利用zookeeper部署kafka集群
1.准备工作:
iptables -F #关闭防火墙
systemctl stop firewalld.service #关闭防火墙
准备三台虚拟机并放入/etc/hosts下

192.168.100.242 testceph
192.168.100.244 redis1
192.168.100.245 redis2
将testceph的/etc/hosts文件拷贝到其他两台虚拟机上
命令:
[root@testceph ~]# for i in 244 245
> do
> scp /etc/hosts 192.168.100.$i:/etc/
> done
root@192.168.100.244's password: 输入密码
hosts 100% 238 231.1KB/s 00:00
root@192.168.100.245's password: 输入密码
hosts 100% 238 418.2KB/s 00:00
2.安装依赖包
[root@testceph ~]yum install -y gcc g++ make gcc-c++ kernel-devel automake autoconf libtool make wget tcl vim unzip git java
3.准备 zookeeper目录 三个节点 192.168.100.242 192.168.100.244 192.168.100.245 (三台都要操作)
命令:mkdir /opt/zookeeper
mkdir /opt/zookeeper/zkdata
mkdir /opt/zookeeper/zkdatalog

zookeeper安装路径:wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
命令:cp /root/zookeeper-3.4.14.tar.gz /opt/
命令:cd /opt
命令:tar -zxvf zookeeper-3.4.14.tar.gz -C /opt/zookeeper
命令:cp /opt/zookeeper/zookeeper-3.4.14/conf/zoo_sample.cfg /opt/zookeeper/zookeeper-3.4.14/conf/zoo.cfg #备份配置文件
4.修改zookeeper配置文件
命令:vim /opt/zookeeper/zookeeper-3.4.14/conf/zoo.cfg # 这样查看的配置 cat /opt/zookeeper/zookeeper-3.4.14/conf/zoo.cfg | egrep -v "^$|^#"
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/zookeeper/zkdata
dataLogDir=/opt/zookeeper/zkdatalog
clientPort=2181
server.1=192.168.100.242:2888:3888
server.2=192.168.100.244:2888:3888
server.3=192.168.100.245:2888:3888
(注意:前面不能有空格)
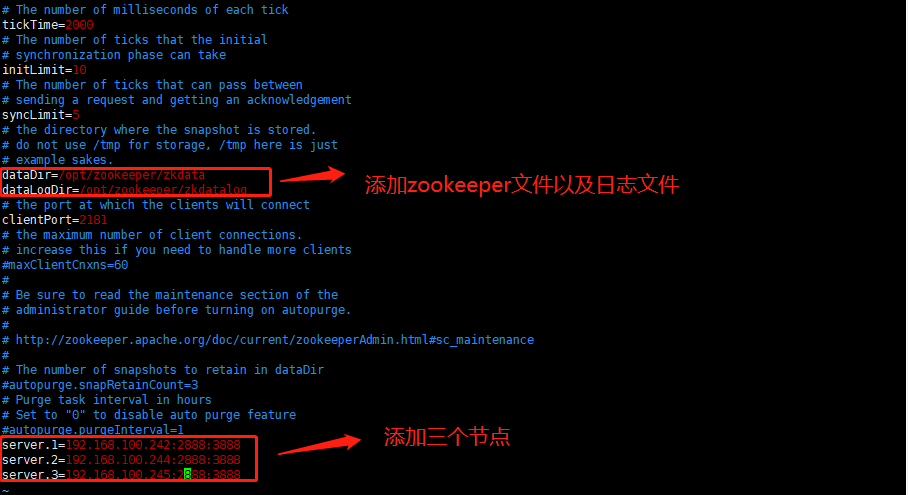
注意:server.1 这个1是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目 录下面myid文件里
192.168.100.245为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的 端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
注意
如果指定了日志位置需要修改下面参数
cp /opt/zookeeper/zookeeper-3.4.14/bin/zkServer.sh /opt/zookeeper/zookeeper-3.4.14/bin/zkServer.sh.bak
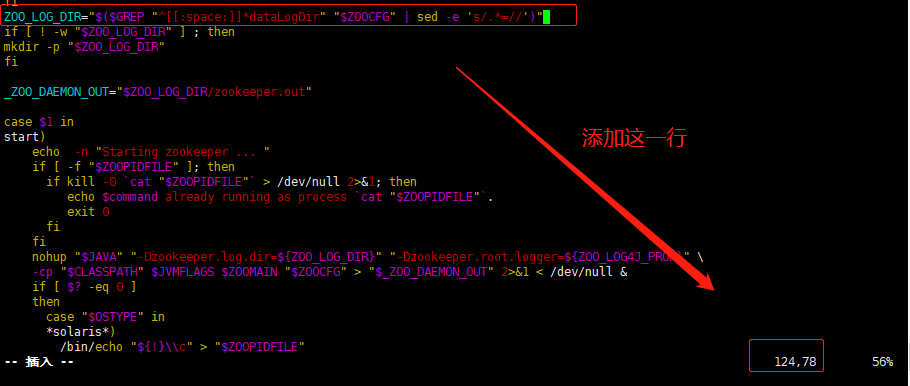
命令:vim /opt/zookeeper/zookeeper-3.4.14/bin/zkServer.sh
ZOO_LOG_DIR="$($GREP "^[[:space:]]*dataLogDir" "$ZOOCFG" | sed -e 's/.*=//')" #124添加这一行
5.拷贝配置好的文件到其他主机
命令:scp -r /opt/zookeeper 192.168.100.244:/opt/
命令:scp -r /opt/zookeeper 192.168.100.245:/opt/
创建快照目录myid文件
#server.1
echo "1" > /opt/zookeeper/zkdata/myid
#server.2
echo "2" > /opt/zookeeper/zkdata/myid
#server.3
echo "3" > /opt/zookeeper/zkdata/myid
6.启动服务
命令:/opt/zookeeper/zookeeper-3.4.14/bin/zkServer.sh start
命令:/opt/zookeeper/zookeeper-3.4.14/bin/zkServer.sh status #查看状态
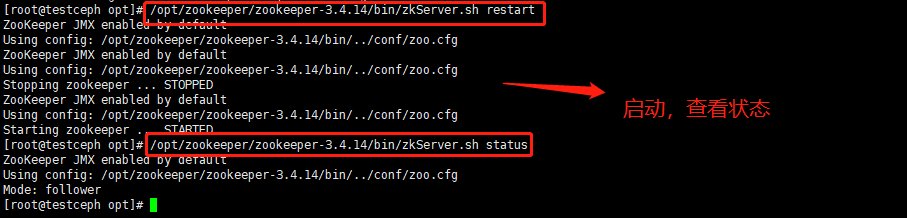
注意:当看见有一台Mode:leader(管理节点) 两台Mode:follower(节点)即为成功
以上就是zookeeper配置完成,接下来配置kafka
1.kafka集群目录准备
命令:mkdir /opt/kafka
命令:mkdir /opt/kafka/kafkalogs
命令:cd /opt/kafka
命令:wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.1/kafka_2.12-2.3.1.tgz #安装包路径
命令:tar -zvxf kafka_2.12-2.3.1.tgz #解包
2.修改配置文件
有三处需要修改



