朴素贝叶斯法(naive Bayes algorithm)
对于给定的训练数据集,朴素贝叶斯法首先基于iid假设学习输入/输出的联合分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。
一、目标
设输入空间 是n维向量的集合,输出空间为类标记集合
是n维向量的集合,输出空间为类标记集合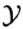 = {c1, c2, ..., ck}。X是定义在上的随机变量,Y是定义在上的随机变量。P(X, Y)是X和Y的联合概率分布。训练数据集 T = {(x1, y1), (x2, y2), ..., (xN, yN)}由P(X, Y)独立同分布产生。
= {c1, c2, ..., ck}。X是定义在上的随机变量,Y是定义在上的随机变量。P(X, Y)是X和Y的联合概率分布。训练数据集 T = {(x1, y1), (x2, y2), ..., (xN, yN)}由P(X, Y)独立同分布产生。
朴素贝叶斯法的学习目标是习得联合概率分布P(X, Y),以此计算后验概率,从而将实例分到后验概率最大的类中。由于P(X, Y) = P(Y)P(X|Y),因此学习目标可以具体到先验概率分布P(Y = ck)和条件概率分布P(X = x|Y = ck)(k = 1, 2, ..., K)。
二、后验概率最大化的原理
最大化后验概率等价于最小化期望损失(expected loss),或者说条件风险(conditional risk)。设选择0-1损失函数
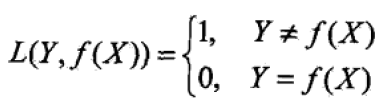
其中f(X)是分类决策函数,则期望损失为
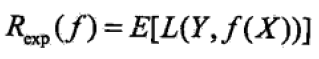
由于期望是对联合分布P(X, Y)取的,因此上式可推出

由贝叶斯判定准则(Bayes decision rule):最小化总体风险,只需在每个样本上选择那个能使条件风险最小的类别标记。于是

这样一来,根据期望风险最小化准则就得到后验概率从最大化准则:

另一方面,由条件独立性假设
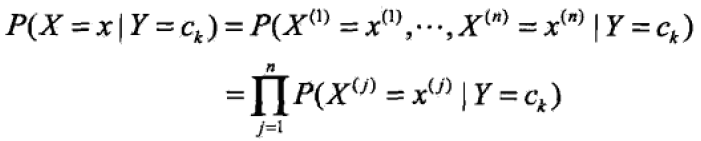
与贝叶斯定理
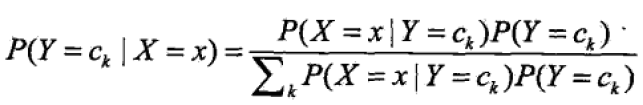
得到
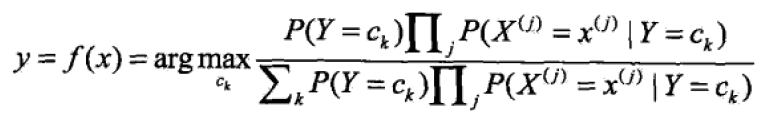
由于上式中分布对ck都是相同的,因此
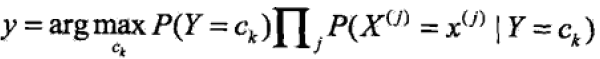
三、参数估计:极大似然估计
先验概率P(Y = ck)的极大似然估计:
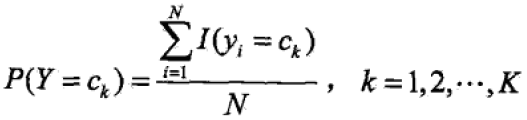
条件概率P(X(j) = ajl|Y = ck)的极大似然估计:

