Alibaba DataX 源码编译
Alibaba DataX 源码编译
标签(空格分隔): ETL
DataX简介
设计理念
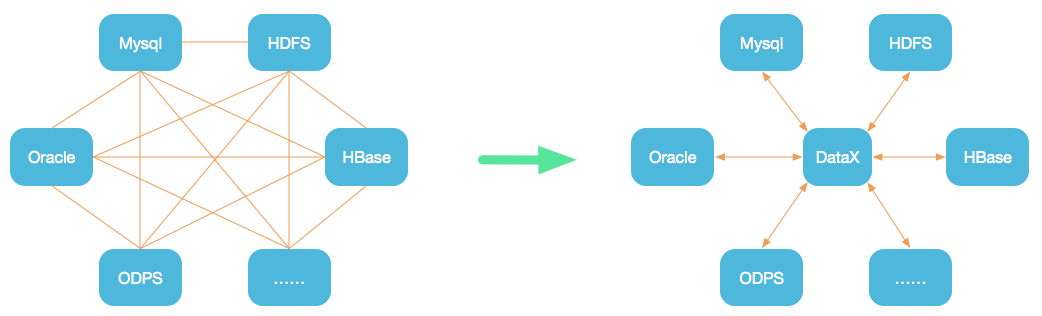
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。此前已经开源DataX1.0版本,此次介绍为阿里巴巴开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。
源码及文档: https://github.com/alibaba/DataX
DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断从Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
DataX3.0核心架构
DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,阿里内部版本应该支持分布式,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
核心模块介绍:
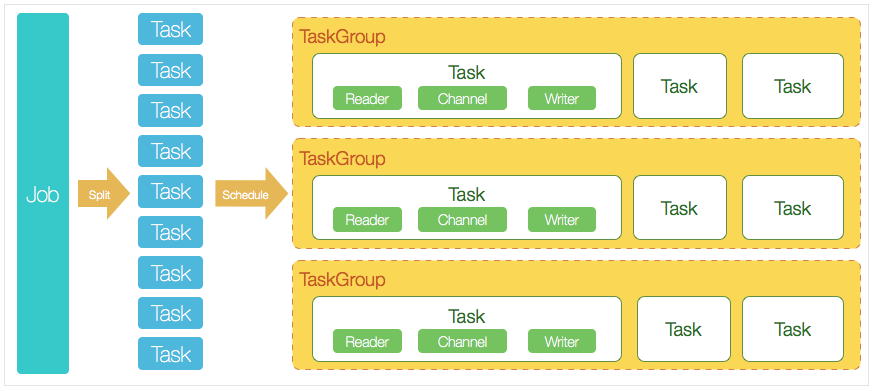
DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务同步工作。
DataX作业运行起来之后, Job监控并等待多个TaskGroup模块任务完成,等待所有TaskGroup任务完成后Job成功退出。否则,异常退出,进程退出值非0
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
DataXJob根据分库分表切分成了100个Task。
根据20个并发,DataX计算共需要分配4个TaskGroup(20/5)。
4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
编译源码
1,下载源码
$ git clone git@github.com:alibaba/DataX.git
2,配置 maven setting.xml
修改为阿里云镜像
<mirrors>
<mirror>
<id>custom-mirror</id>
<mirrorOf>*</mirrorOf>
<!--<url>http://maven.aliyun.com/nexus/content/groups/public/</url>-->
<url>https://maven.aliyun.com/repository/central</url>
</mirror>
</mirrors>
3,编译打包
$ mvn -U clean package assembly:assembly -Dmaven.test.skip=true
注:异常处理
异常一:
[ERROR] Failed to execute goal on project odpsreader: Could not resolve dependencies for project com.alibaba.datax:odpsreader:jar:0.0.1-SNAPSHOT: Could not find artifact com.alibaba.external:bouncycastle.provider:jar:1.38-jdk15 in custom-mirror (https://maven.aliyun.com/repository/central) -> [Help 1]
$ vim odpsreader/pom.xml
com.aliyun.odps
odps-sdk-core
换一下版本 :0.20.7-public
异常二:
[ERROR] Failed to execute goal on project otsstreamreader: Could not resolve dependencies for project com.alibaba.datax:otsstreamreader:jar:0.0.1-SNAPSHOT: Could not find artifact com.aliyun.openservices:tablestore-streamclient:jar:1.0.0-SNAPSHOT -> [Help 1]
$ vim otsstreamreader/pom.xml
把 tablestore-streamclient 的版本 1.0.0-SNAPSHOT 改成 1.0.0
其他异常:
多数是由maven仓库缺少jar包所致,可将maven镜像改为私服重试,私服配置如下:
<mirrors>
<mirror>
<id>custom-mirror</id>
<mirrorOf>*</mirrorOf>
<url>http://xxx.xxx.xxx.xxx:9999/nexus/content/groups/public/</url>
</mirror>
</mirrors>
public availibale repositories:
aliyun:https://maven.aliyun.com/repository/central/
Central:https://repo1.maven.org/maven2/
cloudra:https://repository.cloudera.com/content/repositories/releases
conjars:http://conjars.org/repo/
打包成功,日志显示如下:
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for datax-all 0.0.1-SNAPSHOT:
[INFO]
[INFO] datax-all .......................................... SUCCESS [02:46 min]
[INFO] datax-common ....................................... SUCCESS [ 1.704 s]
[INFO] datax-transformer .................................. SUCCESS [ 1.092 s]
[INFO] datax-core ......................................... SUCCESS [ 2.538 s]
[INFO] plugin-rdbms-util .................................. SUCCESS [ 1.004 s]
[INFO] mysqlreader ........................................ SUCCESS [ 0.817 s]
[INFO] drdsreader ......................................... SUCCESS [ 0.871 s]
[INFO] sqlserverreader .................................... SUCCESS [ 0.759 s]
[INFO] postgresqlreader ................................... SUCCESS [ 0.898 s]
[INFO] oraclereader ....................................... SUCCESS [ 0.730 s]
[INFO] odpsreader ......................................... SUCCESS [ 4.434 s]
[INFO] otsreader .......................................... SUCCESS [ 7.622 s]
