R语言学习笔记—K近邻算法
K近邻算法(KNN)是指一个样本如果在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。即每个样本都可以用它最接近的k个邻居来代表。KNN算法适合分类,也适合回归。KNN算法广泛应用在推荐系统、语义搜索、异常检测。
KNN算法分类原理图:
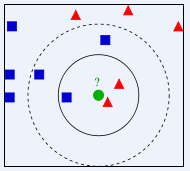
图中绿色的圆点是归属在红色三角还是蓝色方块一类?如果K=5(离绿色圆点最近的5个邻居,虚线圈内),则有3个蓝色方块是绿色圆点的“最近邻居”,比例为3/5,因此绿色圆点应当划归到蓝色方块一类;如果K=3(离绿色圆点最近的3个邻居,实线圈内),则有两个红色三角是绿色圆点的“最近邻居”,比例为2/3,那么绿色圆点应当划归到红色三角一类。
由上看出,该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
KNN算法实现步骤:
1. 数据预处理
2. 构建训练集与测试集数据
3. 设定参数,如K值(K一般选取样本数据量的平方根即可,3~10)
4. 维护一个大小为K的的按距离(欧氏距离)由大到小的优先级队列,用于存储最近邻训练元组。随机从训练元组中选取K个元组作为初始的最近邻元组,分别计算测试元组到这K个元组的距离将训练元组标号和距离存入优先级队列
5. 遍历训练元组集,计算当前训练元组与测试元组的距离L,将所得距离L与优先级队列中的最大距离Lmax
6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列
7. 遍历完毕,计算优先级队列中K个元组的多数类,并将其作为测试元组的类别
8. 测试元组集测试完毕后计算误差率,继续设定不同的K值重新进行训练,最后取误差率最小的K值。
R语言实现过程:
R语言中进行K近邻算法分析的函数包有class包中的knn函数、caret包中的train函数和kknn包中的kknn函数
knn(train, test, cl, k = 1, l = 0, prob = FALSE, use.all = TRUE)
参数含义:
train:含有训练集的矩阵或数据框
test:含有测试集的矩阵或数据框
cl:对训练集进行分类的因子变量
k:邻居个数
l:有限决策的最小投票数
prob:是否计算预测组别的概率
use.all:控制节点的处理办法,即如果有多个第K近的点与待判样本点的距离相等,默认情况下将这些点都作为判别样本点;当该参数设置为FALSE时,则随机选择一个点作为第K近的判别点。
(样本数据说明:文中样本数据描述一女士根据约会对象每年获得飞行里程数;玩视频游戏所消耗的时间百分比;每周消费的冰淇淋公升数,将自己约会对象划分为三种喜好类型)
代码:
#导入分析数据
mydata <- read.table("C:/Users/Cindy/Desktop/婚恋/datingTestSet.txt")
str(mydata)
colnames(mydata) <- c('飞行里程','视频游戏时间占比','食用冰淇淋数','喜好分类')
head(mydata)
#数据预处理,归一化
norfun <- function(x){
z <- (x-min(x))/(max(x)-min(x))
return(z)
}
data <- as.data.frame(apply(mydata[,1:3],2,norfun))
data$喜好分类<-mydata[,4]
#建立测试集与训练集样本
library(caret)
set.seed(123)
ind <- createDataPartition(y=data$喜好分类,times = 1,p=0.5,list = F)
testdata <- data[-ind,]
traindata <- data[ind,]
#KNN算法
library(class)
kresult <- knn(train = traindata[,1:3],test=testdata[,1:3],cl=traindata$喜好分类,k=3)
#生成实际与预判交叉表和预判准确率
table(testdata$喜好分类,kresult)
sum(diag(table(testdata$喜好分类,kresult)))/sum(table(testdata$喜好分类,kresult))
运行结果:

根据结果可知该分类的正确率为95%。
KNN算法优缺点:
优点:
1.易于理解和实现
2. 适合对稀有事件进行分类
3.特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好
缺点:
计算量较大,需要计算新的数据点与样本集中每个数据的“距离”,以判断是否是前K个邻居)
改进:
分类效率上,删除对分类结果影响较小的属性;分类效果上,采用加权K近邻算法,根据距离的远近赋予样本点不同的权重值,kknn包中的kknn函数即采用加权KNN算法。
2018-04-30 22:31:25
R语言学习笔记—K近邻算法的更多相关文章
- 学习笔记——k近邻法
对新的输入实例,在训练数据集中找到与该实例最邻近的\(k\)个实例,这\(k\)个实例的多数属于某个类,就把该输入实例分给这个类. \(k\) 近邻法(\(k\)-nearest neighbor, ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- R语言学习笔记之: 论如何正确把EXCEL文件喂给R处理
博客总目录:http://www.cnblogs.com/weibaar/p/4507801.html ---- 前言: 应用背景兼吐槽 继续延续之前每个月至少一次更新博客,归纳总结学习心得好习惯. ...
