计算机网络Web应用层与运输层(HTTP/TCP)
- 应用层协议原理
- Web和HTTP
- DNS:英特网的目录服务
- 运输层
- 面向连接的运输:TCP及拥塞原理
一、应用层协议原理
DNS域名解析:
(用例:www.baidu.com)域名解析是网络请求的第一步操作,DNS域名解析首先是在浏览器缓存中匹配历史对应域名的IP地址,如果没有找到就到计算机的网络访问缓存中匹配,如果还找不到匹配的IP地址,就会将域名发送到根权威服务器上(com),然后再根权威服务器上匹配到域名(baidu)的服务器IP地址返回发送回客服端上。
网络连接实质上是基于IP地址来建立网络连接,最后实现数据传送。比如我们可以通过控制台然后使用ping命令查看到www.baidu.com的IP地址,然后可以直接将IP地址输入网址栏,照样可以获取到百度的主页。例如:

然后再地址栏输入:https://119.75.217.109/照样可以访问到百度首页。
这里主要就网络访问一些过程做一些说明,后面有对DNS有具体的解析
有了IP地址,相当于才能真正找到服务器,IP作为每台网络计算机的唯一标识。这时候开始尝试建立网络通路,实现数据传输,也就有了三次握手和四次挥手的环节。网络应用通信的实际上进程,web应用是由客户端的浏览器进程和web服务器的进程交换报文。
套字节:即软件接口向网络发送报文和从网络接收报文。套字节是同一台主机内应用层与运输层的接口,由于该套字节是建立网络应用程序的可编程接口,因此套字节也是应用程序和网络之间的应用程序编程接口。应用程序开发者可以控制套字节在应用层端的一切,但是对该套字节的运输层端几乎没有控制权。应用程序开发者对于运输层的控制权仅限于:1.选择运输层协议;2.也许能设定几个运输层参数,如最大缓存和最大报文段长度等。(《计算机网络》59页)
除了将报文发送到目标服务器,还必须指定运行在接受主机上的接收进程。也可以说是端口号。通常web服务器端口号用80来标识。
可供应用程序使用的运输服务:
- 可靠数据传输:发送进程只要将其数据传递进套字节,就可以完全相信该数据将能无差错地到达接收进程。(数据不丢失)
- 吞吐量:运输层协议能够以某种特定的速率提供确保的可用吞吐量,使用这种服务能够确保可用吞吐量总是为至少r比特/秒(带宽敏感应用:(例)网络电话);弹性应用能够根据情况或多或少地利用可供使用的吞吐量。电子邮件、文件传输、以及web传送都属于弹性应用。
- 定时:运输层能提供定时保证(时间敏感)。因特网电话、虚拟环境、电话会议和多方游戏都需要严格的事件限制。
- 安全性:运输协议能够为应用程序提供一种或多种安全性服务。(对发送进程传输的所有数据加密)
因特网(一般是TCP/IP网络)为应用提供两层运输协议,即UDP和TCP。下面是常见应用程序的服务要求:
| 应用 | 数据丢失 | 带宽 | 时间敏感 |
| 文件传输 | 不能丢失 | 弹性 | 不 |
| 电子邮件 | 不能丢失 | 弹性 | 不 |
| Web文档 | 不能丢失 | 弹性(几kbps) | 不 |
| 因特网电话/视频会议 | 容忍丢失 | 音频(几kbps~1Mbps)/视频(10kbps~5Mbps) | 是,100ms |
| 存储音频/视频 | 容忍丢失 | 音频(几kbps~1Mbps)/视频(10kbps~5Mbps) | 是,几秒 |
| 交互式游戏 | 容忍丢失 | 几kbps~10kbps | 是,100ms |
| 即时通讯 | 不能丢失 | 弹性 | 是和不是 |
