elasticsearch 分布式集群搭建
elasticsearch环境搭建及单节点搭建可参考我的上一篇:http://www.cnblogs.com/xuwenjin/p/8745624.html
本文以Elaticsearch 6.2.2 版本为基础,讲解Elasticsearch三个节点的分布式部署、核心配置的含义以及分布式部署遇到的坑
楼主是在一台机器上配置的,所有下面的network.host全部配置同一IP
1、配置节点
1.1配置主节点:
#集群名称
cluster.name: xwj #节点名称
node.name: master #是否参与master选举
node.master: true #绑定的ip
network.host: 127.0.0.1 #默认端口
http.port: #解决跨域-这样head插件就可以访问
http.cors.enabled: true
http.cors.allow-origin: "*"
1.2 将elasticsearch的压缩包解压两次,分别解压到两个文件夹中。然后分别修改配置文件
随从节点slave1的配置:
#集群名称
cluster.name: xwj #节点名称
node.name: slave1 #绑定的ip
network.host: 127.0.0.1 #默认端口已使用,这里用新的端口
http.port: #发现主节点(通过主节点的ip)
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
随从节点slave2跟节点slave1配置很像,就端口号和节点名称不一样。如下图:
#集群名称
cluster.name: xwj #节点名称
node.name: slave2 #绑定的ip
network.host: 127.0.0.1 #默认端口已使用,这里用新的端口
http.port: #发现主节点(通过主节点的ip)
discovery.zen.ping.unicast.hosts: ["127.0.0.1"]
2、启动服务
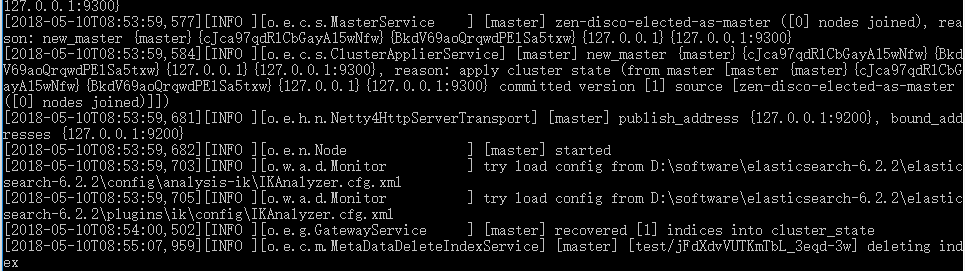
2.1 启动主节点,会发现节点名称为master为主节点
2.2 分别启动slave1和slave2

在slave启动的过程中,通过上面打印信息,可以看到slave1发现了主节点master及另一个随从节点slave2(先启动)。此时主节点也会发现另两个节点加入进来
2.3 部署成功示例:
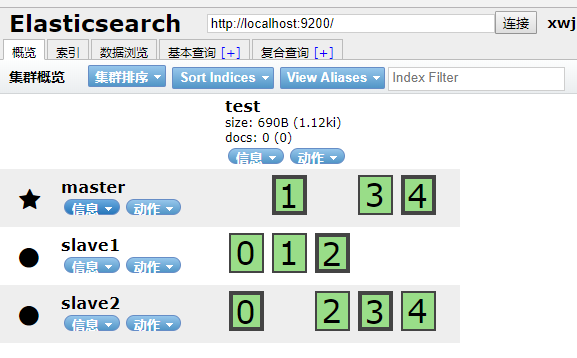
五角星的为主节点,圆点的为随从节点。
默认5个分片,一个备份(粗线框框为分片,细线的为备份分片)。可以看到,三个节点平均分配所有分片及备份
3、部署节点原理
多机集群中的节点可以分为master nodes和data nodes,在配置文件中使用Zen发现(Zen discovery)机制来管理不同节点。Zen发现是ES自带的默认发现机制,使用
多播发现其它节点。只要启动一个新的ES节点并设置和集群相同的名称这个节点就会被加入到集群中。(所以,同集群的集群名称一致,才能便于自动发现)
Elasticsearch集群中有的节点一般有三种角色:master node、data node和client node。
1)master node——master节点点主要用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等。
2)data node——data 节点上保存了数据分片。它负责数据相关操作,比如分片的 CRUD,以及搜索和整合操作。这些操作都比较消耗 CPU、内存和 I/O 资源;
2)client node——client 节点起到路由请求的作用,实际上可以看做负载均衡器。
4、其它参数含义
#分片数和副本数#master选举最少的节点数,这个一定要设置为N/2+1,其中N是:具有master资格的节点的数量,而不是整个集群节点个数
index.number_of_shards: 5
index.number_of_replicas: 1
discovery.zen.mininum_master_nodes: 2 #discovery ping的超时时间,拥塞网络,网络状态不佳的情况下设置高一点
discovery.zen.ping.timeout: 3s #关闭自动发现节点
discovery.zen.ping.multicast.enabled: false #定义发现的节点
discovery.zen.ping.unicast.hosts: ["192.168.1.1:9201", "192.168.1.1:9202"]
注意:分布式系统整个集群节点个数N要为奇数个!!