listeners=PLAINTEXT://192.168.100.242:9092 #开启PLAINTEXT认证(用户名和密码认证)确保9092端口能够连接
log.dirs=/opt/kafka/kafkalogs/ #指定kafka日志路径
zookeeper.connect=192.168.100.242:2181,192.168.100.244:2181,192.168.100.245:2181 #指定zookeeper集群路径
[root@testceph kafka]# cat /opt/kafka/kafka_2.12-2.3.1/config/server.properties | egrep -v "^$|^#" #查看所有参数
broker.id=0
listeners=PLAINTEXT://192.168.100.242:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/kafka/kafkalogs/
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.100.242:2181,192.168.100.244:2181,192.168.100.245:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
3.拷贝配置好的文件和程序
命令:scp -r /opt/kafka 192.168.100.244:/opt/
命令:scp -r /opt/kafka 192.168.100.245:/opt/
4.其他节点只需修改两处
broker.id=1 #节点id号不能一样
listeners=PLAINTEXT://192.168.100.244:9092 #认证的IP号和自己的主机IP一致


5.运行kafka服务在三个节点
命令:nohup /opt/kafka/kafka_2.12-2.3.1/bin/kafka-server-start.sh /opt/kafka/kafka_2.12-2.3.1/config/server.properties >/dev/null 2>&1 &
6.随便在其中一台节点主机执行
命令:/opt/kafka/kafka_2.12-2.3.1/bin/kafka-topics.sh --create --zookeeper 192.168.100.242:2181,192.168.100.244:2181,192.168.100.245:2181 --replication-factor 1 --partitions 1 --topic test
#通过zookeeper集群创建topics名字test(消息主题:相当于文件系统目录,用于保存消息内容)

命令:/opt/kafka/kafka_2.12-2.3.1/bin/kafka-topics.sh --list --zookeeper 192.168.100.242:2181,192.168.100.244:2181,192.168.100.245:2181
#通过zookeeper集群来查看topics列表(只有刚才创建的test)

7.查看topic状态
命令:/opt/kafka/kafka_2.12-2.3.1/bin/kafka-topics.sh --describe --zookeeper 192.168.100.242:2181,192.168.100.244:2181,192.168.100.245:2181 --topic test
#通过zookeeper集群查看topic状态