TCP服务:1.面向连接的服务:在应用层数据报文开始流动之前,TCP让客户和服务器相互交换运输层控制信息。这就是握手过程,这条连接是双工的,即连接双方的进程可以在此连接上同时进行报文收发。当应用程序结束报文发送时,必须拆除该链接,也就是挥手过程。2.可靠的数据服务,也就是数据层的可靠数据传输。然后,TCP协议还具有拥塞控制机制,这种服务不一定能为通信进程带来直接好处,但能为因特网带来整体好处。当发送方和接受方之间的网络出现拥塞时,TCP的拥塞控制机制会抑制发送进程(客户端或服务器)。
UDP服务:是一种不提供不必要服务的轻量级运输协议,它仅提供最小服务。UDP是无法连接,两个进程通信前没有握手过程。当进程将一个报文发送进UDP套字节时,UDP协议并不保证该报文将到达接受进程,并且到达接收进程的报文也可能是乱序到达。UDP没有拥塞机制,所以UDP的发送端可以用选定的任何速率向其下层注入数据(实际端到端吞吐量可能小于这个速率,这可能是因为中间链路的带宽受限或因为拥塞而造成的)。
因特网运输协议不提供的服务:吞吐量和定时保证,但不意味着因特网电话这样的时间敏感应用不能运行在因特网上,因为因特网上运行时间敏感应用已经有多年了(以后有机会对多媒体网络这部分重点分析:)。
流行的因特网引用及其应用层协议和支撑的运输协议:
| 应用 | 用户层协议 | 支撑的运输层协议 |
| 电子邮件 | SMTP [RFC 5321] | TCP |
| 远程终端访问 | Telnet [RFC 854] | TCP |
| Web | HTTP [RFC 2616] | TCP |
| 文件传输 | FTP [RFC 959] | TCP |
| 流式多媒体 | HTTP(如YouTube) | TCP |
| 因特网电话 | SIP [RFC 3261]、RTP [RFC 3550]、或专用的(如Skype) | UDP或TCP |
二、Web和HTTP协议
Web的应用层协议是超文本传输协议(HyperText Transfer Protocol,HTTP),它是Web的核心,在[RFC 1945]和[RFC 2616]中进行了定义。HTTP有两个程序实现:一个客户端程序和一个服务器程序。客户程序和服务器程序运行在不同的端系统中,通过交换HTTP报文进行会话。HTTP定义了这些报文的结构以及客户和服务器进行报文交换的方式。因为HTTP服务器并不保存关于客户的任何信息,假如某个特定的客户在短短几秒钟内两次请求同一个对象,服务器也响应两次,将同一个对象重复发送给客户,所以HTTP是一个无状态协议。
持续连接与非持续连接:
客户和服务器在一个相当长的时间范围内通信,其客户发出一系列请求并且服务器对每个请求进行响应。这一系列的请求可以以规则的间隔周期性地或者间断性地一个接一个发出。当客户与服务的交互时,每个请求/响应是经单独的TCP连接发送还是所有请求即响应都是经过相同的一个TCP连接发送。每个单独的TCP连接被称为非持续连接,经过相同的一个TCP连接被称为持续连接,持续连接在一定时间内没有发生请求HTTP服务器就会关闭连接。HTTP能够使用非持续连接也能使用持续连接,各有优缺点。
每一个HTTP请求都需要经过三次握手建立连接传输文件,这个过程需要两次往返时间(RTT),会产生一定的网络延时。持续连接可以在一定程度上减少这种重复的握手连接过程,但是多个请求采用一个TCP连接需要等待一个一个的传输,在一定程度上可以减少网络延时,但也产生了等待执行的时间。持续连接相对非持续连接在很大程度上减少了服务器的压力,但是性能问题是由多种因素造成的,量化比较持续连接和非持续连接对于优化性能非常有必要(《计算机网络》69页)参考文献[Heidemann 1997; Nielsen 1997]。
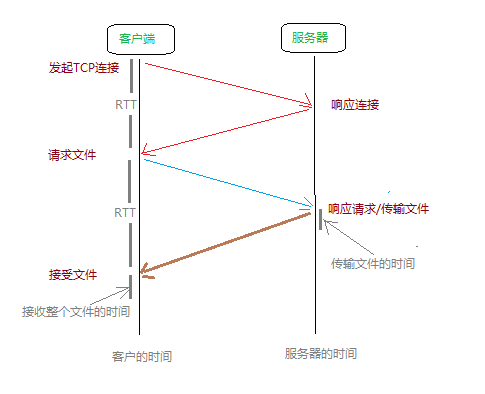
这就是常说的三次握手过程,这个过程我们需要重点关注的是往返时间(RTT)和传输文件的时间,这也是web开发中优化的重要部分。第一次握手:客服端发起TCP连接;第二次握手:服务端响应连接;第三次握手:客服端请求文件;接下来就是服务端响应文件请求,开始文件传输。