- R语言学习笔记(二)
今天主要学习了两个统计学的基本概念:峰度和偏度,并且用R语言来描述. > vars<-c("mpg","hp","wt") &g ...
- R语言学习笔记:小试R环境
买了三本R语言的书,同时使用来学习R语言,粗略翻下来感觉第一本最好: <R语言编程艺术>The Art of R Programming <R语言初学者使用>A Beginne ...
- R语言学习笔记︱Echarts与R的可视化包——地区地图
笔者寄语:感谢CDA DSC训练营周末上完课,常老师.曾柯老师加了小课,讲了echart与R结合的函数包recharts的一些基本用法.通过对比谢益辉老师GitHub的说明文档,曾柯老师极大地简化了一 ...
- R语言学习笔记:基础知识
1.数据分析金字塔 2.[文件]-[改变工作目录] 3.[程序包]-[设定CRAN镜像] [程序包]-[安装程序包] 4.向量 c() 例:x=c(2,5,8,3,5,9) 例:x=c(1:100) ...
- R语言学习笔记—决策树分类
一.简介 决策树分类算法(decision tree)通过树状结构对具有某特征属性的样本进行分类.其典型算法包括ID3算法.C4.5算法.C5.0算法.CART算法等.每一个决策树包括根节点(root ...
- R语言学习笔记—朴素贝叶斯分类
朴素贝叶斯分类(naive bayesian,nb)源于贝叶斯理论,其基本思想:假设样本属性之间相互独立,对于给定的待分类项,求解在此项出现的情况下其他各个类别出现的概率,哪个最大,就认为待分类项属于 ...
随机推荐
- 切片和append操作
本文转自:http://meia.fun/article/1541470004286 学习切片时,被append这个方法困扰了半天:在main方法中把一个切片作为实参传递给另一个函数,并在这个函数内调 ...
- 打开struts-config.xml 报错 解决方法Could not open the editor
打开struts-config.xml 报错 解决办法Could not open the editor 错误信息:Could not open the editor: Project XXX is ...
- MYSQL 的rownum
mysql> SELECT @rownum:=@rownum+1 AS rownum, FLIGHTS.FLTID FROM (SELECT @rownum:=0) r, FLIGHTS lim ...
- mongodb存储引擎
存储引擎(Storage Engine)是MongoDB的核心组件,负责管理数据如何存储在硬盘(Disk)和内存(Memory)上.从MongoDB 3.2 版本开始,MongoDB 支持多数据存储引 ...
- 配置consul为windows服务
安装consul并配置为系统服务下载地址https://www.consul.io/downloads.html 配置系统服务1.拷贝consul.exe的目录 如:E:\Consul\consule ...
- [翻译] GCDiscreetNotificationView
GCDiscreetNotificationView GCDiscreetNotificationView is a discreet, non-modal, notification view fo ...
- 铁乐学Python_day12_装饰器
[函数的有用信息] 例: def login(user, pwd): ''' 功能:登录调用 参数:分别有user和pwd,作用分别是用户和密码: return: 返回值是登录成功与否(True,Fa ...
- EF CodeFirst下的自动迁移
当我们修改数据模型,添加一个如下字段 再次运行程序,会因为数据库结构与模型不一致而报错 为解决以上错误可以采取以下三种方式 1. 删除数据库,重新运行站点,会重新生成数据库,这样就会丢失数据 2. ...
- November 17th 2016 Week 47th Thursday
Don't cry because it is over. Smile because it happened. 不要因为结束而哭泣:微笑吧,因为我们曾经拥有. My ex-girlfriend ha ...
- Python中网络编程对socket accept函数的理解
在服务器端,socket()返回的套接字用于监听(listen)和接受(accept),这个套接字不能用于与客户端之间发送和接收数据. accept()接受一个客户端的连接请求,并返回一个新的套接字, ...