MyCat | 分库分表实践
引言
先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。
切分模式
一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
为什么用MyCat
不管怎么来说,数据切分虽然分散了单台服务器负载,但是带来了是设计和开发的复杂度。MyCat是一个开源的分布式数据库中间件,实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信,在MyCat里,我们面向的是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
分库分表实践
基本环境
操作系统:CentOS / 7.1 (64bit)
JDK:1.8
MySQL:5.7
MyCat:1.6
业务目标
比如说我们现在有个实际的业务上设计需求,要将student和grade表进行垂直划分,分别存储不同的database中;还需要将student水平拆分,也要3个不同database存分别储。如下图所示,MyCat可以帮助实现这4个database的管理,而对于终端用户来说,就像只操作student和grade两张表,保证了中间件分库分页对程序员的透明性。
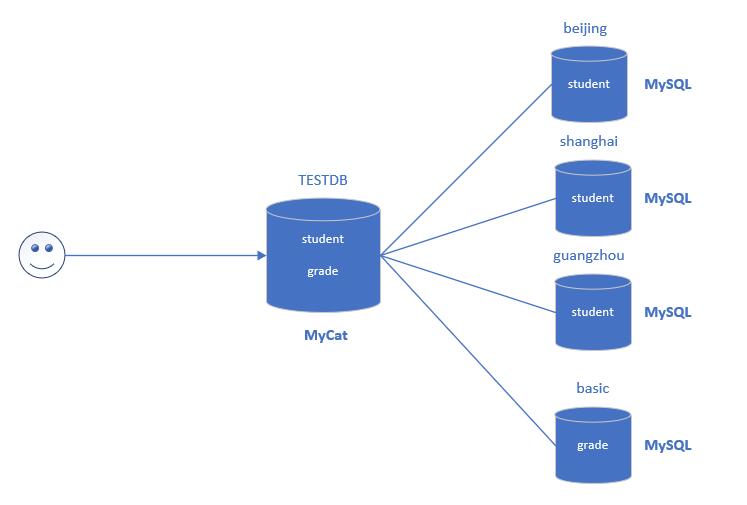
创建实际数据库
首先,我们肯定需要创建4个database:beijing、shanghai、guangzhou、basic,并生成对应的表。可以看出,student和grade表存在于不同的数据库,而且student表中的数据,分散存储在3个不同的数据库中:
create database beijing;
use beijing;
create table student(
id int primary key,
name varchar(8) not null,
grade int not null
);
create database shanghai;
use shanghai;
create table student(
id int primary key,
name varchar(8) not null,
grade int not null
);
create database guangzhou;
use guangzhou;
create table student(
id int primary key,
name varchar(8) not null,
grade int not null
);
create database basic;
use basic;
create table grade(
id int primary key,
name varchar(8) not null
);
安装配置MyCat
比较简单,下载Mycat-1.6-RELEASE,直接解压缩即可。
为了方便,将/mycat/bin目录添加到环境变量:
/etc/profile文件后增加设置export PATH=/data/mycat/bin:$PATH
让profile立即生效:
# source /etc/profile
配置server
编辑\mycat\conf\server.xml:
<user name="test">
<property name="password">test</property>
<property name="schemas">TESTDB</property>
</user>
这里MyCat会帮助我们生成一个虚拟的逻辑database,我们命名为TESTDB,并设置可以访问的用户名和密码,默认访问的端口号8066,其实MyCat还会提供一个管理端口:9066,方便我们对MyCat管理和监测,这个我们以后有机会再说。
配置schema
编辑\mycat\conf\schema.xml:
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- 取模分片 -->
<table name="student" primaryKey="id" dataNode="dn1,dn2,dn3" rule="mod-long" />
<table name="grade" primaryKey="id" dataNode="dn4"/>
</schema>
<!-- 申明节点对应的database -->
<dataNode name="dn1" dataHost="localhost1" database="beijing" />
<dataNode name="dn2" dataHost="localhost1" database="shanghai" />