HTTP报文:
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection: close
User-agent:Mozilla/5.0
Accept-language: fr
报文使用普通的ASCII文本书写的,上面是个请求报文内容总共就5行代码,每行由一个回车和换行符结束,最后一行后一行后再附加一个回车换行符。第一行叫做请求行,第二行叫做首部行,Connection表示连接方式,User-agent用来指明代理,Accept-language表示想获得对象的语法版本。
请求行三个字段:方法字段、URL字段、HTTP版本字段。方法字段可取几种不同的值,包括GET、POST、HEAD、PUT和DELETE。URL字段带有请求对象的标识(page.html),这里的版本字段实现的是HTTP/1.1版本。
首部行Host指明了对象所在的主机,首部提供的信息是Web代理高速缓存所要求的。其他的部分再HTTP协议分析博客中具体解析。
请求报文格式:
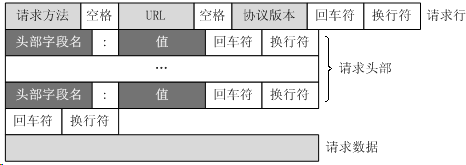
一个HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据4个部分组成,上图给出了请求报文的一般格式。可以看到在最后一行有一个请求数据,请求数据也叫做请求的实体主体,这是请求行中使用POST方法请求才会使用该实体。但不能说POST就是唯一的提交请求数据的唯一方法,GET方法请求可以在URL中输入数据https://www.baidu.com/baidu?word=Connection;其中的word=Connection就是一组请求数据,当然还可以使用&&连接多个请求数据。接着我们再来看前面的请求示例对应的响应报文:
HTTP/1.1 200 OK
Connection: close
Date:tue, 09 Aug 2011 15:44:04 GMT
Server:Apache/2.2.3(CentOS)
Last-Modified:Tue, 09 Aug 2011 15:11:03 GMT
Content-length:6821
Content-Type:text/html (data data data data data ...)
响应报文的第一行是状态行,然后是首部(这里首部共六行),然后是实体(响应实体)。
状态行三个字段:协议版本字段、状态码字段、相应状态信息。这里重点提一下状态码和相应状态信息,然后响应首部到HTTP协议分析博客中具体介绍。下面是一些常见的状态码和相关的短语:
- 200 OK:请求成功,信息在返回的响应报文中。
- 301 Moved Permanently:请求的对象已经被永久转移了,新的URL定义在响应报文的Location:首部中。客户软件将自动获取新的URL。
- 400 Bad Request:一个通用查错代码,指示该请求不能被服务器理解。
- 404 Not Found:被请求的文档不在服务器上。
- 505 HTTP Version Not Supported:服务器不支持请求报文中的HTTP协议。
最后介绍在window上的网络请求命令:curl 。这篇博客介绍了curl的用法什么是curl命令?。
用户与服务器的交互:cookie
前面提到HTTP服务器是无状态的,那同时处理数千计甚至更大的访问时怎么识别用户呢?当然你可以使用关系型数据库记录的用户标识,如果你不考虑性能的话可以这么做。现在HTTP协议有一种存在请求报文上的识别标识,相对来说就好多了,这就是cookie,cookie是由服务端通过HTTP协议和浏览器设置在客户端的一个标识,这个标识可以设置一些简单的信息,还可以设置它的生命周期。