其中设第j个特征x(j)可能的取值集合为{aj1, aj2, ..., ajSj},I为指示函数。
四、算法伪码及实现
书中给中了算法的伪码

下面给出朴素贝叶斯算法的具体实现
『python』代码摘自https://www.cnblogs.com/yiyezhouming/p/7364688.html
#coding:utf-8
# 极大似然估计 朴素贝叶斯算法
import pandas as pd
import numpy as np class NaiveBayes(object):
def getTrainSet(self):
dataSet = pd.read_csv('C://pythonwork//practice_data//naivebayes_data.csv')
dataSetNP = np.array(dataSet) #将数据由dataframe类型转换为数组类型
trainData = dataSetNP[:,0:dataSetNP.shape[1]-1] #训练数据x1,x2
labels = dataSetNP[:,dataSetNP.shape[1]-1] #训练数据所对应的所属类型Y
return trainData, labels def classify(self, trainData, labels, features):
#求labels中每个label的先验概率
labels = list(labels) #转换为list类型
P_y = {} #存入label的概率
for label in labels:
P_y[label] = labels.count(label)/float(len(labels)) # p = count(y) / count(Y) #求label与feature同时发生的概率
P_xy = {}
for y in P_y.keys():
y_index = [i for i, label in enumerate(labels) if label == y] # labels中出现y值的所有数值的下标索引
for j in range(len(features)): # features[0] 在trainData[:,0]中出现的值的所有下标索引
x_index = [i for i, feature in enumerate(trainData[:,j]) if feature == features[j]]
xy_count = len(set(x_index) & set(y_index)) # set(x_index)&set(y_index)列出两个表相同的元素
pkey = str(features[j]) + '*' + str(y)
P_xy[pkey] = xy_count / float(len(labels)) #求条件概率
P = {}
for y in P_y.keys():
for x in features:
pkey = str(x) + '|' + str(y)
P[pkey] = P_xy[str(x)+'*'+str(y)] / float(P_y[y]) #P[X1/Y] = P[X1Y]/P[Y] #求[2,'S']所属类别
F = {} #[2,'S']属于各个类别的概率
for y in P_y:
F[y] = P_y[y]
for x in features:
F[y] = F[y]*P[str(x)+'|'+str(y)] #P[y/X] = P[X/y]*P[y]/P[X],分母相等,比较分子即可,所以有F=P[X/y]*P[y]=P[x1/Y]*P[x2/Y]*P[y] features_label = max(F, key=F.get) #概率最大值对应的类别
return features_label if __name__ == '__main__':
nb = NaiveBayes()
# 训练数据
trainData, labels = nb.getTrainSet()
# x1,x2
features = [2,'S']
# 该特征应属于哪一类
result = nb.classify(trainData, labels, features)
print features,'属于',result
朴素贝叶斯法(naive Bayes algorithm)的更多相关文章
- PGM:贝叶斯网表示之朴素贝叶斯模型naive Bayes
http://blog.csdn.net/pipisorry/article/details/52469064 独立性质的利用 条件参数化和条件独立性假设被结合在一起,目的是对高维概率分布产生非常紧凑 ...
- 【机器学习速成宝典】模型篇05朴素贝叶斯【Naive Bayes】(Python版)
目录 先验概率与后验概率 条件概率公式.全概率公式.贝叶斯公式 什么是朴素贝叶斯(Naive Bayes) 拉普拉斯平滑(Laplace Smoothing) 应用:遇到连续变量怎么办?(多项式分布, ...
- 【机器学习实战】第4章 朴素贝叶斯(Naive Bayes)
第4章 基于概率论的分类方法:朴素贝叶斯 朴素贝叶斯 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本章首先介绍贝叶斯分类算法的基础——贝叶斯定理.最后,我们 ...
- 【Spark机器学习速成宝典】模型篇04朴素贝叶斯【Naive Bayes】(Python版)
目录 朴素贝叶斯原理 朴素贝叶斯代码(Spark Python) 朴素贝叶斯原理 详见博文:http://www.cnblogs.com/itmorn/p/7905975.html 返回目录 朴素贝叶 ...
- 朴素贝叶斯(Naive Bayes)
1.朴素贝叶斯模型 朴素贝叶斯分类器是一种有监督算法,并且是一种生成模型,简单易于实现,且效果也不错,需要注意,朴素贝叶斯是一种线性模型,他是是基于贝叶斯定理的算法,贝叶斯定理的形式如下: \[P(Y ...
- 朴素贝叶斯(naive bayes)算法及实现
处女文献给我最喜欢的算法了 ⊙▽⊙ ---------------------------------------------------我是机智的分割线----------------------- ...
- 深入理解朴素贝叶斯(Naive Bayes)
https://blog.csdn.net/li8zi8fa/article/details/76176597 朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.朴素贝叶斯原理简 ...
- 模式识别之贝叶斯---朴素贝叶斯(naive bayes)算法及实现
处女文献给我最喜欢的算法了 ⊙▽⊙ ---------------------------------------------------我是机智的分割线----------------------- ...
- 【分类算法】朴素贝叶斯(Naive Bayes)
0 - 算法 给定如下数据集 $$T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\},$$ 假设$X$有$J$维特征,且各维特征是独立分布的,$Y$有$K$种取值.则 ...
- 朴素贝叶斯分类器Naive Bayes
优点Naive Bayes classifiers tend to perform especially well in one of the following situations: When t ...
随机推荐
- 关于TCP和MQTT之间的转换(转载)
现在物联网流行的就是MQTT 其实MQTT就是在TCP的基础上建立了一套协议 可以看这个,本来我自己想用Wireshark监听一下,不过百度一搜索一大把,我就不测试了 https://blog.csd ...
- 深入理解Python字符编码
不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久,你一定遇到过UnicodeEncodeError.UnicodeDecodeError 错误,每当遇到错误我们就拿着 enc ...
- SQL性能优化十条经验,后台程序员都需要掌握
1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE '%parm1%'—— 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用. 解决办法: 其实只需要对该脚本略做改进,查询速度便会 ...
- Window中显示文件扩展名
积少成多,欢迎大家关注我的微信公众号,共同探讨Java相关技术 本文主要介绍如何在Windows系统中怎么让文件显示扩展名. 操作步骤 打开控制面板 找到外观和个性化 找到文件资源管理器选项 单击,然 ...
- SQL的修炼
查询所有区有多少人,从而得知一个区有多少设备. ###############################################select o2.ORG_ENDDATE as name ...
- 03MYSQL数据库
mySQL 数据库 储存数据,属于中小型数据库 默认端口号 3306 密码root sql是一门编程语言 结构化查询语言 是强类型语言(定义变量时要指定变量类型) 字符串有两种类型: 定长: ...
- linux 修改配色
PS1="\[\e[37;40m\][\[\e[32;40m\]\u\[\e[37;40m\]@\h \[\e[36;40m\]\w\[\e[0m\]]\\$ " ORvim ~/ ...
- Linux安装MySQL_5.6
E&T: CentOS_7.4 64位; mysql-5.6.42-linux-glibc2.12-x86_64.tar; Xftp5; Xshell5; P1.下载Linux环境下的MySQ ...
- javascript 操作节点的属性
使用层次关系访问节点 parentNode:返回节点的父节点 childNodes:返回子节点集合,childNodes[i] firstChild:返回节点的第一个子节点,最普遍的用法是访问该元素的 ...
- HNOI2006公路修建问题
https://www.luogu.org/problemnew/show/P2323 [题目描述] OI island是一个非常漂亮的岛屿,自开发以来,到这儿来旅游的人很多.然而,由于该岛屿刚刚开发 ...