Java基础-正则表达式(Regular Expression)语法规则简介
Java基础-正则表达式(Regular Expression)语法规则简介
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.正则表达式的概念
正则表达式(Regular Expression,在代码中常简写为regex)是一个字符串,使用单个字符串来描述,用来定义匹配规则,匹配一系列符合某个句法规则的字符串。在开发中,正则表达式通常被用来检索,替换那些符合某个规则的文本。
二.正则表达式常用的匹配规则
再看Java的API帮助文档,在pattern类中有正则表达式的规则定义,正则表达式中明确区分大小写字母。接下来我们就来说一些Java常用的字符吧。
1>.字符"x"
含义:代表的是字符‘x’。
例如:匹配规则为“a”,那么匹配的字符传内容就是"a"。
2>.字符“\\”
含义:代表的反斜线字符‘\’(前面的"\"是转义的作用,被转的是“\”,后面的"\"被转义为了普通的斜线,失去了转义的作用)。
例如:匹配规则为“\\",那么需要匹配的字符串内容就是“\”。
3>.字符"\t"
含义:制表符(前面的“\”是转义的作用)。
例如:匹配规则为“\t”,那么对应的效果就是产生一个制表符的空间。
4>.字符“\n”
含义:换行符.
例如:匹配规则为“\n”,那么对应的效果就是换行,光标在原有位置的下一行。
5>.字符“\r”
含义:回车符。
例如:匹配规则为“\r”,那么对应的效果就是回车后的效果,光标来到下一行行首。
6>.字符类"[abc]"
含义:代表的是字符'a','b','c'。
例如:匹配规则为“[abc]”,那么需要匹配的内容就是字符a,或者字符b,或字符c的其中一个。
7>.字符类"[^abc]"
含义:代表的是除了a,b或c以外的任何字符。
例如:匹配规则为“[^abc]”,那么需要匹配的内容就是不是字符‘a’,或者不是字符'b',或不是字符‘c’的任意一个字符。
8>.字符类"[a-zA-Z]"
含义:带包的是a到z或A到Z,两头的字母包括再内。
例如:匹配规则为“[a-zA-Z]”,那么需要匹配的是一个大写或者小写字母。
9>.字符类"[0-9]"
含义:代表的是0到9数字,两个的数字包括在内。
例如:匹配规则为“[0-9]”,那么需要匹配的是一个数字。
10>.字符类"[a-zA-Z_0-9]"
含义:代表的字母或者数字或者下划线(即单词字符)。
例如:匹配规则为"[a-zA-Z_0-9]",那么需要匹配的是一个字母或者是一个数字或者一个下划线。
11>.预定义字符类“.”
含义:代表的是任何字符。
例如:匹配规则为“.”,那么需要匹配的是一个任意字符。如果就想使用“.”的话,使用匹配规则"\\."来实现。
12>.预定义字符类“\d”
含义:代表的是的是0到9数字,两头的数字包括在内,相当于[0-9]。
例如:匹配规则为“\d”,那么需要匹配的是一个数字。
13>.预定义字符类“\w”
含义:代表的字母或者数字或者下划线(即单词字符),相当于[a-zA-Z_0-9]。
例如:匹配规则为“\w”,那么需要匹配的是一个字母或者是一个数字或者一个下滑线。
14>.边界匹配器“^”
含义:代表的是行的开头。
例如:匹配规则为“^[abc][0-9]$”,那么需要匹配的内容从[abc]这个位置开始,相当于左双引号。
15>.边界匹配器"$"
含义:代表的是行的结尾。
例如:匹配规则为“\b[abc]\b”,那么代表的是字母a或b或c的左右两边需要的是非单词字符([a-zA-z_0-9])。
16>.数量词"x?"