但是cookie并不是最佳选择,因为cookie不安全而且浏览器可以主动设置屏蔽cookie,所以这时候又有了服务端的session,这已经不在HTTP范畴了,后期相关博客具体介绍cookie和session的使用方法再解析。随着技术的进步,web基于HTTP的无状态解决方案也越来越多,有机会再详细介绍。
如果本地缓存了用户某个站点的cookie信息,在用户每次登入该站点时HTTP报文头部都会通过cookie头部行传送给服务器,服务器通过Set-cookie响应头部行设置客户端的cookie。
web缓存
web缓存器(Web cache)也叫代理服务器(proxy server),它是能够代表初始Web服务器来满足HTTP请求的网络实体。Web缓存器有自己的磁盘存储空间,并在存储空间中保存最近请求过的对象的副本,使得用户所有HTTP请求首先指向Web缓冲器。下面具体描述客户端通过web缓存器请求资源的全部经过:
- 浏览器建立一个到Web缓存器的TCP连接,并向Web缓存器中的对象发送一个HTTP请求。
- Web缓存器进行检查,看看本地是否存储了该对象副本。如果没有,Web缓存器就向客户端浏览器用HTTP响应报文返回该对象。
- 如果Web缓存器中没有该对象,它就打开一个与该对象的初始服务器的TCP连接。Web缓存器则在这个缓存器到服务器的TCP连接上发送一个对该对象的HTTP请求。在收到该请求后,初始服务器向该Web缓冲器发送具有该对象的HTTP响应。
- 当Web缓存器接收到该对象时,它在本地存储空间存储一根副本,并向客户的浏览器用HTTP相应报文发送该副本(通过现有的客户端浏览器和Web缓存器之间的TCP连接)。
web缓存器通过使用内容分发网络(Content Distri-bution Network, CDN)实现,CDN公司在因特网上安装了许多地理上分散的缓冲器,因而使大流量实现本地化。
经过上面的过程描述,web缓存器在响应客户端请求时就是一个服务器,而在向初始服务器发送请求时就是一个客户端。这样的网络响应方式肯定是可以很大程度的提高响应效率,具体可以了解(《计算机网络》75页)。但是这样的网络响应就会存在一个问题,怎么确保web缓存的副本是最新的最新的资源呢?什么时候更新web缓存器的副本?
在Web缓存器上,HTTP协议有一种机制,允许缓存器证实它的对象是最新的。这种机制就是get方法,如果请求报文使用get方法,并且请求报文中含有“If-Modified-since:”首部行,那么这个请求报文就是一个条件get请求报文。下面是是一对Web缓存器的HTTP请求和响应报文:
GET /fruit/kiwi.gif HTTP/1.1
Host:www.exotiquecuisine.com
If-Modified-since:web, 7 Sep 2011 09:23:24
//初始服务器响应
HTTP/1.1 304 Not Modified
Date: Sat, 15 Oct 2011 15:39:29
Server: Apache/1.3.0 (Unix) (empty entity body)
三、DNS:因特网的目录服务
DNS( Domain Name System)是“域名系统”的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,它用于TCP/IP网络,它所提供的服务是用来将主机名和域名转换为IP地址的工作。俗话说,DNS就是将网址转化为对外的IP地址。
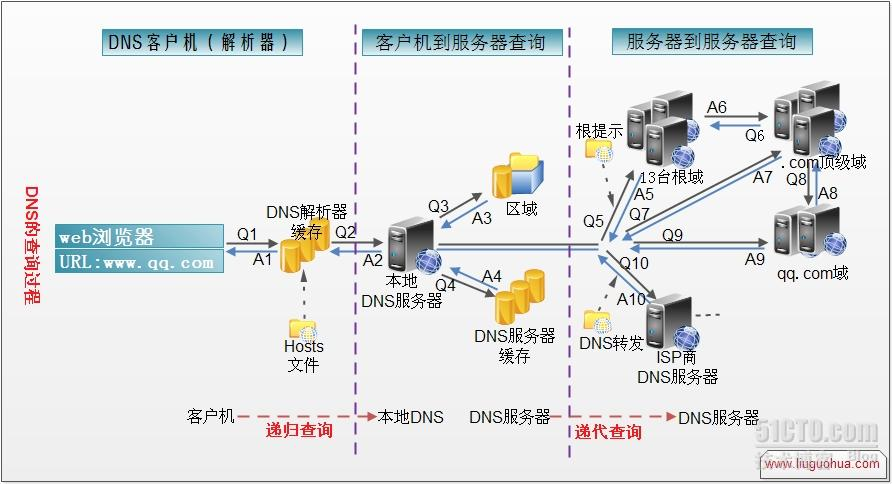
- 第一步:浏览器将会检查缓存中有没有这个域名对应的解析过的IP地址,如果有该解析过程将会结束。浏览器缓存域名也是有限制的,包括缓存的时间、大小,可以通过TTL属性来设置。
