python学习(25) BeautifulSoup介绍和实战
BeautifulSoup是python的html解析库,处理html非常方便
BeautifulSoup 安装
pip install beautifulsoup4
BeautifulSoup 配合的解析器
# python标准库
BeautifulSoup(html,'html.parser')
#lxml HTML 解析器
BeautifulSoup(html,'lxml)
#html5lib
BeautifulSoup(html,'html5lib')
python 标准库解析器不需要第三方库,处理效率一般,lxml比较快,需要C语言库支持,html5lib不依赖第三方库,但是效率比较低,容错好。
导入BeautifulSoup并使用
from bs4 import BeautifulSoup
html = '''div id="sslct_menu" class="cl p_pop" style="display: none;">
<span class="sslct_btn" onClick="extstyle('')" title="默认"><i></i></span></div>
<ul id="myitem_menu" class="p_pop" style="display: none;">
<li><a href="https://www.aisinei.org/forum.php?mod=guide&view=my">帖子</a></li>
<li><a href="https://www.aisinei.org/home.php?mod=space&do=favorite&view=me">收藏</a></li>'''
bs = BeautifulSoup(html)
print(bs.prettify())
bs.prettify为格式化输出,效果如下

同样可以用本地的html文本创建,也可以添加解析器lxml
s =BeautifulSoup('test.html','lxml')
print(s.prettify())
效果是一样的
BeautifulSoup属性选择和处理
处理节点tag
html2 = ''' <li class="bus_postbd item masonry_brick">
<div class="bus_vtem">
<a href="https://www.aisinei.org/thread-17846-1-1.html" title="XIUREN秀人网 2018.11.13 NO.1228 猫宝 [50+1P]" class="preview" target="_blank">
"hello world"
<img src="https://i.asnpic.win/block/a4/a42e6c63ef1ae20a914699f183d5204b.jpg" width="250" height="375" alt="XIUREN秀人网 2018.11.13 NO.1228 猫宝 [50+1P]"/>
<span class="bus_listag">XIUREN秀人网</span>
</a>
<a href="https://www.aisinei.org/thread-17846-1-1.html" title="XIUREN秀人网 2018.11.13 NO.1228 猫宝 [50+1P]" target="_blank">
<div class="lv-face"><img src="https://www.aisinei.org/uc_server/avatar.php?uid=2&size=small" alt="发布组小乐"/></div>
<div class="t">XIUREN秀人网 2018.11.13 NO.1228 猫宝 [50</div>
<div class="i"><span><i class="bus_showicon bus_showicon_v"></i>6402</span><span><i class="bus_showicon bus_showicon_r"></i>1</span></div>
</a>
</div>
</li> '''
s2 = BeautifulSoup(html2,'lxml')
print(s2.a)
print(s2.a.name)
print(s2.a.attrs)
节点tag 就是li,a,div这类,可以看出通过属性访问,选择出第一个匹配的结果。节点Tag也有名字,通过.name访问。通过.attrs获取节点的属性。

获取节点文本通过.string即可,获取节点的子孙节点的文本可以通过text
print(s2.a.string)
print(s2.a.text)
节点的子孙节点
获取节点的子节点,可以用.contents,也可以用.children, .contents返回列表形式的直接子节点, .contents返回的是一个可迭代对象。
print(s2.div.contents)
print(s2.div.children)
print(s2.div.contents[0])
for i in s2.div.children:
print(i)
前两个输出一样,后边的分别取第一个节点,以及遍历每一个节点。同样的道理,子孙节点,父节点,祖父节点,兄弟节点都采用这种方式获取
#孙子节点
print(s2.div.descendants)
#祖先节点
print(s2.div.parents)
#直接父节点
print(s2.div.parent)
#下一个兄弟节点
print(s2.a.next_sibling)
#前一个兄弟节点
print(s2.a.previous_sibling)
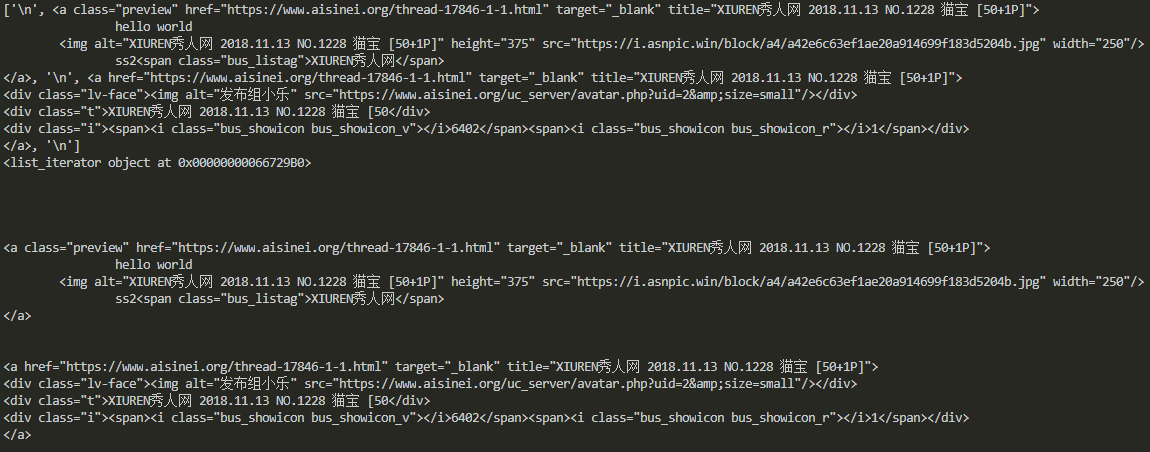
