Pandas系列(三)-缺失值处理
内容目录
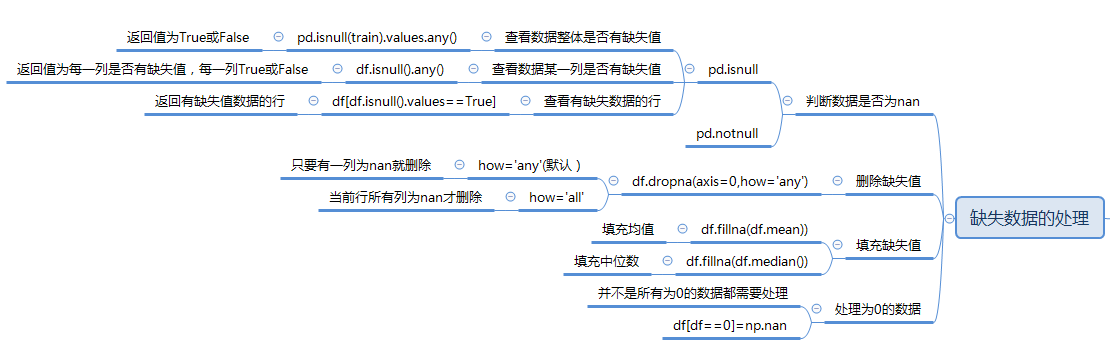
- 1. 什么是缺失值
- 2. 丢弃缺失值
- 3. 填充缺失值
- 4. 替换缺失值
- 5. 使用其他对象填充
数据准备
import pandas as pd
import numpy as np
index = pd.Index(data=["Tom", "Bob", "Mary", "James", "Andy", "Alice"], name="name")
data = {
"age": [18, 30, np.nan, 40, np.nan, 30],
"city": ["BeiJing", "ShangHai", "GuangZhou", "ShenZhen", np.nan, " "],
"sex": [None, "male", "female", "male", np.nan, "unknown"],
"birth": ["2000-02-10", "1988-10-17", None, "1978-08-08", np.nan, "1988-10-17"]
}
user_info = pd.DataFrame(data=data, index=index)
user_info
Out[181]:
age city sex birth
name
Tom 18.0 BeiJing None 2000-02-10
Bob 30.0 ShangHai male 1988-10-17
Mary NaN GuangZhou female None
James 40.0 ShenZhen male 1978-08-08
Andy NaN NaN NaN NaN
Alice 30.0 unknown 1988-10-17
将出生日期转化为日期类型
user_info.birth = pd.to_datetime(user_info.birth)
user_info
Out[182]:
age city sex birth
name
Tom 18.0 BeiJing None 2000-02-10
Bob 30.0 ShangHai male 1988-10-17
Mary NaN GuangZhou female NaT
James 40.0 ShenZhen male 1978-08-08
Andy NaN NaN NaN NaT
Alice 30.0 unknown 1988-10-17
一、什么是缺失值?
可以看到,用户 Tom 的性别为 None,用户 Mary 的年龄为 NAN,生日为 NaT。在 Pandas 的眼中,
这些都属于缺失值,可以使用 isnull() 或 notnull() 方法来操作。
1.判断缺失值
user_info.isna()
Out[183]:
age city sex birth
name
Tom False False True False
Bob False False False False
Mary True False False True
James False False False False
Andy True True True True
Alice False False False False
user_info.isnull()
Out[184]:
age city sex birth
name
Tom False False True False
Bob False False False False
Mary True False False True
James False False False False
Andy True True True True
Alice False False False False
2. 过滤掉年龄为空的用户
user_info[user_info.age.notnull()]
Out[185]:
age city sex birth
name
Tom 18.0 BeiJing None 2000-02-10
Bob 30.0 ShangHai male 1988-10-17
James 40.0 ShenZhen male 1978-08-08
Alice 30.0 unknown 1988-10-17
二、丢弃缺失值
Seriese 使用 dropna 比较简单,对于 DataFrame 来说,可以设置更多的参数。
user_info.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
- axis 参数用于控制行或列,跟其他不一样的是,axis=0 (默认)表示操作行,axis=1 表示操作列。
- how 参数可选的值为 any(默认) 或者 all。any 表示一行/列有任意元素为空时即丢弃,all 一行/列所有值都为空时才丢弃。
- subset 参数表示删除时只考虑的索引或列名。
- thresh参数的类型为整数,它的作用是,比如 thresh=3,会在一行/列中至少有 3 个非空值时将其保留。
#series序列丢弃缺失值
user_info.age.dropna()
Out[187]:
name
Tom 18.0
Bob 30.0
James 40.0
Alice 30.0
Name: age, dtype: float64
#一行数据只要有
user_info.dropna(axis=0,how='any')
Out[188]:
age city sex birth
name
Bob 30.0 ShangHai male 1988-10-17
James 40.0 ShenZhen male 1978-08-08
Alice 30.0 unknown 1988-10-17
# 一行数据所有字段都为空值才删除
user_info.dropna(axis=0,how='all')
Out[189]:
age city sex birth
name
Tom 18.0 BeiJing None 2000-02-10
Bob 30.0 ShangHai male 1988-10-17
Mary NaN GuangZhou female NaT
James 40.0 ShenZhen male 1978-08-08
Alice 30.0 unknown 1988-10-17