- 第二步:如果用户的浏览器中缓存中没有,操作系统会先检查自己本地的hosts文件是否有这个网址映射关系,如果有,就先调用这个IP地址映射,完成域名解析。
- 第三步:如果hosts里没有这个域名的映射,则查找本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析。
- 第四步:如果hosts与本地DNS解析器缓存都没有相应的网址映射关系,首先会找TCP/ip参数中设置的首选DNS服务器,在此我们叫它本地DNS服务器,此服务器收到查询时,如果要查询的域名,包含在本地配置区域资源中,则返回解析结果给客户机,完成域名解析,此解析具有权威性。
- 第五步:如果要查询的域名,不由本地DNS服务器区域解析,但该服务器已缓存了此网址映射关系,则调用这个IP地址映射,完成域名解析,此解析不具有权威性。
- 第六步:如果本地DNS服务器本地区域文件与缓存解析都失效,则根据本地DNS服务器的设置(是否设置转发器)进行查询,如果未用转发模式,本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找域名域服务器,重复上面的动作,进行查询,直至找到域名对应的主机。
- 第七步:如果用的是转发模式,此DNS服务器就会把请求转发至上一级DNS服务器,由上一级服务器进行解析,上一级服务器如果不能解析,或找根DNS或把转请求转至上上级,以此循环。不管是本地DNS服务器用是是转发,还是根提示,最后都是把结果返回给本地DNS服务器,由此DNS服务器再返回给客户机。
这部分直接拷贝别人的了,对于DNS不是三言两语就能解释清楚的,前期学习也不会有太多接触,有机会在重点解析。有兴趣可以先了解一下这篇文章,我这篇博客的DNS部分的内容也是从这里拷贝的。一次DNS缓存引发的惨案
四、运输层/TCP、UDP
一个Web请求经过了HTTP请求到DNS域名解析后就到了向服务器发起正式的资源请求了,HTTP报文经过套字节向网络发送请求报文,这时候就开始基于TCP协议来进行网络运输层的资源交互响应了。
运输层概述
运输层协议为运行在不同主机上的应用进程之间提供逻辑通信,从应用程序的角度看,通过逻辑通信,运行不同进程的主机好像直接连接一样。简单的说就是通过运输层协议将两个不同的主机和不同的进程通过逻辑处理,让它们相互连接进行报文段交付和数据传输。
- 运输层协议是在端系统中而不是在路由器中实现(也就是你的客户主机或者服务器主机)。
- 在发送端,运输层将从发送应用程序进程接收到的报文转换成运输层分组(报文段),实现的方法是将应用报文划分成较小的块,并为每块加上一个运输层首部生成运输层报文段。
- 然后,在发送端系统中,运输层将这些报文段传递给网络层,网络层将其封装成网络层分组(数据报)并向目的地发送。
- 网络路由仅作用于该数据报的网络层字段;即他们不检查封装在数据报的运输层报文段的字段。
- 在接收端,网络层从数据报中提取运输层报文段,并将该报文段向上交给运输层。
- 运输层则处理接收到的报文段,使该报文段中的数据为接收应用进程使用。
整个运输层就是从发送端的进程接收报文然后转换成报文段,然后再将报文段交给网络层发送到目的地,然后接收端的运输层拿到报文段交给对应的应用程序进程。这个过程里面有一个问题值得探讨,就是运输层如何从进程拿到报文,拿到报文后转换成报文段做了什么。接收端的运输层接收到报文段又是如何将报文段交给应用程序进程的。我们知道一台主机会有很多个应用程序进程,运输层如何分辨,将报文段准确无误的交给对应的应用程序进程。这就是我们接下来要介绍的:运输层多路复用与多路分解。
上面我们介绍了运输层是在端系统上进行逻辑处理来实现两个端系统的进程连接,那么就有必要来了解运输层协议到底是如何进行逻辑处理的。