节点的属性获取
print(s2.a["href"])
print(s2.a.get("href"))
如上两种方式都能获取属性

方法选择
常用的筛选函数有find_all和find,findall返回所有匹配的结果,find返回匹配结果的
print(s2.find('a'))
print(s2.find_all('a'))
print(s2.find_all(re.compile("^div")))
print(s2.find_all(["div","li"]))
可以看出findall传递参数可以是字符串,正则表达式,列表等等,其他的方法类似属性访问一样,有find_parents(),find_next_siblings()等等,用的时候再查吧。
BeautifulSoup 支持CSS选择器
如果你熟悉css选择器的语法,BeautifulSoup同样支持,而且非常便利。
#查找节点为div的数据
print(s2.select('a'))
#查找class为bus_vtem的节点
print(s2.select('.bus_vtem'))
#查找id为ps的节点
print(s2.select('#ps'))
到目前为止基本的BeautifulSoup已经介绍完,下面实战抓取一段html,并用BeautifulSoup解析提取我们需要的数据,这里解析一段美女图更新首页,提取其中的资源地址。
#-*-coding:utf-8-*-
import requests
import re
import time
from lxml import etree
from bs4 import BeautifulSoup
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'
COOKIES = '__cfduid=d78f862232687ba4aae00f617c0fd1ca81537854419; bg5D_2132_saltkey=jh7xllgK; bg5D_2132_lastvisit=1540536781; bg5D_2132_auth=479fTpQgthFjwwD6V1Xq8ky8wI2dzxJkPeJHEZyv3eqJqdTQOQWE74ttW1HchIUZpgsyN5Y9r1jtby9AwfRN1R89; bg5D_2132_lastcheckfeed=7469%7C1541145866; bg5D_2132_ulastactivity=2bbfoTOtWWimnqaXyLbTv%2Buq4ens5zcXIiEAhobA%2FsWLyvpXVM9d; bg5D_2132_sid=wF3g17; Hm_lvt_b8d70b1e8d60fba1e9c8bd5d6b035f4c=1540540375,1540955353,1541145834,1541562930; Hm_lpvt_b8d70b1e8d60fba1e9c8bd5d6b035f4c=1541562973; bg5D_2132_lastact=1541562986%09home.php%09spacecp'
class AsScrapy(object):
def __init__(self,pages=1):
try:
self.m_session = requests.Session()
self.m_headers = {'User-Agent':USER_AGENT,
#'referer':'https://www.aisinei.org/',
} self.m_cookiejar = requests.cookies.RequestsCookieJar()
for cookie in COOKIES.split(';'):
key,value = cookie.split('=',1)
self.m_cookiejar.set(key,value)
except:
print('init error!!!')
def getOverView(self):
try:
req = self.m_session.get('https://www.aisinei.org/portal.php',headers=self.m_headers, cookies=self.m_cookiejar, timeout=5)
classattrs={'class':'bus_vtem'}
soup = BeautifulSoup(req.content.decode('utf-8'),'lxml')
buslist = soup.find_all(attrs=classattrs)
#print(len(buslist))
for item in buslist:
if(item.a.attrs['title'] == "紧急通知!紧急通知!紧急通知!"):
continue
print(item.a.attrs['title'])
print(item.a.attrs['href'])
time.sleep(1)
pass
except:
print('get over view error') if __name__ == "__main__":
asscrapy = AsScrapy()
asscrapy.getOverView()
抓取并分析出地址如下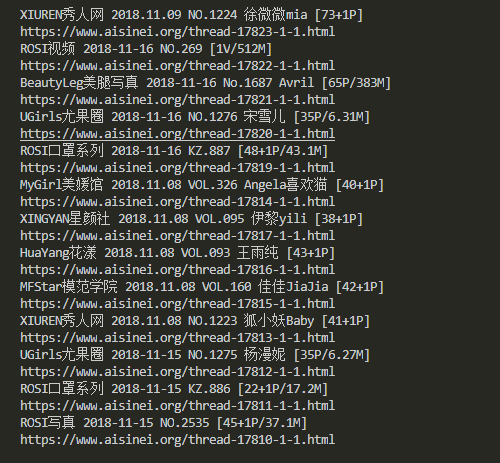
下一篇讲如何利用ajax分析动态网址,实战抓取今日头条的cosplay图片
谢谢关注我的公众号
python学习(25) BeautifulSoup介绍和实战的更多相关文章
- 深度学习框架Keras介绍及实战
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行.Keras 的开发重点是支持快速的实验.能够以最小的时延 ...