[INFO] otsstreamreader .................................... SUCCESS [ 2.919 s]
[INFO] plugin-unstructured-storage-util ................... SUCCESS [ 3.740 s]
[INFO] txtfilereader ...................................... SUCCESS [ 2.490 s]
[INFO] hdfsreader ......................................... SUCCESS [ 10.103 s]
[INFO] streamreader ....................................... SUCCESS [ 0.771 s]
[INFO] ossreader .......................................... SUCCESS [ 3.766 s]
[INFO] ftpreader .......................................... SUCCESS [ 3.546 s]
[INFO] mongodbreader ...................................... SUCCESS [ 3.219 s]
[INFO] rdbmsreader ........................................ SUCCESS [ 0.750 s]
[INFO] hbase11xreader ..................................... SUCCESS [ 8.536 s]
[INFO] hbase094xreader .................................... SUCCESS [ 15.437 s]
[INFO] opentsdbreader ..................................... SUCCESS [ 9.389 s]
[INFO] mysqlwriter ........................................ SUCCESS [ 0.656 s]
[INFO] drdswriter ......................................... SUCCESS [ 0.628 s]
[INFO] odpswriter ......................................... SUCCESS [ 1.318 s]
[INFO] txtfilewriter ...................................... SUCCESS [ 2.235 s]
[INFO] ftpwriter .......................................... SUCCESS [ 2.847 s]
[INFO] hdfswriter ......................................... SUCCESS [ 5.695 s]
[INFO] streamwriter ....................................... SUCCESS [ 0.656 s]
[INFO] otswriter .......................................... SUCCESS [ 1.325 s]
[INFO] oraclewriter ....................................... SUCCESS [ 0.674 s]
[INFO] sqlserverwriter .................................... SUCCESS [ 0.714 s]
[INFO] postgresqlwriter ................................... SUCCESS [ 0.660 s]
[INFO] osswriter .......................................... SUCCESS [ 2.360 s]
[INFO] mongodbwriter ...................................... SUCCESS [ 2.324 s]
[INFO] adswriter .......................................... SUCCESS [ 4.402 s]
[INFO] ocswriter .......................................... SUCCESS [ 6.219 s]
[INFO] rdbmswriter ........................................ SUCCESS [ 0.735 s]
[INFO] hbase11xwriter ..................................... SUCCESS [ 4.088 s]
[INFO] hbase094xwriter .................................... SUCCESS [ 2.189 s]
[INFO] hbase11xsqlwriter .................................. SUCCESS [ 15.235 s]
[INFO] hbase11xsqlreader .................................. SUCCESS [ 14.237 s]
[INFO] elasticsearchwriter ................................ SUCCESS [ 3.212 s]
[INFO] tsdbwriter ......................................... SUCCESS [ 0.897 s]
[INFO] hbase20xsqlreader .................................. SUCCESS [01:47 min]
[INFO] hbase20xsqlwriter .................................. SUCCESS [ 29.320 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 07:44 min
[INFO] Finished at: 2019-05-27T21:55:06+08:00
[INFO] ------------------------------------------------------------------------
打包成功后的DataX包位于 {DataX_source_code_home}/target/datax/datax/ ,结构如下:
$ cd {DataX_source_code_home}
$ ls ./target/datax/datax/
bin conf job lib plugin script tmp
root@VECS02922:/app/compile/DataX/target# du -sh *
4.0K archive-tmp
1.3G datax
1.2G datax.tar.gz
Alibaba DataX 源码编译的更多相关文章
- 《Flink 源码解析》—— 源码编译运行
更新一篇知识星球里面的源码分析文章,去年写的,周末自己录了个视频,大家看下效果好吗?如果好的话,后面补录发在知识星球里面的其他源码解析文章. 前言 之前自己本地 clone 了 Flink 的源码,编 ...