# 一行数据中只要 city 或 sex 存在空值即删除
user_info.dropna(axis=0, how="any", subset=["city", "sex"])
Out[190]:
age city sex birth
name
Bob 30.0 ShangHai male 1988-10-17
Mary NaN GuangZhou female NaT
James 40.0 ShenZhen male 1978-08-08
Alice 30.0 unknown 1988-10-17
三、填充缺失值
除了可以丢弃缺失值外,也可以填充缺失值,最常见的是使用 fillna 完成填充。
fillna 这名字一看就是用来填充缺失值的。
填充缺失值时,常见的一种方式是使用一个标量来填充。例如,这里我样有缺失的年龄都填充为 0。
- 除了可以使用标量来填充之外,还可以使用前一个或后一个有效值来填充。
- 设置参数 method='pad' 或 method='ffill' 可以使用前一个有效值来填充。
- 设置参数 method='bfill' 或 method='backfill' 可以使用后一个有效值来填充。
- 除了通过 fillna 方法来填充缺失值外,还可以通过 interpolate 方法来填充。默认情况下使用线性差值,可以是设置 method 参数来改变方式。
user_info.age.fillna(0)
Out[191]:
name
Tom 18.0
Bob 30.0
Mary 0.0
James 40.0
Andy 0.0
Alice 30.0
Name: age, dtype: float64
user_info.age.fillna(method="ffill")
Out[192]:
name
Tom 18.0
Bob 30.0
Mary 30.0
James 40.0
Andy 40.0
Alice 30.0
Name: age, dtype: float64
user_info.age.fillna(method="backfill")
Out[193]:
name
Tom 18.0
Bob 30.0
Mary 40.0
James 40.0
Andy 30.0
Alice 30.0
Name: age, dtype: float64
user_info.age.interpolate()
Out[194]:
name
Tom 18.0
Bob 30.0
Mary 35.0
James 40.0
Andy 35.0
Alice 30.0
Name: age, dtype: float64
四、替换缺失值
例如,在我们的存储的用户信息中,假定我们限定用户都是青年,出现了年龄为 40 的,我们就可以认为这是一个异常值。再比如,我们都知道性别分为男性(male)和女性(female),在记录用户性别的时候,对于未知的用户性别都记为了 “unknown”,很明显,我们也可以认为“unknown”是缺失值。此外,有的时候会出现空白字符串,这些也可以认为是缺失值。对于上面的这种情况,我们可以使用 replace 方法来替换缺失值。
user_info.age.replace(40,np.nan)
Out[195]:
name
Tom 18.0
Bob 30.0
Mary NaN
James NaN
Andy NaN
Alice 30.0
Name: age, dtype: float64
user_info.age.replace({40: np.nan})#制定一个映射字典
Out[196]:
name
Tom 18.0
Bob 30.0
Mary NaN
James NaN
Andy NaN
Alice 30.0
Name: age, dtype: float64
user_info.replace({"age": 40, "birth": pd.Timestamp("1978-08-08")}, np.nan)
Out[197]:
age city sex birth
name
Tom 18.0 BeiJing None 2000-02-10
Bob 30.0 ShangHai male 1988-10-17
Mary NaN GuangZhou female NaT
James NaN ShenZhen male NaT
Andy NaN NaN NaN NaT
Alice 30.0 unknown 1988-10-17
user_info.sex.replace("unknown", np.nan)
Out[198]:
name
Tom None
Bob male
Mary female
James male
Andy NaN
Alice NaN
Name: sex, dtype: object
user_info.city.replace(r'\s+', np.nan, regex=True)
Out[199]:
name
Tom BeiJing
Bob ShangHai
Mary GuangZhou
James ShenZhen
Andy NaN
Alice NaN
Name: city, dtype: object
五、使用其他对象填充
除了我们自己手动丢弃、填充已经替换缺失值之外,我们还可以使用其他对象来填充。
例如有两个关于用户年龄的 Series,其中一个有缺失值,另一个没有,我们可以将没有的缺失值的 Series 中的元素传给有缺失值的。
age_new = user_info.age.copy()
age_new.fillna(20, inplace=True)
age_new
Out[200]:
name
Tom 18.0
Bob 30.0
Mary 20.0
James 40.0
Andy 20.0
Alice 30.0
Name: age, dtype: float64
user_info.age.combine_first(age_new)
Out[201]:
name
Tom 18.0
Bob 30.0
Mary 20.0
James 40.0
Andy 20.0
Alice 30.0
Name: age, dtype: float64
Pandas系列(三)-缺失值处理的更多相关文章
- Pandas系列
系列(Series)是能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组.轴标签统称为索引. pandas.Series Pandas系列可以使用以下构造函数创建 - p ...