含义:代表的是x出现一次或一次的也没有。
例如:匹配规则为“a?”,那么需要匹配的内容是多个字符‘a’,或者一个'a'都没有。
17>.数量词“x*”
含义:代表的是x出现零次或多次。
例如:匹配规则为“a*”,那么需要匹配的内容是多个字符'a',或者一个'a'。
18>.数量词“x+”
含义:代表的是x出现一次或多次
例如:匹配规则为“a+”,那么需要匹配的内容是多个字符'a',或者一个‘a’。
19>.数量词“X{n}”
含义:代表的是x出现恰好n次。
例如:匹配规则为“a{5}”,那么需要匹配的内容是5个字符‘a’。
20>.数量词“X{n,}”
含义:代表的是X出现至少n次。
例如:匹配规则为“a{5,8}”,那么需要匹配的内容是有5个字符‘a’到8个字符‘a’之间。
构造 匹配 字符
x 字符 x
\\ 反斜线字符
\0n 带有八进制值 0 的字符 n (0 <= n <= 7)
\0nn 带有八进制值 0 的字符 nn (0 <= n <= 7)
\0mnn 带有八进制值 0 的字符 mnn(0 <= m <= 3、0 <= n <= 7)
\xhh 带有十六进制值 0x 的字符 hh
\uhhhh 带有十六进制值 0x 的字符 hhhh
\t 制表符 ('\u0009')
\n 新行(换行)符 ('\u000A')
\r 回车符 ('\u000D')
\f 换页符 ('\u000C')
\a 报警 (bell) 符 ('\u0007')
\e 转义符 ('\u001B')
\cx 对应于 x 的控制符 字符类
[abc] a、b 或 c(简单类)
[^abc] 任何字符,除了 a、b 或 c(否定)
[a-zA-Z] a 到 z 或 A 到 Z,两头的字母包括在内(范围)
[a-d[m-p]] a 到 d 或 m 到 p:[a-dm-p](并集)
[a-z&&[def]] d、e 或 f(交集)
[a-z&&[^bc]] a 到 z,除了 b 和 c:[ad-z](减去)
[a-z&&[^m-p]] a 到 z,而非 m 到 p:[a-lq-z](减去) 预定义字符类
. 任何字符(与行结束符可能匹配也可能不匹配)
\d 数字:[0-9]
\D 非数字: [^0-9]
\s 空白字符:[ \t\n\x0B\f\r]
\S 非空白字符:[^\s]
\w 单词字符:[a-zA-Z_0-9]
\W 非单词字符:[^\w] POSIX 字符类(仅 US-ASCII)
\p{Lower} 小写字母字符:[a-z]
\p{Upper} 大写字母字符:[A-Z]
\p{ASCII} 所有 ASCII:[\x00-\x7F]
\p{Alpha} 字母字符:[\p{Lower}\p{Upper}]
\p{Digit} 十进制数字:[0-9]
\p{Alnum} 字母数字字符:[\p{Alpha}\p{Digit}]
\p{Punct} 标点符号:!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
\p{Graph} 可见字符:[\p{Alnum}\p{Punct}]
\p{Print} 可打印字符:[\p{Graph}\x20]
\p{Blank} 空格或制表符:[ \t]
\p{Cntrl} 控制字符:[\x00-\x1F\x7F]
\p{XDigit} 十六进制数字:[0-9a-fA-F]
\p{Space} 空白字符:[ \t\n\x0B\f\r] java.lang.Character 类(简单的 java 字符类型)
\p{javaLowerCase} 等效于 java.lang.Character.isLowerCase()
\p{javaUpperCase} 等效于 java.lang.Character.isUpperCase()
\p{javaWhitespace} 等效于 java.lang.Character.isWhitespace()
\p{javaMirrored} 等效于 java.lang.Character.isMirrored() Unicode 块和类别的类
\p{InGreek} Greek 块(简单块)中的字符
\p{Lu} 大写字母(简单类别)
\p{Sc} 货币符号
\P{InGreek} 所有字符,Greek 块中的除外(否定)
[\p{L}&&[^\p{Lu}]] 所有字母,大写字母除外(减去) 边界匹配器
^ 行的开头
$ 行的结尾
\b 单词边界
\B 非单词边界
\A 输入的开头
\G 上一个匹配的结尾
\Z 输入的结尾,仅用于最后的结束符(如果有的话)
\z 输入的结尾 Greedy 数量词
X? X,一次或一次也没有
X* X,零次或多次
X+ X,一次或多次
X{n} X,恰好 n 次
X{n,} X,至少 n 次
