5.flume实战(二)
需求:监控一个文件实时采集新增的数据并输出到控制台
简单理解就是:监控一个文件,只要这个文件有新的内容追加,就将它输出到控制台。
agent技术选型:exec source + memory channel + logger sink
下面写配置文件:
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /usr/local/satori.txt
a1.sources.r1.shell = /bin/sh -c
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
指定type为exec,然后添加一个command,我们输入tail -F file_path,表示跟踪文件,指定一个shell,可以看到配置文件改的不是很多,至于这里的参数exec,可以去flume官网上查看
新建一个配置文件,就叫exec-memory-logger.conf
输入:flume-ng agent --name a1 --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/conf/exec-memory-logger.conf -Dflume.root.logger=INFO,console
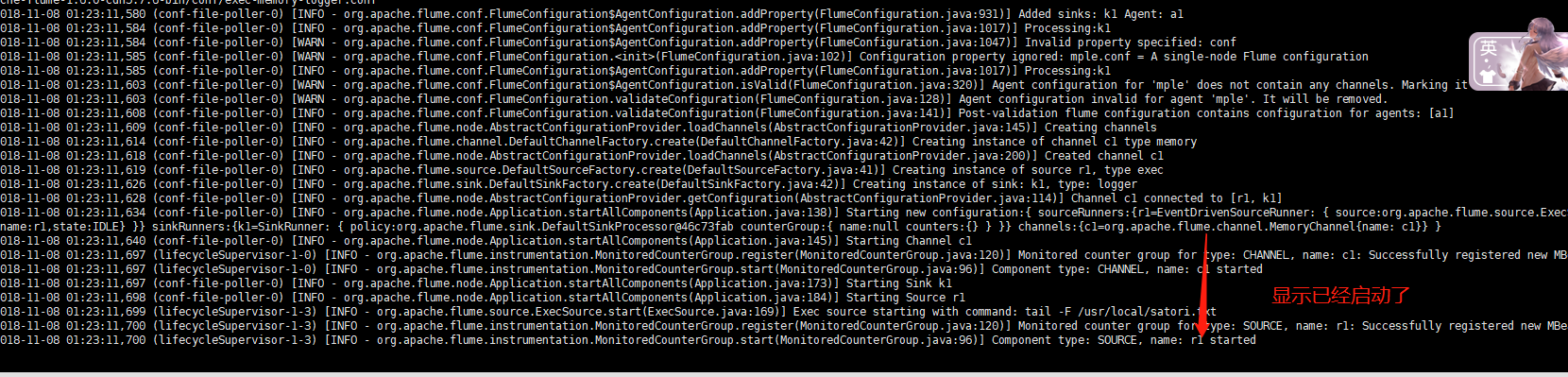
我们重定向一些内容到satori.conf里面去


可以看到,已经实施监控了
但我们目前都是输出到控制台上面,意义不大,我们也可以写到hdfs里面。
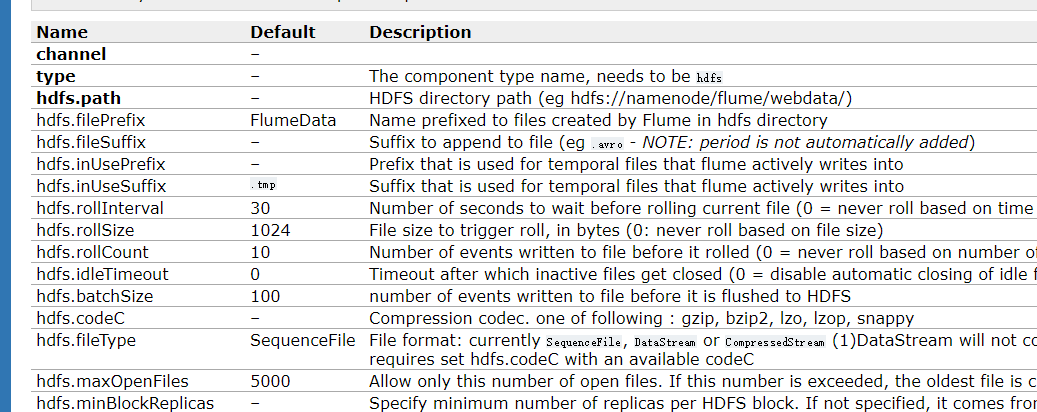
此时需要指定,type为hdfs,同时指定hdfs的路径,这个是离线处理的。
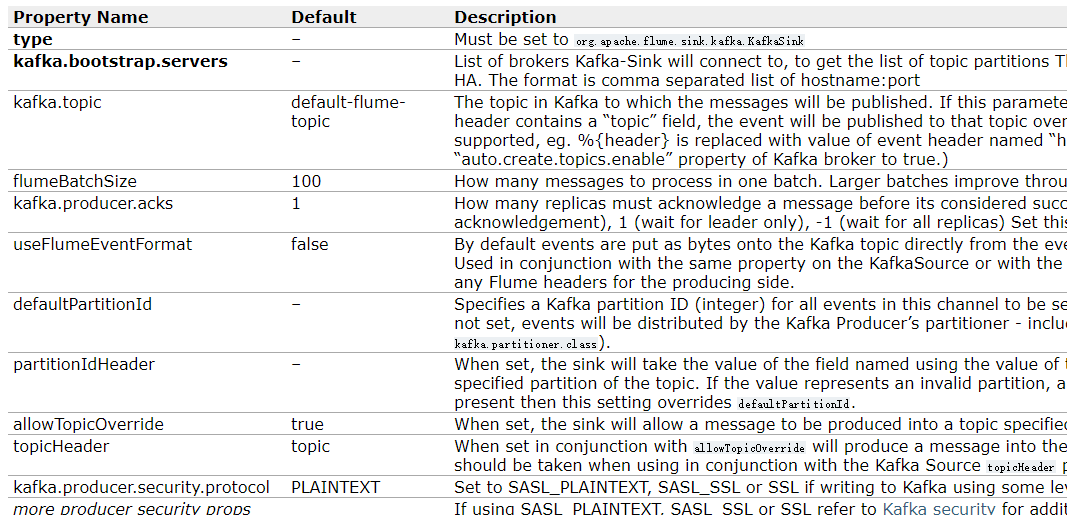
实时处理的话,需要到kafka
5.flume实战(二)的更多相关文章
- Flume系列二之案例实战
Flume案例实战 写在前面 通过前面一篇文章http://blog.csdn.net/liuge36/article/details/78589505的介绍我们已经知道flume到底是什么?flum ...