- 前端构建大法 Gulp 系列 (三):gulp的4个API 让你成为gulp专家
系列目录 前端构建大法 Gulp 系列 (一):为什么需要前端构建 前端构建大法 Gulp 系列 (二):为什么选择gulp 前端构建大法 Gulp 系列 (三):gulp的4个API 让你成为gul ...
- Web 开发人员和设计师必读文章推荐【系列三十】
<Web 前端开发精华文章推荐>2014年第9期(总第30期)和大家见面了.梦想天空博客关注 前端开发 技术,分享各类能够提升网站用户体验的优秀 jQuery 插件,展示前沿的 HTML5 ...
- MyBatis学习系列三——结合Spring
目录 MyBatis学习系列一之环境搭建 MyBatis学习系列二——增删改查 MyBatis学习系列三——结合Spring MyBatis在项目中应用一般都要结合Spring,这一章主要把MyBat ...
- MySQL并发复制系列三:MySQL和MariaDB实现对比
http://blog.itpub.net/28218939/viewspace-1975856/ 并发复制(Parallel Replication) 系列三:MySQL 5.7 和MariaDB ...
- WCF编程系列(三)地址与绑定
WCF编程系列(三)地址与绑定 地址 地址指定了接收消息的位置,WCF中地址以统一资源标识符(URI)的形式指定.URI由通讯协议和位置路径两部分组成,如示例一中的: http://loc ...
- 【JAVA编码专题】 JAVA字符编码系列三:Java应用中的编码问题
这两天抽时间又总结/整理了一下各种编码的实际编码方式,和在Java应用中的使用情况,在这里记录下来以便日后参考. 为了构成一个完整的对文字编码的认识和深入把握,以便处理在Java开发过程中遇到的各种问 ...
- SQL Server 2008空间数据应用系列三:SQL Server 2008空间数据类型
原文:SQL Server 2008空间数据应用系列三:SQL Server 2008空间数据类型 友情提示,您阅读本篇博文的先决条件如下: 1.本文示例基于Microsoft SQL Server ...
- VSTO之旅系列(三):自定义Excel UI
原文:VSTO之旅系列(三):自定义Excel UI 本专题概要 引言 自定义任务窗体(Task Pane) 自定义选项卡,即Ribbon 自定义上下文菜单 小结 引言 在上一个专题中为大家介绍如何创 ...
- 系列三VisualSvn Server
原文:系列三VisualSvn Server VisualSvn Server介绍 1 .VisualSvn Server VisualSvn Server是免费的,而VisualSvn是收费的.V ...
随机推荐
- python模块shutil
shutil.copyfileobj(fsrc, fdst,[ length]) 拷贝文件句柄,将类文件对象fsrc的内容复制到类文件对象fdst.如果给定整数长度,则为缓冲区大小.如果长度是负值意味 ...
- c/c++ 多线程 boost的读写(reader-writer)锁
多线程 boost的读写(reader-writer)锁 背景:保护很少更新的数据结构时,c++标准库没有提供相应的功能. 例如:有个DNS条目缓存的map,基本上很少有更新,大部分都是读取,但是偶尔 ...
- formatter的使用
1.目的 如图所示,实现行编辑栏中的编辑删除,以及在时间建议中显示上中下旬 可参考easyui官方文档中所写的关于datagrid列属性:http://www.jeasyui.net/plugins/ ...
- isinstance_issubclass
isinstance和issubclass分别是检验是不是对象是不是类的实例化,和子类是不是这个父类的子类 class A:pass class B(A):pass a = A() print(isi ...
- Python小数据池和字典操作
小数据池 #id 查看内存地址 #多个代码块可以使用小数据池 #一个代码块中有一个问题,就是重复使用 #数字 -5~256 #字符串 字符串 乘法总数长度不能超过20, 0,1除外 #不能有特殊字符 ...
- fliplr函数
fliplr 左右翻转矩阵 语法: B = fliplr(A) 将矩阵A的列绕垂直轴进行左右翻转 matabc 如果A是一个行向量,fliplr(A)将A中元素的顺序进行翻转. 如果A是一个列向量, ...
- 时序数据库InfluxDB:简介及安装
在性能测试过程中,对测试结果以及的实时监控与展示也是很重要的一部分.这篇博客,介绍下linux环境下InfluxDB的安装以及功能特点. 官网地址:influxdata 官方文档:influxdb文档 ...
- 《通过C#学Proto.Actor模型》之 HelloWorld
在微服务中,数据最终一致性的一个解决方案是通过有状态的Actor模型来达到,那什么是Actor模型呢? Actor是并行的计算模型,包含状态,行为,并且包含一个邮箱,来异步处理消息. 关于Actor的 ...
- go笔记-熔断器
参考: https://studygolang.com/articles/13254 区别:(限速器 VS 熔断器) 限速器(limiter)可以限制接口自身被调的频率 熔断器可监控所调用的服务的失败 ...
- C++笔记--thread pool【转】
版权声明:转载著名出处 https://blog.csdn.net/gcola007/article/details/78750220 背景 刚粗略看完一遍c++ primer第五版,一直在找一些c+ ...