X{n,m} X,至少 n 次,但是不超过 m 次 Reluctant 数量词
X?? X,一次或一次也没有
X*? X,零次或多次
X+? X,一次或多次
X{n}? X,恰好 n 次
X{n,}? X,至少 n 次
X{n,m}? X,至少 n 次,但是不超过 m 次 Possessive 数量词
X?+ X,一次或一次也没有
X*+ X,零次或多次
X++ X,一次或多次
X{n}+ X,恰好 n 次
X{n,}+ X,至少 n 次
X{n,m}+ X,至少 n 次,但是不超过 m 次 Logical 运算符
XY X 后跟 Y
X|Y X 或 Y
(X) X,作为捕获组 Back 引用
\n 任何匹配的 nth 捕获组 引用
\ Nothing,但是引用以下字符
\Q Nothing,但是引用所有字符,直到 \E
\E Nothing,但是结束从 \Q 开始的引用 特殊构造(非捕获)
(?:X) X,作为非捕获组
(?idmsux-idmsux) Nothing,但是将匹配标志i d m s u x on - off
(?idmsux-idmsux:X) X,作为带有给定标志 i d m s u x on - off
的非捕获组 (?=X) X,通过零宽度的正 lookahead
(?!X) X,通过零宽度的负 lookahead
(?<=X) X,通过零宽度的正 lookbehind
(?<!X) X,通过零宽度的负 lookbehind
(?>X) X,作为独立的非捕获组
想要了解更多可以使劲的戳我
三.字符串类中设计正则表达式的常用方法
1>.matches(String regex)方法
作用:告知此字符串是否匹配给定的正则表达式。
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/
EMAIL:y1053419035@qq.com
*/ package cn.org.yinzhengjie.Demo; public class RegexDemo { public static void main(String[] args) {
String QQ = "1053419035";
String phone = "13021055038";
System.out.println(checkQQ(QQ));
System.out.println(checkTellphone(phone)); } //定义检测QQ的方法。
public static boolean checkQQ(String QQ) {
String pattern = "[1-9][\\d]{4,9}";
boolean res = QQ.matches(pattern);
return res;
} //
public static boolean checkTellphone(String phone) {
String pattern = "1[34857][\\d]{9}";
boolean res = phone.matches(pattern);
return res;
}
} /*
以上代码执行结果如下:
true
true
*/
matches案例展示(匹配QQ号和手机号)
2>.split(String regex)方法
作用:根据给定正则表达式的匹配拆分此字符串。
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/
EMAIL:y1053419035@qq.com
*/ package cn.org.yinzhengjie.Demo; public class RegexDemo { public static void main(String[] args) {
String src = "2018-04-17";
String pattern = "-";
System.out.println(getSplit(src,pattern)); } public static StringBuffer getSplit(String src,String pattern) {
String[] arr = src.split(pattern);
StringBuffer buffer = new StringBuffer();
buffer.append("[");
for (int i = 0; i < arr.length; i++) {
if(i==arr.length-1) {
buffer.append(arr[i]+"]");
}else {
buffer.append(arr[i]+",");
}
}
return buffer;
}
} /*
以上代码执行结果如下:
[2018,04,17]
*/
split案例展示(按指定的字符串切割)