- Python开发GUI工具介绍,实战:将图片转化为素描画!
欢迎添加华为云小助手微信(微信号:HWCloud002 或 HWCloud003),输入关键字"加群",加入华为云线上技术讨论群:输入关键字"最新活动",获取华 ...
- python学习之——splinter介绍
Splinter是什么: 是一个用 Python 编写的 Web 应用程序进行验收测试的工具. Splinter执行的时候会自动打开你指定的浏览器,访问指定的URL,然后你所开发的模拟的任何行为,都会 ...
- python学习之----BeautifulSoup的find()和findAll()及四大对象
BeautifulSoup 里的find() 和findAll() 可能是你最常用的两个函数.借助它们,你可以通 过标签的不同属性轻松地过滤HTML 页面,查找需要的标签组或单个标签. 这两个函数非常 ...
- Python学习之路:MINST实战第一版
1.项目介绍: 搭建浅层神经网络完成MNIST数字图像的识别. 2.详细步骤: (1)将二维图像转成一维,MNIST图像大小为28*28,转成一维就是784. (2)定义好神经网络的相关参数: # M ...
- Python开发GUI工具介绍,实战:将图片转化为素描画!【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
- python学习之BeautifulSoup模块爬图
BeautifulSoup模块爬图学习HTML文本解析标签定位网上教程多是爬mzitu,此网站反爬限制多了.随意找了个网址,解析速度有些慢.脚本流程:首页获取总页数-->拼接每页URL--> ...
- GO学习-(25) Go操作Redis实战
Go操作Redis实战 安装Redis客户端 Go语言中使用第三方库https://github.com/go-redis/redis连接Redis数据库并进行操作.使用以下命令下载并安装: go ...
- Python学习(25):Python执行环境
转自 http://www.cnblogs.com/BeginMan/p/3191856.html 一.python特定的执行环境 在当前脚本继续进行 创建和管理子进程 执行外部命令或程序 执行需要输 ...
随机推荐
- Nginx 配置优化
一.开启Gzip 1.参数 gzip on;gzip_min_length 1k;gzip_buffers 4 16k;gzip_comp_level 2;gzip_types text/plain ...
- React的setState分析
前端框架层出不穷,不过万变不离其宗,就是从MVC过渡到MVVM.从数据映射到DOM,angular中用的是watcher对象,vue是观察者模式,react就是state了. React通过管理状态实 ...
- 欢迎来怼--第二十二次Scrum会议
欢迎来怼--第二十二次Scrum会议 一.小组信息 队名:欢迎来怼 小组成员 队长:田继平 成员:李圆圆,葛美义,王伟东,姜珊,邵朔,阚博文 小组照片 二.开会信息 时间:2017/11/10 17: ...
- No.1100_第九次团队会议
在今天项目有了新的突破,大家的情绪明显高涨了一些,一改往日的颓丧.但是仍然还有很多功能没有完善,于是大家相互交流了一下自己的进度,列出还没有完善的部分,有些困难的部分一时解决不了,我们决定多人合作来解 ...
- 【Alpha】阶段第八次Scrum Meeting
[Alpha]阶段第八次Scrum Meeting 工作情况 团队成员 今日已完成任务 明日待完成任务 刘峻辰 编写按学院搜索课程接口 编写获得所有学院接口 赵智源 构建前测试点测试框架 编写alph ...
- 20135234mqy 实验三:敏捷开发与XP实践
实 验 报 告 课程:Java 班级: 1352 姓名:mqy 学号:20135234 成绩: 指导教师:娄嘉鹏 实验日期:2015. ...
- Java第一次试验
北京电子科技学院(BESTI) 实 验 报 告 课程:Java程序设计 班级:1352 姓名:朱国庆 学号:20135237 成绩: ...
- 关于rand()函数 转载于其他人
C++中的rand()函数 分类: 编程语言/ C#/ 文章 C++中产生随机数种子对于初学者一直都很困惑.大家知道,在C中有专门的srand(N)函数可以轻松实现这一功能,然而在C++中则要复杂一些 ...
- 项目Beta冲刺(团队)第三天
1.昨天的困难 记住密码打勾之后点击登录记住密码这四个字会变成省略号 点赞点击以后本应该呈现的爱心形状变成了方块 2.今天解决的进度 成员 进度 陈家权 私信模块探索ing,回复详情界面设计 赖晓连 ...
- 用jar包运行带GUI的java游戏
这是从某论坛下载的java游戏demo,由于年代久远,所以没有记下出处.重要的是,这是一个带GUI的java程序. 链接: https://pan.baidu.com/s/1LjQ2bQPXvW-ti ...