<dataNode name="dn3" dataHost="localhost1" database="guangzhou" />
<dataNode name="dn4" dataHost="localhost1" database="basic" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可读写的数据库实例 -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="******">
</writeHost>
</dataHost>
</mycat:schema>
schema是比较重要的一块配置,主要维护了虚拟库与实际库的映射关系:
可以看到,虚拟的逻辑库TESTDB中维护了2张表student和grade;
grade对应存储在实际的数据库节点dn4,也就是basic;
而student被拆分为存储在3个实际的数据库节点,分别是beijing、shanghai、guangzhou,分片的算法取模,根据取模映射到不同的节点;
最后,我们将实际的访问地址、访问权限配置完成,当然,这里还可以配置主从/读写分离配置,这块不是本文讨论的重点,我们以后单独说。
启动MyCat
这时候,我们敲入命令:# mycat start ,正常的话可以启动MyCat,输入# mycat status,可以查看是否运行正常,如果运行停止,证明启动有误,可以进入控制台启动,# mycat console,进行调试。(有可能报内存错误,一般是由于配置java虚拟机的默认大小的问题,我们可以根据命令行的提示,去wrapper.conf中修改)

MyCat插入和查询
MyCat启动后,我们就可以连接MyCat帮我们生成的逻辑库了:
# mysql -utest -ptest -h127.0.0.1 -P8066 -DTESTDB
接下来,我们在逻辑库中插入一下数据验证一下:
insert into grade (id,name) values (1,'一年级');
insert into grade (id,name) values (2,'二年级');
insert into grade (id,name) values (3,'三年级');
insert into student (id,name,grade) values (1,'张三',2);
insert into student (id,name,grade) values (2,'李四',1);
insert into student (id,name,grade) values (3,'王五',3);
insert into student (id,name,grade) values (4,'甲',3);
insert into student (id,name,grade) values (5,'乙',2);
insert into student (id,name,grade) values (6,'丙',1);
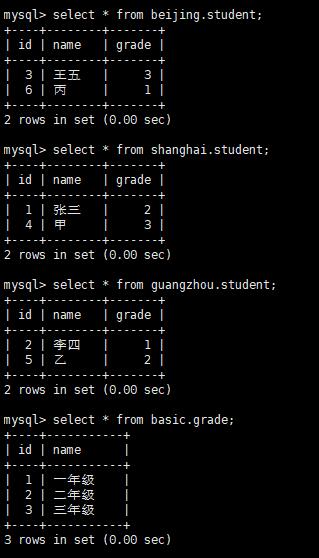
我们插入了6条student记录,这时应该根据不同的取模结果,存在不同的实际数据库的student表中,所以我们切换到实际数据库:# mysql -uroot -ppassword
分别查看实际数据库:
再看此时的逻辑数据库:
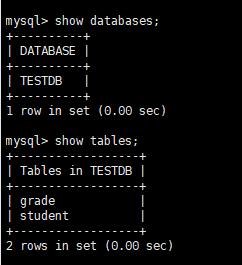
逻辑数据库,查询grade和student两张表,已经数据聚合,还可以进行排序;
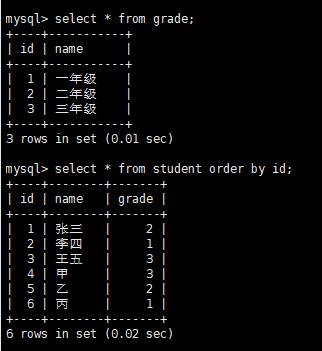
如果我们需要将2张表进行关联,也是可以的:
/*!mycat:catlet=io.mycat.catlets.ShareJoin */select * from student s,grade g on s.grade=g.id where g.name='一年级';

附录

MyCat | 分库分表实践的更多相关文章
- 分布式数据库中间件 MyCat | 分库分表实践
MyCat 简介 MyCat 是一个功能强大的分布式数据库中间件,是一个实现了 MySQL 协议的 Server,前端人员可以把它看做是一个数据库代理中间件,用 MySQL 客户端工具和命令行访问:而 ...
- MySQL+MyCat分库分表 读写分离配置
一. MySQL+MyCat分库分表 1 MyCat简介 java编写的数据库中间件 Mycat运行环境需要JDK. Mycat是中间件.运行在代码应用和MySQL数据库之间的应用. 前身 : cor ...
