
- 上下游逻辑+物理解耦,除了与MQ有物理连接,模块之间都不相互依赖
- 新增一个下游消息关注方,上游不需要修改任何代码
典型场景三:上游关注执行结果,但执行时间很长
有时候上游需要关注执行结果,但执行结果时间很长(典型的是调用离线处理,或者跨公网调用),也经常使用回调网关+MQ来解耦。
举个栗子,微信支付,跨公网调用微信的接口,执行时间会比较长,但调用方又非常关注执行结果,此时一般怎么玩呢?
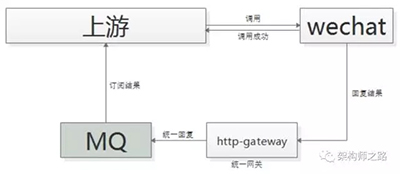
一般采用“回调网关+MQ”方案来解耦:
- 调用方直接跨公网调用微信接口
- 微信返回调用成功,此时并不代表返回成功
- 微信执行完成后,回调统一网关
- 网关将返回结果通知MQ
- 请求方收到结果通知
这里需要注意的是,不应该由回调网关来调用上游来通知结果,如果是这样的话,每次新增调用方,回调网关都需要修改代码,仍然会反向依赖,使用回调网关+MQ的方案,新增任何对微信支付的调用,都不需要修改代码啦。
五、总结
MQ是一个互联网架构中常见的解耦利器。
什么时候不使用MQ?
- 上游实时关注执行结果
什么时候使用MQ?
- 数据驱动的任务依赖
- 上游不关心多下游执行结果
- 异步返回执行时间长
【本文为51CTO专栏作者“58沈剑”原创稿件,转载请联系原作者】
【转】到底什么时候应该用MQ的更多相关文章
- 到底什么时候该使用MQ?
一.缘起 一切脱离业务的架构设计与新技术引入都是耍流氓. 引入一个技术之前,首先应该解答的问题是,这个技术解决什么问题. 就像微服务分层架构之前,应该首先回答,为什么要引入微服务,微服务究竟解决什么问 ...
- 架构-到底什么时候该使用MQ【转】
点击:<查看原文> 一.缘起 一切脱离业务的架构设计与新技术引入都是耍流氓. 引入一个技术之前,首先应该解答的问题是,这个技术解决什么问题. 就像微服务分层架构之前,应该首先回答,为什么要 ...
- 170317、到底什么时候该使用MQ?
一.缘起 一切脱离业务的架构设计与新技术引入都是耍流氓. 引入一个技术之前,首先应该解答的问题是,这个技术解决什么问题. 就像微服务分层架构之前,应该首先回答,为什么要引入微服务,微服务究竟解决什么问 ...
- 为什么要使用MQ和到底什么时候要使用MQ
一.缘起 一切脱离业务的架构设计与新技术引入都是耍流氓. 引入一个技术之前,首先应该解答的问题是,这个技术解决什么问题. 就像微服务分层架构之前,应该首先回答,为什么要引入微服务,微服务究竟解决什 ...
- MQ(转)
1. 到底什么时候该使用MQ? 1). 典型场景一:数据驱动的任务依赖 采用MQ的优点是: a. 不需要预留buffer,上游任务执行完,下游任务总会在第一时间被执行 b. 依赖多个任务,被多个任务依 ...
- 初识MQ
[参考文章]:到底什么时候该使用MQ? 1. 什么是MQ? 消息队列(Message Quene)是一种跨进程的通信机制,用于上下游传递消息. MQ是一种非常常见的上下游“逻辑解耦+物理解耦”的消息通 ...
- mq使用场景、不丢不重、时序性
mq使用场景.不丢不重.时序性.削峰 参考: http://zhuanlan.51cto.com/art/201704/536407.htm http://zhuanlan.51cto.com/art ...
- 170331、58到家MQ如何快速实现流量削峰填谷
问:为什么会有本文? 答:上一篇文章<到底什么时候该使用MQ?>引起了广泛的讨论,有朋友回复说,MQ的还有一个典型应用场景是缓冲流量,削峰填谷,本文将简单介绍下,MQ要实现什么细节,才能缓 ...
- 多维度对比5款主流分布式MQ消息队列,妈妈再也不担心我的技术选型了
1.引言 对于即时通讯网来说,所有的技术文章和资料都在围绕即时通讯这个技术方向进行整理和分享,这一次也不例外.对于即时通讯系统(包括IM.消息推送系统等)来说,MQ消息中件间是非常常见的基础软件,但市 ...
随机推荐
- day65 Django模板语言
常用语法 只需要记两种特殊符号: {{ }}和 {% %} 变量相关的用{{}},逻辑相关的用{%%}. 变量 {{ 变量名 }} 变量名由字母数字和下划线组成. 点(.)在模板语言中有特殊的含 ...
- day 60 Django第一天
jinjia2 : Jinja2是基于python的模板引擎,功能比较类似于于PHP的smarty,J2ee的Freemarker和velocity. 它能完全支持unicode,并具有集成的沙箱执行 ...
- Weekly Contest 131
1021. Remove Outermost Parentheses A valid parentheses string is either empty (""), " ...
- bonjour browser 下载
在Mac 上叫 Bonjour Browser http://www.macupdate.com/app/mac/13388/bonjour-browser/download IOS 上的 app 叫 ...
- 数组序列化serialize
1,数据在网络中是以字符串形式传输,这样如果传输的是数组,首先将数组内容拼接成字符串进行发送,接收方拿到字符串,没法将其还原为数组.因此在网络传输的时候,为了保证数据类型的不丢失,先序列化,再发送. ...
- (6)Oracle基础--简单查询
.基本查询语句 SELECT [DISTINCT] column_name1,... | * FROM table_name [WHERE conditions]; P: DISTINCT关键字的作 ...
- ASP.NET MVC Forms验证机制
ASP.NET MVC 3 使用Forms身份验证 身份验证流程 一.用户登录 1.验证表单:ModelState.IsValid 2.验证用户名和密码:通过查询数据库验证 3.如果用户名和密码正确, ...
- iOS开发--应用国际化,应用内切换语言
1.前言 自己负责的项目需要做国际化,并且要求应用内部切换语言.这个是可以做到的,也并不难,可以直接戳Github看一下 https://github.com/leo90821/Localiztion ...
- 【LeetCode】414. 第三大的数
给定一个非空数组,返回此数组中第三大的数.如果不存在,则返回数组中最大的数.要求算法时间复杂度必须是O(n). 示例 1: 输入: [3, 2, 1] 输出: 1 解释: 第三大的数是 1. 示例 2 ...
- jQuery过滤选择器:first和:first-child的区别,CSS伪类:first-child
最近项目中遇到需求:只在第一列不能删除,不显示小叉号:点击可添加一列,后面的列右上角显示小叉号,可以点击删除. 我是使用以下方法解决这个小需求 :CSS伪类选择器:first-child设置所有小叉号 ...