- Flink 源码解析 —— 源码编译运行
更新一篇知识星球里面的源码分析文章,去年写的,周末自己录了个视频,大家看下效果好吗?如果好的话,后面补录发在知识星球里面的其他源码解析文章. 前言 之前自己本地 clone 了 Flink 的源码,编 ...
- Android 5.0源码编译问题
如果是自己通过repo和git直接从google官网上download的源码,请忽略这个问题,但是由于google在国内被限制登录,通过这一种方法不是每个人都能download下来源码,通常的做法就是 ...
- Android stdio Apktool源码编译
Android Apktool源码编译 标签(空格分隔): Android Apktool 源码编译 需求 习惯NetBeans调试smali需要用Apktool反编译apk,需要用-d的参数才能生成 ...
- SSH/SSL 源码编译安装简易操作说明
环境:CentOS 6.7 安全加固需求,由于某盟扫描系统主机有SSL系列漏洞,客户要求必须修复: 解决方案:将SSH/SSL升级到最新版本,删除SSL旧版本(实测不删除旧版本某盟扫描无法通过). 当 ...
- Hadoop源码编译过程
一. 为什么要编译Hadoop源码 Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用java,所以就引入了本地库(Native Libraries)的概念,通 ...
- World Wind .NET源码编译问题处理
World Wind .NET源码编译问题处理 下载了World_Wind_1.4.0_Source源码(http://worldwindcentral.com/wiki/NASA_World_W ...
- 源码编译安装 MySQL 5.5.x 实践
1.安装cmakeMySQL从5.5版本开始,通过./configure进行编译配置方式已经被取消,取而代之的是cmake工具.因此,我们首先要在系统中源码编译安装cmake工具. # wget ht ...
- Linux 安装node.js ---- 源码编译的方式
一 : 普通用户: 安装前准备环境: 1.检查Linux 版本 命令: cat /etc/redhat-release 2.检查 gcc.gcc-c++ 是否安装过 命令: rpm -q gcc rp ...
随机推荐
- Docker:Swarm + Stack 一站式部署容器集群
参考1 参考2 1.注意docker的版本,yum默认安装的版本比较低,可能出现 unsupported Compose file version: 3.7 docker版本升级 2.docker-c ...
- 移动端实1px细线方法
前言 在移动端中,宽度100%,1px的线看起来要比pc端中宽度100%,1px的线粗, 那是因为css中的1px并不等于移动设备(物理像素)的1px.物理像素显示是1个像素代表2个像素,所以出现为2 ...
- 19 Python之面向对象(成员)
1. 成员 在类中你能写的所有内容都是类的成员 2. 变量 1. 实例变量: 由对象去访问的变量. class Person: def __init__(self, name, id, gender, ...
- git 基本命令操作
配置 Git 的相关参数. Git 一共有3个配置文件: 1. 仓库级的配置文件:在仓库的 .git/.gitconfig,该配置文件只对所在的仓库有效.2. 全局配置文件:Mac 系统在 ~/.gi ...
- pip 报错找不到pip问题
具体报错如下 解决办法: wget https://bootstrap.pypa.io/get-pip.py --no-check-certificate 使用当前python3运行
- HQL实现模糊查询
hibernate 实现模糊查询两种传参方式,其实各个方法的实质都是一样的,只不过传递参数的方法稍微有点区别 public List<User> getUsers(String id){ ...
- 测开常见面试题什么是redis
企业中redis是必备的性能优化中间件,也是常见面试题,首先Redis是由意大利人Salvatore Sanfilippo(网名:antirez)开发的一款内存高速缓存数据库.Redis全称为:Rem ...
- 模拟赛小结:The 2019 China Collegiate Programming Contest Harbin Site
比赛链接:传送门 上半场5题,下半场疯狂挂机,然后又是差一题金,万年银首也太难受了. (每次银首都会想起前队友的灵魂拷问:你们队练习的时候进金区的次数多不多啊?) Problem J. Justify ...
- mysql向表中某字段前后追加一段字符串 concat(), trim(), ltrim(), rtrim(), repeat()
1.mysql向表中某字段后面追加一段字符串:update table_name set field=CONCAT(field, '分隔符', str);//'分隔符',可以为空,也可以省略updat ...
- 双向BFS统计
Hdu1195 两个四位密码 问你最少多少步能到达 /*Huyyt*/ #include<bits/stdc++.h> #define mem(a,b) memset(a,b,sizeof ...