5、踩过的坑:
1、增加节点时,直接将启动成功的elasticsearch文件夹拷贝,然后修改配置文件。这样在启动的时候,会报已有一个相同节点id却不同实例,导致无法进入到集
群中
原因:成功启动后,会在data文件目录下,生成该节点的信息
正确做法:解压elasticsearch的压缩包,然后再改配置文件。或者复制后,删除data文件目录下的数据
elasticsearch 分布式集群搭建的更多相关文章
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- Hadoop分布式集群搭建
layout: "post" title: "Hadoop分布式集群搭建" date: "2017-08-17 10:23" catalog ...
- hbase分布式集群搭建
hbase和hadoop一样也分为单机版.伪分布式版和完全分布式集群版本,这篇文件介绍如何搭建完全分布式集群环境搭建. hbase依赖于hadoop环境,搭建habase之前首先需要搭建好hadoop ...
- Elastic Stack之ElasticSearch分布式集群二进制方式部署
Elastic Stack之ElasticSearch分布式集群二进制方式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家都知道ELK其实就是Elasticsearc ...
- 分布式实时日志系统(四) 环境搭建之centos 6.4下hbase 1.0.1 分布式集群搭建
一.hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
- kafka系列二:多节点分布式集群搭建
上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法.多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建. 一.安装Jdk 具体安 ...
随机推荐
- 设计模式--Singleton_(1)(C#版)
今天我们来探索一下Singleton设计模式的实现及应用场景. Singleton模式属于Creational Type(创建型)设计模式的一种.该模式一般用于确保在应用中仅创建一个某类的instan ...
- 用.netcore写一个简单redis驱动,调试windows版本的redis.平且给set和get命令添加参数.
1. 下载windows版本的redis 2.开发环境vs2017 新建一个 .net core控制台. private static Socket socket = new Socket(Addr ...
- C# wpf InkCanvas 保存图片jpg
前端xaml页面代码 <Window x:Class="WpfApplication6.MainWindow" xmlns="http://schemas.micr ...
- ASP.NET MVC 实现带论坛功能的网站 第一步——-实现用户注册.
首先我们要实现用户的注册功能.进入visual studio 点击文件->新建->项目->选择ASP.NET Web应用程序(.NET Framework)->选择的模板为MV ...
- 646. Maximum Length of Pair Chain
You are given n pairs of numbers. In every pair, the first number is always smaller than the second ...
- NRF52840相对于之前的NRF52系列、NRF51系列增加了什么功能
现在广大客户的蓝牙采用NORDIC越来越多了,NORDIC一直在不断进行技术改进更好的满足市场需求 推出了新款NRF52840.NRF52840更为先进些,支持的功能也多点,比如IEEE802.15. ...
- 《Python黑帽子:黑客与渗透测试编程之道》 网络:原始套接字和流量嗅探
Windows和Linux上的包嗅探: #!/usr/bin/python import socket import os #监听的主机 host = "10.10.10.160" ...
- Codeforces Round #456 (Div. 2) B. New Year's Eve
B. New Year's Eve time limit per test 1 second memory limit per test 256 megabytes input standard in ...
- win7下oracle的安装
1.参考地址1:http://www.cnblogs.com/libiao/archive/2008/08/24/1275000.html 2.参考地址2:http://www.server110.c ...
- day 42 mysql 数据库(2)
前情提要: 本节继续学习数据库 一:ddl 创建表 >字段名 >数据类型 >约束规则 >显示建表语句 修改表: 二:数据类型 >数值类型 >小数类型 >字 ...