- 运输层的多路复用与多路分解,将两个端系统间IP的交付服务扩展未运行在端系统上的进程交付服务。
- 每个运输层报文段中具有几个字段,在接收端运输层检查这些字段,标识出接收套字节,进而将报文段定向到该套字节,这就是多路分解,也是接收端的运输层逻辑。
- 在源主机(客户主机)从不同套接字中收集数据块,并为每个数据块封装上首部从而生成报文段,然后将报文段传送到网络层,这就是多路复用。
上面的运输层实套接字有些是目的IP地址和目的端口号组成的二元组标识,有些会多包含有源端口IP地址和源端口号的四元组标识,这其中的区别就是下面要解释的无连接和有链接的多路复用和多路分解。
无连接的多路复用与多路分解:UDP套接字是由二元组来标识的,所以UDP是无连接运输协议。
有链接的多路复用与多路分解:CTP套接字是由四元组来表示的,所以CTP是有链接运输协议。
下面是一个TCP运输的Web请求过程:
- TCP服务器应用程序有一个“welcoming socket”,它在12000号端口上等待来自TCP客户的连接建立请求。
- TCP客户使用下面的代码创建一个套接字并发送一个连接建立请求报文段:clientSocket = socket(AF_INET, SOCK_STREAM);clientSocket.connect((serverName,12000))
- 一条连接建立请求只不过是一个目的端口号为12000,TCP首部的特定“连接位置”置位的TCP报文段,这个报文段也包含一个客户选择的源端口号。(后面有具体的解析)
- 当运行服务器进程的计算机的主机操作系统接收到了具有目的端口12000的入连接请求报文段后,它就定位服务器进程,该进程正在端口号12000等待接收连接。该服务器进程创建一个新的套接字:connectionSocket, addr = serverSocket.accept()
- 该服务器的运输层还注意到连接请求报文段中的下列四个值:1.该报文段中的源端口号;2.源主机IP地址;3.该报文段中的目的端口号;4.自身的IP地址。新创建的连接套接字通过这4个值来标识。所有后续到达的报文段,如果他们的源端口号、源主机IP地址、目的端口号和目的IP地址与这4个值匹配,则被分解到这个套字节。随着TCP连接完成,客户和服务器可以开始互相发送数据了。(服务器主机支持很多并行的TCP套接字,每个套接字与一个进程相联系,并由其四元组来标识每个套接字,所有4个资源被用来将报文段定向(分解)到响应的套接字)
无连接的运输:UDP/面向连接的运输:TCP
由于运输层的内部机制和实现原理篇幅不少,而且有非常重要,同时也为了方便以后查阅,特将这部分内容分别独立储出去作为两个博客内容,下面是这两篇博客的连接:
计算机网络Web应用层与运输层(HTTP/TCP)的更多相关文章
- 计算机网络原理和OSI模型与TCP模型
计算机网络原理和OSI模型与TCP模型 一.计算机网络的概述 1.计算机网络的定义 计算机网络是一组自治计算机的互连的集合 2.计算机网络的基本功能 a.资源共享 b.分布式处理与负载均衡 c.综合信 ...
- Web通信协议:OSI、TCP、UDP、Socket、HTTP、HTTPS、TLS、SSL、WebSocket、Stomp
1 各层的位置 1.1 OSI七层模型全景图 OSI是Open System Interconnect的缩写,意为开放式系统互联. 1.2 五层网络协议 在七层的基础上, ...
- 运输层和TCP/IP协议
0. 基本要点 运输层是为相互通信的应用进程提供逻辑通信. 端口和套接字的意义 什么是无连接UDP 什么是面向连接的TCP 在不可靠的网络上实现可靠传输的工作原理,停止等待协议和ARQ协议 TCP的滑 ...