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/
EMAIL:y1053419035@qq.com
*/ package cn.org.yinzhengjie.Demo; public class RegexDemo { public static void main(String[] args) {
String src = "10 20 30 40 50 60 70";
String pattern = " +"; //匹配多个空格。
System.out.println(getSplit(src,pattern)); } public static StringBuffer getSplit(String src,String pattern) {
String[] arr = src.split(pattern);
StringBuffer buffer = new StringBuffer();
buffer.append("[");
for (int i = 0; i < arr.length; i++) {
if(i==arr.length-1) {
buffer.append(arr[i]+"]");
}else {
buffer.append(arr[i]+",");
}
}
return buffer;
}
} /*
以上代码执行结果如下:
[10,20,30,40,50,60,70]
*/
split案例展示(按空格字符串切割)
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/
EMAIL:y1053419035@qq.com
*/ package cn.org.yinzhengjie.Demo; public class RegexDemo { public static void main(String[] args) {
String ipconfig = "192.168.0.254";
String pattern = "\\."; //我们需要对"."进行转义。
System.out.println(getSplit(ipconfig,pattern)); } public static StringBuffer getSplit(String src,String pattern) {
String[] arr = src.split(pattern);
StringBuffer buffer = new StringBuffer();
buffer.append("[");
for (int i = 0; i < arr.length; i++) {
if(i==arr.length-1) {
buffer.append(arr[i]+"]");
}else {
buffer.append(arr[i]+",");
}
}
return buffer;
}
} /*
以上代码执行结果如下:
[10,20,30,40,50,60,70]
*/
split案例展示(切割IP地址)
3>.replaceAll(String regex,String replacenent)方法
作用:使用给定的replacement替换此字符串所有匹配给定的正则表达式的子字符串。
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/
EMAIL:y1053419035@qq.com
*/ package cn.org.yinzhengjie.Demo; public class RegexDemo { public static void main(String[] args) {
String src = "2018yinzhengjie@0417";
System.out.println("切割之前:>>>"+src);
String re = "$";
re = java.util.regex.Matcher.quoteReplacement(re); //一个是JDK提供的方法,对特殊字符进行处理.
src = src.replaceAll("[\\d]+", re);
System.out.println("切割之后:>>>"+src);
}
} /*
以上代码执行结果如下:
切割之前:>>>2018yinzhengjie@0417
切割之后:>>>$yinzhengjie@$
*/
replaceAll案例展示
4>.匹配正确的数字
匹配规则:
1>.匹配正整数:"\\d+";
2>.匹配正小数:"\\d+\\.\\d+" ;
3>.匹配负整数:"-\\d+";
4>.匹配负小数:"-\\d+.\\d+"
5>.匹配保留两位小数的整数:"\\d+\\.\\d{2}"