- Flume实战案例运维篇
Flume实战案例运维篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Flume概述 1>.什么是Flume Flume是一个分布式.可靠.高可用的海量日志聚合系统,支 ...
- Flume 实战练习
前期准备 了解Flume 架构及核心组件 Flume 架构及核心组件 Source : 收集(指定数据源从哪里获取) Channel : 聚集 Sink : 输出(把数据写到哪里去) 学习使用 Flu ...
- coreseek实战(二):windows下mysql数据源部分配置说明
coreseek实战(二):windows下mysql数据源部分配置说明 关于coreseek在windows使用mysql数据源的配置,以及中文分词的详细说明,请参考官方文档: mysql数据源配置 ...
- 【NFS项目实战二】NFS共享数据的时时同步推送备份
[NFS项目实战二]NFS共享数据的时时同步推送备份 标签(空格分隔): Linux服务搭建-陈思齐 ---本教学笔记是本人学习和工作生涯中的摘记整理而成,此为初稿(尚有诸多不完善之处),为原创作品, ...
- chrome调试工具高级不完整使用指南(实战二)
3.3 给页面添加测试脚本 在现实的工作中,我们往往会遇到一些问题在线上就会触发然后本地就触发不了的问题.或者是,要给某个元素写一个测试脚本.这个时候如果是浏览器有提供一个添加脚本的功能的话,那么我们 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- Netty 仿QQ聊天室 (实战二)
Netty 聊天器(百万级流量实战二):仿QQ客户端 疯狂创客圈 Java 分布式聊天室[ 亿级流量]实战系列之15 [博客园 总入口 ] 源码IDEA工程获取链接:Java 聊天室 实战 源码 写在 ...
- 第1节 flume:15、flume案例二,通过自定义拦截器实现数据的脱敏
1.7.flume案例二 案例需求: 在数据采集之后,通过flume的拦截器,实现不需要的数据过滤掉,并将指定的第一个字段进行加密,加密之后再往hdfs上面保存 原始数据与处理之后的数据对比 图一 ...
随机推荐
- 第一个Spring小程序实战
ps:本文偏向原理和操作性,原理适合于任何编译器. 支持Spring入门,目的是在xml文件里面装配相关bean(java对象),并实现获取.(IOC) 一.先建立一个Spring新项目,添加mave ...
- B - 整数区间
B - 整数区间 Time Limit: 1000/1000MS (C++/Others) Memory Limit: 65536/65536KB (C++/Others) Problem Descr ...
- web相关基础知识1
2017-12-13 09:47:11 关于HTML 1.绝对路径和相对路径 相对路径:相对于文件自身为参考. (工作中一般是使用相对路径) 这里我们用html文件为参考.如果说html和图片平级,那 ...
- 微信小程序小程序使用scroll-view不能使用下拉刷新的解决办法
<scroll-view class="movie-grid-container" scroll-y="true" scroll-x="fals ...
- Flink源码解读之状态管理
一.从何说起 State要能发挥作用,就需要持久化到可靠存储中,flink中持久化的动作就是checkpointing,那么从TM中执行的Task的基类StreamTask的checkpoint逻辑说 ...
- ElasticSearch1.7.1拼音插件elasticsearch-analysis-pinyin-1.3.3使用介绍
ElasticSearch拼音插件elasticsearch-analysis-pinyin使用介绍 https://my.oschina.net/xiaohui249/blog/214505 摘要: ...
- 【bzoj3626】[LNOI2014]LCA 树链剖分+线段树
题目描述 给出一个n个节点的有根树(编号为0到n-1,根节点为0).一个点的深度定义为这个节点到根的距离+1.设dep[i]表示点i的深度,LCA(i,j)表示i与j的最近公共祖先.有q次询问,每次询 ...
- hdu 1787 GCD Again (欧拉函数)
GCD Again Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- P2124 奶牛美容
题目描述 输入输出格式 输入格式: 输出格式: 输入输出样例 输入样例#1: 6 16 ................ ..XXXX....XXX... ...XXXX....XX... .XXXX ...
- 【C++ 拾遗】Function-like Macros
Macro expansion is done by the C preprocessor at the beginning of compilation. The C preprocessor is ...