有什么做得不对的指正一下,在下不胜感激
知识扩展:
1.如果kafka已经输入过内容,查看内容的命令就是
命令:/opt/kafka/kafka_2.12-2.3.1/bin/kafka-consumer-groups.sh --bootstrap-server 192.168.100.242:9092,192.168.100.244:9092,192.168.100.245:9092 --list groupid
#通过zookeeper集群来查看列表组ID
2.查看具体的消费者group的详情信息,需要给出group的名称
命令:/opt/kafka/kafka_2.12-2.3.1/bin/kafka-consumer-groups.sh --bootstrap-server 192.168.100.242:9092,192.168.100.244:9092,192.168.100.245:9092 --group orderdy030_refund --describe
总结:。。。。。。。。。。。(此处省略一万字)
利用zookeeper部署kafka集群的更多相关文章
- 利用新版本自带的Zookeeper搭建kafka集群
安装简要说明新版本的kafka自带有zookeeper,其实自带的zookeeper完全够用,本篇文章以记录使用自带zookeeper搭建kafka集群.1.关于kafka下载kafka下载页面:ht ...
- Zookeeper、Kafka集群与Filebeat+Kafka+ELK架构
Zookeeper.Kafka集群与Filebeat+Kafka+ELK架构 目录 Zookeeper.Kafka集群与Filebeat+Kafka+ELK架构 一.Zookeeper 1. Zook ...
- zookeeper部署及集群测试
zookeeper部署及集群测试 环境 三台测试机 操作系统: centos7 ; hostname: c1 ; ip: 192.168.1.80 操作系统: centos7 ; hostname: ...
- 搭建zookeeper和Kafka集群
搭建zookeeper和Kafka集群: 本实验拥有3个节点,均为CentOS 7系统,分别对应IP为10.211.55.11.10.211.55.13.10.211.55.14,且均有相同用户名 ( ...
- zookeeper及kafka集群搭建
zookeeper及kafka集群搭建 1.有关zookeeper的介绍可参考:http://www.cnblogs.com/wuxl360/p/5817471.html 2.zookeeper安装 ...
- laravel项目利用twemproxy部署redis集群的完整步骤
Twemproxy是一个代理服务器,可以通过它减少Memcached或Redis服务器所打开的连接数.下面这篇文章主要给大家介绍了关于laravel项目利用twemproxy部署redis集群的相关资 ...
- Docker快速搭建Zookeeper和kafka集群
使用Docker快速搭建Zookeeper和kafka集群 镜像选择 Zookeeper和Kafka集群分别运行在不同的容器中zookeeper官方镜像,版本3.4kafka采用wurstmeiste ...
- 使用Docker快速搭建Zookeeper和kafka集群
使用Docker快速搭建Zookeeper和kafka集群 镜像选择 Zookeeper和Kafka集群分别运行在不同的容器中zookeeper官方镜像,版本3.4kafka采用wurstmeiste ...
- docker下部署kafka集群(多个broker+多个zookeeper)
网上关于kafka集群的搭建,基本是单个broker和单个zookeeper,测试研究的意义不大.于是折腾了下,终于把正宗的Kafka集群搭建出来了,在折腾中遇到了很多坑,后续有时间再专门整理份搭建问 ...
随机推荐
- mysql的性能优化简介
mysql性能下降的原因 sql语句本身有问题,或没建索引 索引失效,索引失效的原因本文后面会叙述 关联了过多的表,可能是前期设计缺陷,或者太奇葩的需求 服务器调优及参数设置,例如缓冲.线程等 mys ...
- etcd单节点安装
本篇安装单个etcd,然后进行扩容etcd节点至2个,环境配置如果做了的话就跳过 实验架构 test1: 192.168.0.91 etcd test2: 192.168.0.92 无 test3: ...
- java:Spring框架1(基本配置,简单基础代码模拟实现,spring注入(DI))
1.基本配置: 步骤一:新建项目并添加spring依赖的jar文件和commons-logging.xx.jar: 步骤二:编写实体类,DAO及其实现类,Service及其实现类; 步骤三:在src下 ...
- php配置 php-cgi.sock使用
PHP配置文件: [global]pid = /run/php-fpm/php-fpm.piderror_log = /var/log/php-fpm/php-fpm.loglog_level = n ...
- Linux man及echo的使用
学习目标: 通过本实验掌握man和echo两个命令的用法. 实验步骤: 1.通过man查询ls的详细用法,后面可以跟哪些参数,每个参数的作用.这里主要查找如何禁止ls彩色结果输出. 2.把查找到的参数 ...
- Markdown基础语法总结
目录 区块元素 标题 列表 区块引用 代码区块 分隔线 段落和换行 区段元素 链接 强调 代码 图片 转义 标题 <a name="title"></a> ...
- win10序列号 2019年10月测试
win10序列号 N3415-266GF-AH13H-WA3UE-5HBT4 win10序列号 NPK3G-4Q81M-X4A61-D553L-NV68D win10序列号 N617H-84K11-6 ...
- 2019JAVA第六次实验报告
Java实验报告 班级 计科二班 学号 20188442 姓名 吴怡君 完成时间 2019.10.18 评分等级 实验四 类的继承 实验目的 理解异常的基本概念: 掌握异常处理方法及熟悉常见异常的捕获 ...
- 反复横跳的瞄准线!从向量计算说起!基于射线检测的实现!Cocos Creator!
最近有小伙伴问我瞄准线遇到各种形状该怎么处理?如何实现反复横跳的瞄准线?最近刚好在<Cocos Creator游戏开发实战>中看到物理系统有一个射线检测,于是,基于这个射线检测,写了一个反 ...
- (2.2)【转】mysql的SQL笔记
一千行 MySQL 详细学习笔记 IT技术思维 4月1日 ↑↑↑点上方蓝字关注并星标⭐「IT技术思维」 一起培养顶尖技术思维 作者:格物 原文链接:https://shockerli.net/post ...