6>.匹配保留1-3位小数的整数:“\\d+\\.\\d{1,3}”
四.小试牛刀
1>.邮箱地址匹配
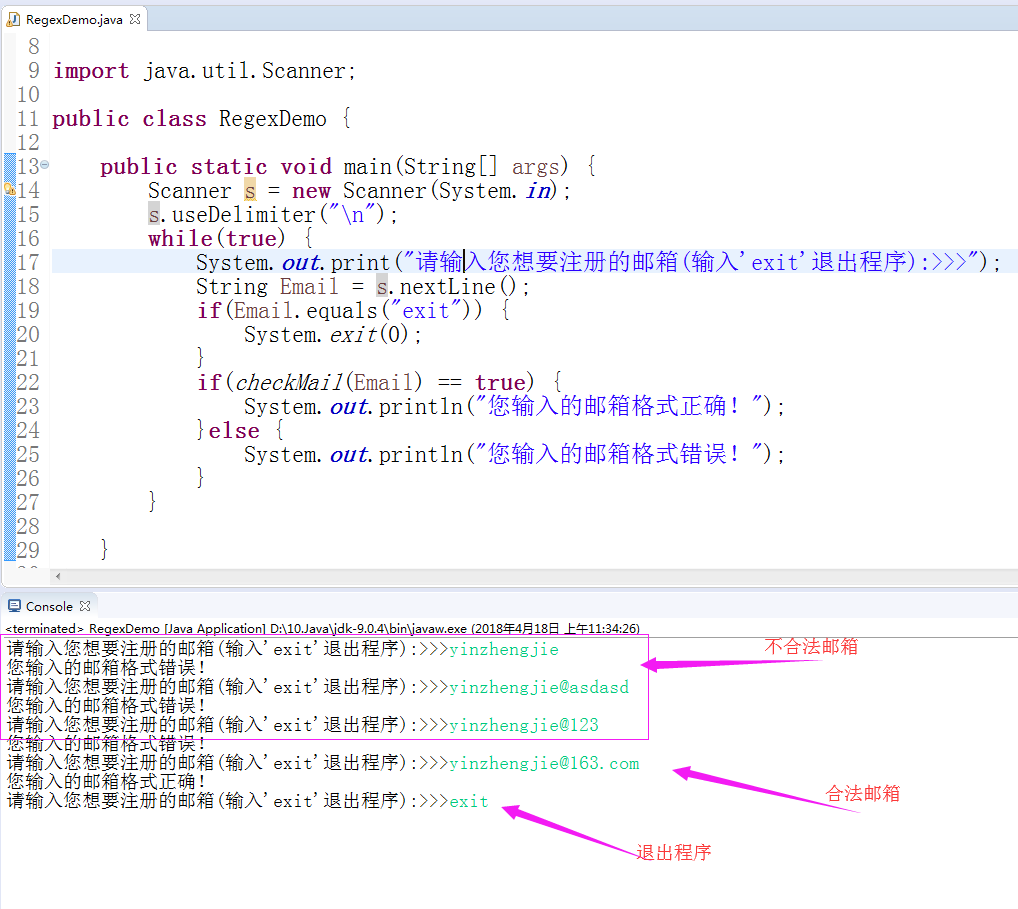
下面的一个案例是对用户输入的邮箱进行合法性判断,当然实际生产环境中比这个要复杂的多,我们这里只是判断用户输入的邮箱地址是否合法。
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/
EMAIL:y1053419035@qq.com
*/ package cn.org.yinzhengjie.Demo; import java.util.Scanner; public class RegexDemo { public static void main(String[] args) {
Scanner s = new Scanner(System.in);
s.useDelimiter("\n");
while(true) {
System.out.print("请输入您想要注册的邮箱(输入'exit'退出程序):>>>");
String Email = s.nextLine();
if(Email.equals("exit")) {
System.exit(0);
}
if(checkMail(Email) == true) {
System.out.println("您输入的邮箱格式正确!");
}else {
System.out.println("您输入的邮箱格式错误!");
}
} } //定义邮箱的匹配规则
public static boolean checkMail(String Email) {
String pattern = "[a-zA-Z0-9_]+@[0-9a-z]+(\\.[a-z]+)+";
boolean res = Email.matches(pattern);
return res;
}
}
下图是我测试的结果:
2>.统计单词出现的次数
我们可以手动输入一些字符串,然后让程序自动统计出来单词出现的次数,实现代码如下:
/*
@author :yinzhengjie
Blog:http://www.cnblogs.com/yinzhengjie/tag/Java%E5%9F%BA%E7%A1%80/
EMAIL:y1053419035@qq.com
*/ package cn.org.yinzhengjie.demo; import java.util.HashMap;
import java.util.Scanner;
import java.util.Set;
import java.util.regex.Matcher;
import java.util.regex.Pattern; public class WordCountDemo { public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.print("input a string:");
String s = sc.nextLine(); HashMap<String, Integer> hm = new HashMap<>(); Pattern p = Pattern.compile("\\b\\w+\\b");
Matcher m = p.matcher(s);
while(m.find()){
String word = m.group();
if(!hm.containsKey(word)){
hm.put(word, 1);
}else{
hm.put(word, hm.get(word) + 1);
}
} Set<String> keys = hm.keySet();
for (String word : keys) {
System.out.println("单词是: " + word +"\t次数是: "+ hm.get(word));
}
}
}
测试结果如下:

Java基础-正则表达式(Regular Expression)语法规则简介的更多相关文章
- 正则表达式(Regular Expression, RegEx)学习入门
1. 概述 正则表达式(Regular Expression, RegEx)是一种匹配模式,描述的是一串文本的特征. 正如自然语言中高大.坚固等词语抽象出来描述事物特征一样,正则表达式就是字符的高度抽 ...
- 正则表达式-Regular expression学习笔记
正则表达式 正则表达式(Regular expression)是一种符号表示法,被用来识别文本模式. 最近在学习正则表达式,今天整理一下其中的一些知识点 grep - 打印匹配行 grep 是个很强大 ...
