MapReduce(1): Prepare input for Mappers
According to Wikipedia MapReduce, there are two ways to illustrate MapReduce. One contains three steps: Map, Shuffle and Reduce; Another one with 5 steps is my preference:
a. Prepare the Map() input,
b. Run the user-provided Map() code
c. "Shuffle" the Map output to the Reduce processors,
d. Run the user-provided Reduce() code,
e. Produce the final output
This blog focuses on how to prepare the Map() input:
1. Block and InputSplit:
As shown in the HDFS blogs, super huge dataset is physically stored in HDFS. But Mappers do not directly process physical blocks, instead InputSplits converts the physical representation of the block into logical for the Hadoop Mappers.
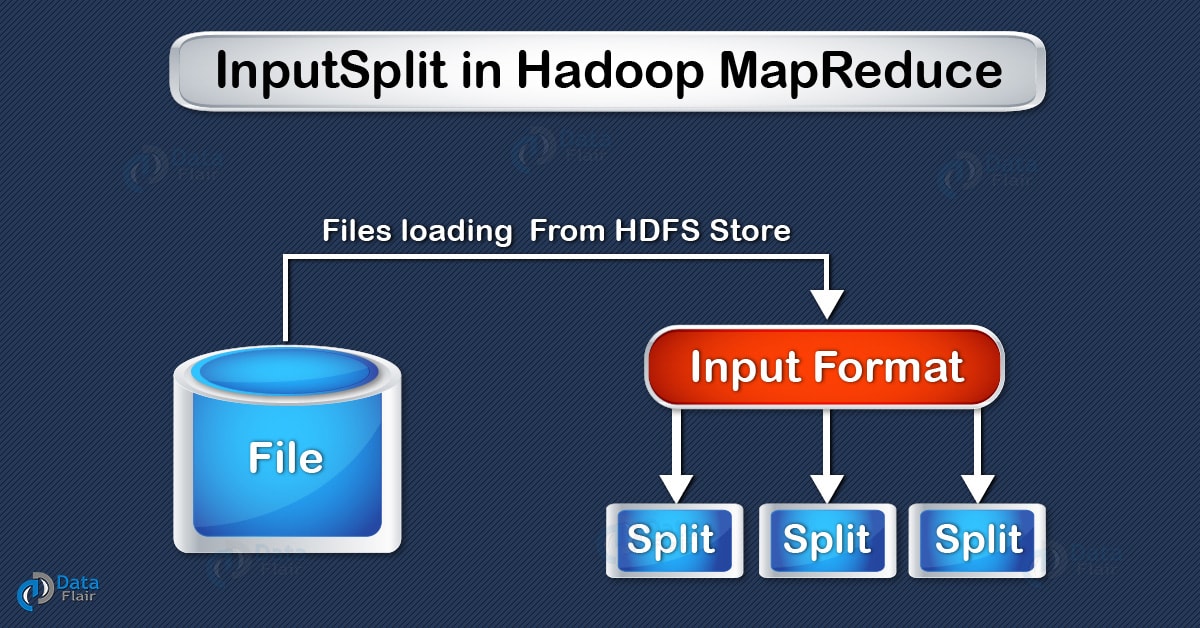
InputSplit is the logical representation of data. It describes a unit of work that contains a single map task in a MapReduce program. It is created by InputFormat. FileInputFormat, by default, breaks a file into 128MB chunks (same as blocks in HDFS),framework assigns one split to each Map function. Inputsplit does not contain the input data; it is just a reference to the data.

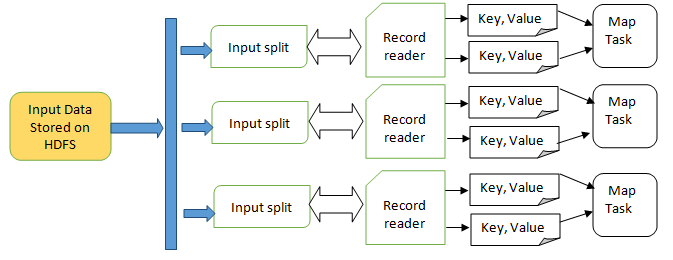
2. RecordReader:
It determines how an InputSplit is passed into a Map function. The RecordReader instance is defined by the InputFormat. By default, it uses TextInputFormat for converting data into a key-value pair. TextInputFormat provides 2 types of RecordReaders: LineRecordReader, SequenceFileRecordReader
References:
https://hadoopabcd.wordpress.com/2015/03/10/hdfs-file-block-and-input-split/
https://en.wikipedia.org/wiki/MapReduce
https://data-flair.training/blogs/shuffling-and-sorting-in-hadoop/
https://zhuanlan.zhihu.com/p/34849261
https://www.edureka.co/blog/mapreduce-tutorial/
MapReduce(1): Prepare input for Mappers的更多相关文章
- wordcount报错:org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist:
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: In ...