- 《MyCat分库分表策略详解》
在我们的项目发展到一定阶段之后,随着数据量的增大,分库分表就变成了一件非常自然的事情.常见的分库分表方式有两种:客户端模式和服务器模式,这两种的典型代表有sharding-jdbc和MyCat.所谓的 ...
- MariaDB Spider 数据库分库分表实践
分库分表 一般来说,数据库分库分表,有以下做法: 按哈希分片:根据一条数据的标识计算哈希值,将其分配到特定的数据库引擎中: 按范围分片:根据一条数据的标识(一般是值),将其分配到特定的数据库引擎中: ...
- 3.Mysql集群------Mycat分库分表
前言: 分库分表,在本节里是水平切分,就是多个数据库里包含的表是一模一样的. 只是把字段散列的分到不同的库中. 实践: 1.修改schema.xml 这里是在同一台服务器上建立了4个数据库db1,db ...
- mycat 分库分表
单库分表已经在上篇写过了,这次写个分库分表,不同在于配置文件上的一点点不同 <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> &l ...
- MyCat分库分表入门
1.分区 对业务透明,分区只不过把存放数据的文件分成了许多小块,例如mysql中的一张表对应三个文件.MYD,MYI,frm. 根据一定的规则把数据文件(MYD)和索引文件(MYI)进行了分割,分区后 ...
- 分库分表实践-Sharding-JDBC
最近一段时间在研究分库分表的一些问题,正好周末有点时间就简单做下总结,也方便自己以后查看. 关于为什么要做分库分表,什么是水平分表,垂直分表等概念,相信大家都知道,这里就不在赘述了. 本文只讲述使用S ...
- Mycat分库分表(一)
随着业务变得越来越复杂,用户越来越多,集中式的架构性能会出现巨大的问题,比如系统会越来越慢,而且时不时会宕机,所以必须要解决高性能和可用性的问题.这个时候数据库的优化就显得尤为重要,在说优化方案前,先 ...
随机推荐
- 算法与数据结构(十一) 平衡二叉树(AVL树)(Swift版)
今天的博客是在上一篇博客的基础上进行的延伸.上一篇博客我们主要聊了二叉排序树,详情请戳<二叉排序树的查找.插入与删除>.本篇博客我们就在二叉排序树的基础上来聊聊平衡二叉树,也叫AVL树,A ...
- vue-router路径计算问题
简书原文 昨天刚刚发表了一个前端跨域新方案尝试,今天在开发中就遇到的了问题. 起因 前端使用的是vue-router组件的history模式,但是由于我们的整个页面都是从static(静态资源站)lo ...
- 基于Java实现简化版本的布隆过滤器
一.布隆过滤器: 布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率 ...
- PHP workMan webSocket 转发器
PHP WorkerMan webSocket 功能演示===================================== 基本功能:实现页面websocket之间互相通讯 start_deb ...
- 3种方法来在Linux电脑上查找文件
如果你不太了解Linux命令,那么在Linux系统里查找文件是比较困难的.只要使用多种不同的终端命令,可以很快地找到文件.Linux命令比其它操作系统的搜索功能更加强大,掌握这些命令就能你完全控制这些 ...
- Web前端-Vue.js必备框架(三)
Web前端-Vue.js必备框架(三) vue是一款渐进式javascript框架,由evan you开发.vue成为前端开发的必备之一. vue的好处轻量级,渐进式框架,响应式更新机制. 开发环境, ...
- [Swift]LeetCode479. 最大回文数乘积 | Largest Palindrome Product
Find the largest palindrome made from the product of two n-digit numbers. Since the result could be ...
- 剖析项目多个logback配置(下)
来源:http://www.cnblogs.com/guozp/p/5973038.html 上篇大概描述了logback的加载顺序以及加载的源码,本篇将分析如果在你的Maven或者其他多模块的项目中 ...
- 使用xUnit为.net core程序进行单元测试 -- Assert
第一部分: http://www.cnblogs.com/cgzl/p/8283610.html Assert Assert做什么?Assert基于代码的返回值.对象的最终状态.事件是否发生等情况来评 ...
- 抓包工具Charles的使用教程
参考:https://zhubangbang.com/charlesproxy 如果您是您一次使用Charles,可能对下面的感兴趣. Charles破解版免费下载和安装教程 Charles手机抓包设 ...