- Emmet(Zen Coding)语法规则简介
———Emmet(Zen Coding)语法规则简介——— [Zen Coding可谓快速开发HTML和CSS的利器,主要采用仿css类选择器方式编写代码,以下是该利器的基本语法规则和代码示例] 基础 ...
- Java基础-StringBuffer类与StringBuilder类简介
Java基础-StringBuffer类与StringBuilder类简介 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.StringBuffer类 在学习过String类之后 ...
- java 正则表达式 -Regular Expression
正则表达式(Regular Expression),可以说就是一个字符构成的串,它定义了一个用来搜索匹配字符串的模式.正则表达式定义了字符串的模式,可以用来搜索.编辑或处理文本,不仅限于某一种语言(P ...
- Java基础——正则表达式
一.什么是正则表达式 正则表达式,又称规则表达式.(英语:Regular Expression,在代码中常简写为regex.regexp或RE),计算机科学的一个概念.正则表通常被用来检索.替换那些符 ...
- Python正则表达式Regular Expression基本用法
资料来源:http://blog.csdn.net/whycadi/article/details/2011046 直接从网上资料转载过来,作为自己的参考.这个写的很清楚.先拿来看看. 1.正则表 ...
- C#中【正则表达式regular expression】相关的知识
Regex System.Text.RegularExpressions.Regex regex应该是regular expression的缩写 https://msdn.microsoft ...
- Python -- 正则表达式 regular expression
正则表达式(regular expression) 根据其英文翻译,re模块 作用:用来匹配字符串. 在Python中,正则表达式是特殊的字符序列,检查一个字符串是否与某种模式匹配. 设计思想:用一 ...
随机推荐
- Runtime 类的使用
package com.System.Runtime; import java.io.IOException; /* RunTime 该类类主要代表了应用程序运行的环境. getRuntime() 返 ...
- C#简单窗体应用程序(三)
使用C#创建窗体应用程序的基本步骤: (1)创建项目: (2)用户界面设计: (3)属性设置: (4)编写程序代码: (5)保存.调试.运行: 例题:设计歌曲列表界面,效果如下: 第一步:创建项目: ...
- Windows服务器安全配置指南
1).系统安全基本设置 2).关闭不需要的服务 Computer Browser:维护网络计算机更新,禁用 Distributed File System: 局域网管理共享文件,不需要禁用 Distr ...
- Sprint2-2.0
1.开始一个新的冲刺: 起止:2016.6.1~2016.6.14 按照以下过程进行 ProductBacklog:继续向下细化 Sprint 计划会议:确定此次冲刺要完成的目标 Sprint Bac ...
- override toString() function for TreeNode to output OJ's Binary Tree Serialization
class TreeNode { int val; TreeNode left; TreeNode right; TreeNode(int x) { val = x; } @Override publ ...
- delphi ERP框架
之前做c/s架构,接了有家装饰的一个ERP项目,做了一个ERP框架,现在转后端开发了,这些东西还是蛮怀念的,就开源出来吧,有需要的同学可以参考. https://github.com/qianlnk/ ...
- UESTC 1832
今天比赛的时候做的一个题目.感觉这个题目不错. 题目描述: Description In a laboratory, an assistant, Nathan Wada, is measuring w ...
- BZOJ3142 HNOI2013数列(组合数学)
考虑差分序列.每个差分序列的贡献是n-差分序列的和,即枚举首项.将式子拆开即可得到n*mk-1-Σi*cnt(i),cnt(i)为i在所有差分序列中的出现次数之和.显然每一个数出现次数是相同的,所以c ...
- web接口测试中需要测试的几个点
本文导读: web接口测试用例要包括欲测试的功能.应输入的数据和预期的输出结果,只有在数据能正确流入.流出模块的前提下,其他测试才有意义.下面介绍在web测试接口时一些需要注意的点 1.接口返回 数据 ...
- Linux系统中/opt 和 /usr目录
重点:usr是Unix Software Resource的缩写,即“UNIX操作系统软件资源”所放置的目录. 下面是个人找到的适合类似我这种从Windows转向Linux小白的文章. Ref:htt ...