- Hadoop官方文档翻译——MapReduce Tutorial
MapReduce Tutorial(个人指导) Purpose(目的) Prerequisites(必备条件) Overview(综述) Inputs and Outputs(输入输出) MapRe ...
- Hadoop 2.6 MapReduce运行原理详解
市面上的hadoop权威指南一类的都是老版本的书籍了,索性学习并翻译了下最新版的Hadoop:The Definitive Guide, 4th Edition与大家共同学习. 我们通过提交jar包, ...
- MapReduce: 一个巨大的倒退
前言 databasecolumn 的数据库大牛们(其中包括PostgreSQL的最初伯克利领导:Michael Stonebraker)最近写了一篇评论当前如日中天的MapReduce 技术的文章, ...
- 基于文件系统(及MySQL)使用Java实现MapReduce
实现这个代码的原因是: 我会MapReduce,但是之前都是在AWS EMR上,自己搭过伪分布式的,但是感觉运维起来比较困难: 我就MySQL会一点(本来想用mongoDB的但是不太会啊) 数据量不是 ...
- MapReduce(2): How does Mapper work
In the previous post, we've illustrated how Hadoop MapReduce prepares input for Mappers. Long story ...
- Linux上搭建Hadoop2.6.3集群以及WIN7通过Eclipse开发MapReduce的demo
近期为了分析国内航空旅游业常见安全漏洞,想到了用大数据来分析,其实数据也不大,只是生产项目没有使用Hadoop,因此这里实际使用一次. 先看一下通过hadoop分析后的结果吧,最终通过hadoop分析 ...
- MapReduce 单词统计案例编程
MapReduce 单词统计案例编程 一.在Linux环境安装Eclipse软件 1. 解压tar包 下载安装包eclipse-jee-kepler-SR1-linux-gtk-x86_64.ta ...
- MapReduce实现二度好友关系
一.问题定义 我在网上找了些,关于二度人脉算法的实现,大部分无非是通过广度搜索算法来查找,犹豫深度已经明确了2以内:这个算法其实很简单,第一步找到你关注的人:第二步找到这些人关注的人,最后找出第二步结 ...
随机推荐
- STM32启动地址设置及从非0x800000 开始调试程序
首先设置程序的启动地址,STM32默认的启动地址是从0x8000000开始的,现在我要设置程序向后偏移10K地址,也就是从0x8002800启动. 需要分两步完成上面操作: 一.Keil MDK设置: ...
- luogu_P1177 【模板】快速排序 (快排和找第k大的数)
[算法] 选取pivot,然后每趟快排用双指针扫描(l,r)区间,交换左指针大于pivot的元素和右指针小于pivot的元素,将区间分成大于pivot和小于pivot的 [注意] 时间复杂度取决于pi ...
- 《A chorus section detection method for musical audio signals and its application to a music listening section》
Abstract: 重复的副歌识别对音乐理解的计算模型(computational model)至关重要,应用层面有:音乐副歌识别预览,音乐检索等. 传统检测的难点:变调,起始点和结束点(both e ...
- wxpython中列表框(ListBox类)、复选列表框(CheckListBox)、下拉选项(Choice)、进度条(Gauge)、滑块(Slider)使用实例源码分享
#coding=utf-8 import wx import time class MyFrame(wx.Frame): def __init__(self): wx.Frame.__init__(s ...
- JavaScript版EAN码校验算法
<script type="text/javascript"> $(document).ready(function () { $("#btnCalc&q ...
- python基础--内置函数map
num_1=[1,2,10,5,3,7] # num_2=[] # for i in num_1: # num_2.append(i**2) # print(num_2) # def map_test ...
- 2017ICPC南宁M The Maximum Unreachable Node Set (偏序集最长反链)
题意:给你一张DAG,让你选取最多的点,使得这些点之间互相不可达. 思路:此问题和最小路径可重复点覆盖等价,先在原图上跑一边传递闭包,然后把每个点拆成两个点i, i + n, 原图中的边(a, b)变 ...
- HTML5 游戏引擎的选择
原生手游市场已是红海,腾讯.网易等寡头独霸天下,H5游戏市场或将成为下一个风口.据笔者所知,很多H5游戏开发团队由于选择引擎不慎导致项目甚至团队夭折.如何选择适合团队和项目的引擎,笔者通过学习和项目实 ...
- Page.after
解释: Page.after可以增加Page级的切面,触发的时机是在所拦截的对应生命周期方法执行之后,也可以拦截所有页面上发生的事件(对于要拦截的事件,在swan文件上必须显示绑定了相应事件). 方法 ...
- Largest Point
Largest Point Time Limit: 1500/1000 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others)Tot ...