- 运输层5——TCP报文段的首部格式
写在前面:本文章是针对<计算机网络第七版>的学习笔记 运输层1--运输层协议概述 运输层2--用户数据报协议UDP 运输层3--传输控制协议TCP概述 运输层4--TCP可靠运输的工作原理 ...
- 运输层8——TCP运输连接管理
目录 1. TCP的连接建立 2. TCP的连接释放 写在前面:本文章是针对<计算机网络第七版>的学习笔记 运输层1--运输层协议概述 运输层2--用户数据报协议UDP 运输层3--传输控 ...
- 运输层7——TCP的流量控制和拥塞控制
目录 1. TCP的流量控制 2. TCP的拥塞控制 写在前面:本文章是针对<计算机网络第七版>的学习笔记 运输层1--运输层协议概述 运输层2--用户数据报协议UDP 运输层3--传输控 ...
- 运输层6——TCP可靠传输的实现
目录 1. 以字节为单位的滑动窗口 2. 超时重传时间的选择 写在前面:本文章是针对<计算机网络第七版>的学习笔记 运输层1--运输层协议概述 运输层2--用户数据报协议UDP 运输层3- ...
- 运输层4——TCP可靠运输的工作原理
目录 1. 停止等待协议 写在前面:本文章是针对<计算机网络第七版>的学习笔记 运输层1--运输层协议概述 运输层2--用户数据报协议UDP 运输层3--传输控制协议TCP概述 运输层4- ...
- 运输层协议TCP和UDP
运输层协议TCP和UDP 一.用户数据报协议 UDP 1.1.UDP 概述 UDP 只在 IP 的数据报服务之上增加了很少一点的功能,即端口的功能和差错检测的功能. 虽然 UDP 用户数据报只能提供不 ...
随机推荐
- 读书笔记之_Win10 与Jmeter5.1.1界面兼容:
读书笔记之win10 与jmeter5.1.1界面兼容: 调整前:
- Delphi 数据转换
指针转换 Pointer——string string:=PChar(Pointer);{ Pointer指向的数据要以#0结尾.使用System.AllocMem(Size)分配的内存是用#0填 ...
- 基于IPv6的数据包分析(第三组)
一.实验拓扑 二.配置过程 本处提供R1.R2.R4的详细配置过程(包含静态路由的配置) 1) R1: R1(config)#int e1/0 R1(config-if)#ipv6 addr ...
- leetcode 54. Spiral Matrix 、59. Spiral Matrix II
54题是把二维数组安卓螺旋的顺序进行打印,59题是把1到n平方的数字按照螺旋的顺序进行放置 54. Spiral Matrix start表示的是每次一圈的开始,每次开始其实就是从(0,0).(1,1 ...
- 微信内分享第三方H5链接无法使用内置浏览器打开的解决方案
很多朋友在微信内想分享转发H5链接的时候都会很容易碰到H5链接在微信内无法打开或在微信内无法打开app下载页的情况.通常这种情况微信会给个提示 “已停止访问该网址” ,那么导致这个情况的因素有哪些呢, ...
- CentOS 安装 Ansible 以及连接Windows server的办法
1. CentOS机器上面按住那ansible yum install ansible 2. 安装 pywinrm 如果不安装 这个的话 ansible 会提示 没有 winrm 模块 注意需要先 ...
- 深入理解SpringIOC容器
转载来源:[https://www.cnblogs.com/fingerboy/p/5425813.html] 前言: 在逛博客园的时候突然发现一篇关于事务的好文章,说起spring事物就离不开AOP ...
- MyBatis 3源码解析(三)
三.getMapper获取接口的代理对象 1.先调用DefaultSqlSession的getMapper方法.代码如下: @Override public <T> T getMapper ...
- git异常操作解决办法合集
1. git add .后发现提交错误,想撤销 git reset head 文件名-----撤销某个文件 git reset head --hard 强制撤销当前的所有操作到上次提交的版本 2. g ...
- C#入门教程源码
C#入门教程源码 [日期:2019-01-26] 来源:51zxw.net 作者:zhangguofu [字体:大 中 小] 方法一:百度云盘下载地址: 链接:https://pan.baidu.c ...